diff --git a/README.md b/README.md
index 6779a69e..df299e02 100644
--- a/README.md
+++ b/README.md
@@ -13,7 +13,7 @@
-

+

+
## 解题思路
如果使用递归求解,会重复计算一些子问题。例如,计算 f(4) 需要计算 f(3) 和 f(2),计算 f(3) 需要计算 f(2) 和 f(1),可以看到 f(2) 被重复计算了。
-
+
递归是将一个问题划分成多个子问题求解,动态规划也是如此,但是动态规划会把子问题的解缓存起来,从而避免重复求解子问题。
diff --git a/docs/notes/10.2 矩形覆盖.md b/docs/notes/10.2 矩形覆盖.md
index ecc7a646..2bd056c1 100644
--- a/docs/notes/10.2 矩形覆盖.md
+++ b/docs/notes/10.2 矩形覆盖.md
@@ -8,23 +8,23 @@
我们可以用 2\*1 的小矩形横着或者竖着去覆盖更大的矩形。请问用 n 个 2\*1 的小矩形无重叠地覆盖一个 2\*n 的大矩形,总共有多少种方法?
-
+
## 解题思路
当 n 为 1 时,只有一种覆盖方法:
-
+
当 n 为 2 时,有两种覆盖方法:
-
+
要覆盖 2\*n 的大矩形,可以先覆盖 2\*1 的矩形,再覆盖 2\*(n-1) 的矩形;或者先覆盖 2\*2 的矩形,再覆盖 2\*(n-2) 的矩形。而覆盖 2\*(n-1) 和 2\*(n-2) 的矩形可以看成子问题。该问题的递推公式如下:
-
+
```java
public int RectCover(int n) {
diff --git a/docs/notes/10.3 跳台阶.md b/docs/notes/10.3 跳台阶.md
index bd89c6fd..3db7579d 100644
--- a/docs/notes/10.3 跳台阶.md
+++ b/docs/notes/10.3 跳台阶.md
@@ -8,21 +8,21 @@
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
-
+
## 解题思路
当 n = 1 时,只有一种跳法:
-
+
当 n = 2 时,有两种跳法:
-
+
跳 n 阶台阶,可以先跳 1 阶台阶,再跳 n-1 阶台阶;或者先跳 2 阶台阶,再跳 n-2 阶台阶。而 n-1 和 n-2 阶台阶的跳法可以看成子问题,该问题的递推公式为:
-
+
```java
public int JumpFloor(int n) {
diff --git a/docs/notes/10.4 变态跳台阶.md b/docs/notes/10.4 变态跳台阶.md
index 0e779d00..760ff568 100644
--- a/docs/notes/10.4 变态跳台阶.md
+++ b/docs/notes/10.4 变态跳台阶.md
@@ -8,7 +8,7 @@
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级... 它也可以跳上 n 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
-
+
## 解题思路
diff --git a/docs/notes/11. 旋转数组的最小数字.md b/docs/notes/11. 旋转数组的最小数字.md
index ca34fed5..be409669 100644
--- a/docs/notes/11. 旋转数组的最小数字.md
+++ b/docs/notes/11. 旋转数组的最小数字.md
@@ -6,13 +6,13 @@
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。
-
+
## 解题思路
将旋转数组对半分可以得到一个包含最小元素的新旋转数组,以及一个非递减排序的数组。新的旋转数组的数组元素是原数组的一半,从而将问题规模减少了一半,这种折半性质的算法的时间复杂度为 O(logN)(为了方便,这里将 log2N 写为 logN)。
-
+
此时问题的关键在于确定对半分得到的两个数组哪一个是旋转数组,哪一个是非递减数组。我们很容易知道非递减数组的第一个元素一定小于等于最后一个元素。
diff --git a/docs/notes/12. 矩阵中的路径.md b/docs/notes/12. 矩阵中的路径.md
index 217f5696..43631319 100644
--- a/docs/notes/12. 矩阵中的路径.md
+++ b/docs/notes/12. 矩阵中的路径.md
@@ -8,13 +8,13 @@
例如下面的矩阵包含了一条 bfce 路径。
-
+
## 解题思路
使用回溯法(backtracking)进行求解,它是一种暴力搜索方法,通过搜索所有可能的结果来求解问题。回溯法在一次搜索结束时需要进行回溯(回退),将这一次搜索过程中设置的状态进行清除,从而开始一次新的搜索过程。例如下图示例中,从 f 开始,下一步有 4 种搜索可能,如果先搜索 b,需要将 b 标记为已经使用,防止重复使用。在这一次搜索结束之后,需要将 b 的已经使用状态清除,并搜索 c。
-
+
本题的输入是数组而不是矩阵(二维数组),因此需要先将数组转换成矩阵。
diff --git a/docs/notes/16. 数值的整数次方.md b/docs/notes/16. 数值的整数次方.md
index 1cddc018..207b235f 100644
--- a/docs/notes/16. 数值的整数次方.md
+++ b/docs/notes/16. 数值的整数次方.md
@@ -12,7 +12,7 @@
-
+
因为 (x\*x)n/2 可以通过递归求解,并且每次递归 n 都减小一半,因此整个算法的时间复杂度为 O(logN)。
diff --git a/docs/notes/18.1 在 O(1) 时间内删除链表节点.md b/docs/notes/18.1 在 O(1) 时间内删除链表节点.md
index 8cd0a5ee..f14a83f9 100644
--- a/docs/notes/18.1 在 O(1) 时间内删除链表节点.md
+++ b/docs/notes/18.1 在 O(1) 时间内删除链表节点.md
@@ -4,11 +4,11 @@
① 如果该节点不是尾节点,那么可以直接将下一个节点的值赋给该节点,然后令该节点指向下下个节点,再删除下一个节点,时间复杂度为 O(1)。
- 
+ 
② 否则,就需要先遍历链表,找到节点的前一个节点,然后让前一个节点指向 null,时间复杂度为 O(N)。
- 
+ 
综上,如果进行 N 次操作,那么大约需要操作节点的次数为 N-1+N=2N-1,其中 N-1 表示 N-1 个不是尾节点的每个节点以 O(1) 的时间复杂度操作节点的总次数,N 表示 1 个尾节点以 O(N) 的时间复杂度操作节点的总次数。(2N-1)/N \~ 2,因此该算法的平均时间复杂度为 O(1)。
diff --git a/docs/notes/18.2 删除链表中重复的结点.md b/docs/notes/18.2 删除链表中重复的结点.md
index 555a0754..b7ba929a 100644
--- a/docs/notes/18.2 删除链表中重复的结点.md
+++ b/docs/notes/18.2 删除链表中重复的结点.md
@@ -4,7 +4,7 @@
## 题目描述
- 
+ 
## 解题描述
diff --git a/docs/notes/21. 调整数组顺序使奇数位于偶数前面.md b/docs/notes/21. 调整数组顺序使奇数位于偶数前面.md
index f6b91323..7bfed614 100644
--- a/docs/notes/21. 调整数组顺序使奇数位于偶数前面.md
+++ b/docs/notes/21. 调整数组顺序使奇数位于偶数前面.md
@@ -6,7 +6,7 @@
需要保证奇数和奇数,偶数和偶数之间的相对位置不变,这和书本不太一样。
- 
+ 
## 解题思路
diff --git a/docs/notes/22. 链表中倒数第 K 个结点.md b/docs/notes/22. 链表中倒数第 K 个结点.md
index 209dc0e9..3a6226f9 100644
--- a/docs/notes/22. 链表中倒数第 K 个结点.md
+++ b/docs/notes/22. 链表中倒数第 K 个结点.md
@@ -6,7 +6,7 @@
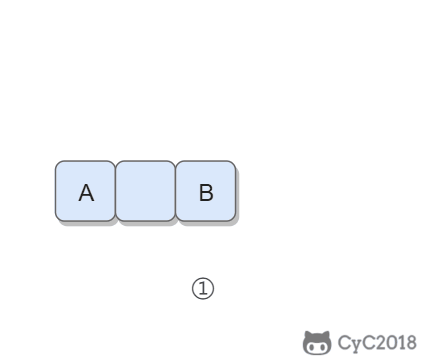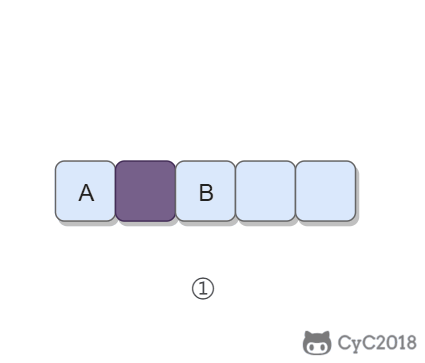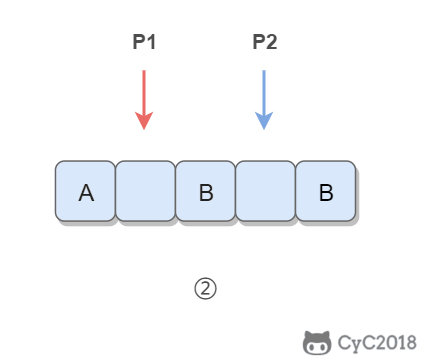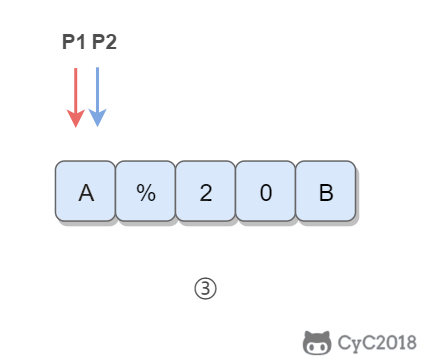
设链表的长度为 N。设置两个指针 P1 和 P2,先让 P1 移动 K 个节点,则还有 N - K 个节点可以移动。此时让 P1 和 P2 同时移动,可以知道当 P1 移动到链表结尾时,P2 移动到第 N - K 个节点处,该位置就是倒数第 K 个节点。
- 
+ 
```java
public ListNode FindKthToTail(ListNode head, int k) {
diff --git a/docs/notes/23. 链表中环的入口结点.md b/docs/notes/23. 链表中环的入口结点.md
index aea40f9a..ec565894 100644
--- a/docs/notes/23. 链表中环的入口结点.md
+++ b/docs/notes/23. 链表中环的入口结点.md
@@ -22,7 +22,7 @@
上面的等值没有很强的规律,但是我们可以发现 y+z 就是圆环的总长度,因此我们将上面的等式再分解:x=(N-2)(y+z)+z。这个等式左边是从起点x1 到环入口节点 y1 的长度,而右边是在圆环中走过 (N-2) 圈,再从相遇点 z1 再走过长度为 z 的长度。此时我们可以发现如果让两个指针同时从起点 x1 和相遇点 z1 开始,每次只走过一个距离,那么最后他们会在环入口节点相遇。
- 
+ 
```java
public ListNode EntryNodeOfLoop(ListNode pHead) {
diff --git a/docs/notes/25. 合并两个排序的链表.md b/docs/notes/25. 合并两个排序的链表.md
index b3b5b4df..37b6e2f9 100644
--- a/docs/notes/25. 合并两个排序的链表.md
+++ b/docs/notes/25. 合并两个排序的链表.md
@@ -4,7 +4,7 @@
## 题目描述
- 
+ 
## 解题思路
diff --git a/docs/notes/26. 树的子结构.md b/docs/notes/26. 树的子结构.md
index 7fd34ab3..e4772db9 100644
--- a/docs/notes/26. 树的子结构.md
+++ b/docs/notes/26. 树的子结构.md
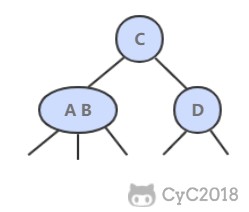
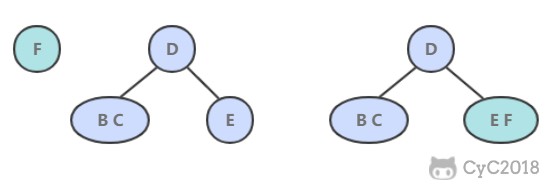
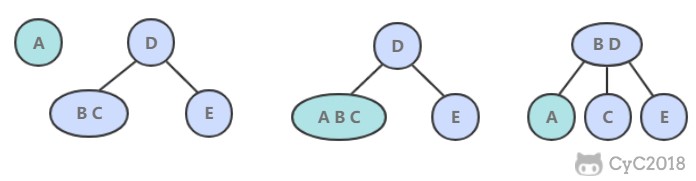
@@ -4,7 +4,7 @@
## 题目描述
- 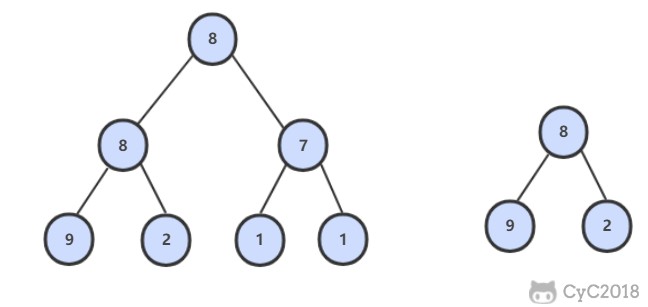
+ 
## 解题思路
diff --git a/docs/notes/27. 二叉树的镜像.md b/docs/notes/27. 二叉树的镜像.md
index abe1c395..4d137e2c 100644
--- a/docs/notes/27. 二叉树的镜像.md
+++ b/docs/notes/27. 二叉树的镜像.md
@@ -4,7 +4,7 @@
## 题目描述
- 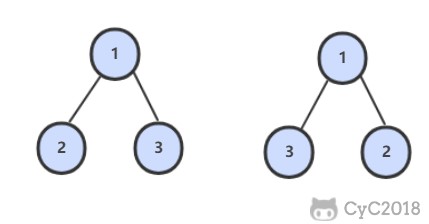
+ 
## 解题思路
diff --git a/docs/notes/28. 对称的二叉树.md b/docs/notes/28. 对称的二叉树.md
index 94d658aa..80f49f57 100644
--- a/docs/notes/28. 对称的二叉树.md
+++ b/docs/notes/28. 对称的二叉树.md
@@ -4,7 +4,7 @@
## 题目描述
-
+
## 解题思路
diff --git a/docs/notes/29. 顺时针打印矩阵.md b/docs/notes/29. 顺时针打印矩阵.md
index 1d5435d8..32636dd8 100644
--- a/docs/notes/29. 顺时针打印矩阵.md
+++ b/docs/notes/29. 顺时针打印矩阵.md
@@ -6,7 +6,7 @@
下图的矩阵顺时针打印结果为:1, 2, 3, 4, 8, 12, 16, 15, 14, 13, 9, 5, 6, 7, 11, 10
- 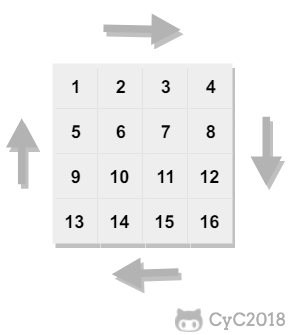
+ 
## 解题思路
diff --git a/docs/notes/3. 数组中重复的数字.md b/docs/notes/3. 数组中重复的数字.md
index d249e72b..4d0031d6 100644
--- a/docs/notes/3. 数组中重复的数字.md
+++ b/docs/notes/3. 数组中重复的数字.md
@@ -24,7 +24,7 @@ Output:
以 (2, 3, 1, 0, 2, 5) 为例,遍历到位置 4 时,该位置上的数为 2,但是第 2 个位置上已经有一个 2 的值了,因此可以知道 2 重复:
- 
+ 
```java
diff --git a/docs/notes/32.1 从上往下打印二叉树.md b/docs/notes/32.1 从上往下打印二叉树.md
index 6c963b15..4f9714e2 100644
--- a/docs/notes/32.1 从上往下打印二叉树.md
+++ b/docs/notes/32.1 从上往下打印二叉树.md
@@ -8,7 +8,7 @@
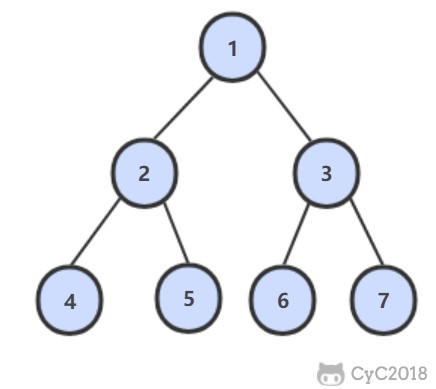
例如,以下二叉树层次遍历的结果为:1,2,3,4,5,6,7
- 
+ 
## 解题思路
diff --git a/docs/notes/33. 二叉搜索树的后序遍历序列.md b/docs/notes/33. 二叉搜索树的后序遍历序列.md
index 6741f31e..bc9ca61c 100644
--- a/docs/notes/33. 二叉搜索树的后序遍历序列.md
+++ b/docs/notes/33. 二叉搜索树的后序遍历序列.md
@@ -8,7 +8,7 @@
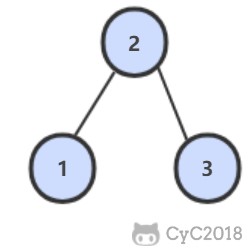
例如,下图是后序遍历序列 1,3,2 所对应的二叉搜索树。
- 
+ 
## 解题思路
diff --git a/docs/notes/34. 二叉树中和为某一值的路径.md b/docs/notes/34. 二叉树中和为某一值的路径.md
index 95629ac4..2304a254 100644
--- a/docs/notes/34. 二叉树中和为某一值的路径.md
+++ b/docs/notes/34. 二叉树中和为某一值的路径.md
@@ -8,7 +8,7 @@
下图的二叉树有两条和为 22 的路径:10, 5, 7 和 10, 12
- 
+ 
## 解题思路
diff --git a/docs/notes/35. 复杂链表的复制.md b/docs/notes/35. 复杂链表的复制.md
index 1f382d6b..908c90c3 100644
--- a/docs/notes/35. 复杂链表的复制.md
+++ b/docs/notes/35. 复杂链表的复制.md
@@ -18,21 +18,21 @@ public class RandomListNode {
}
```
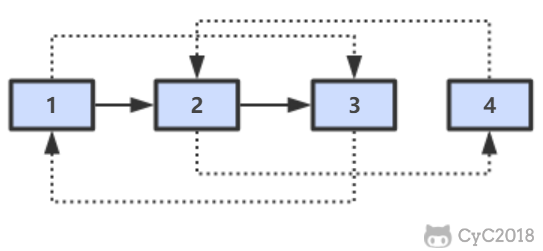
- 
+ 
## 解题思路
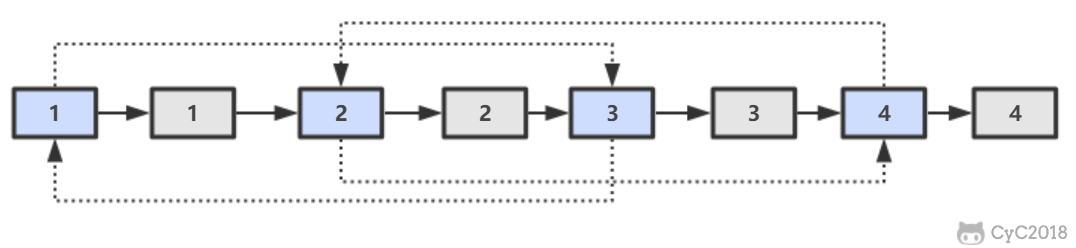
第一步,在每个节点的后面插入复制的节点。
- 
+ 
第二步,对复制节点的 random 链接进行赋值。
- 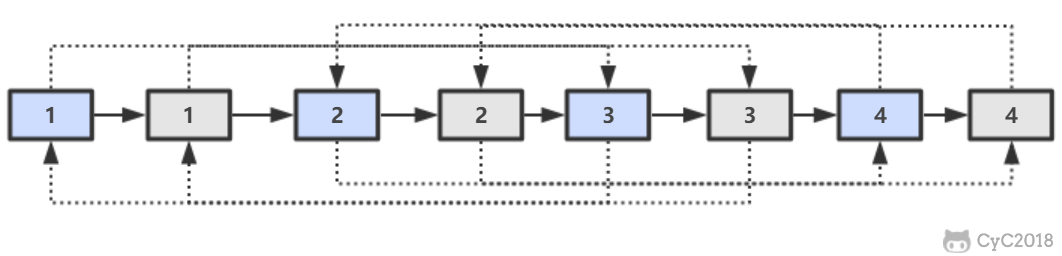
+ 
第三步,拆分。
- 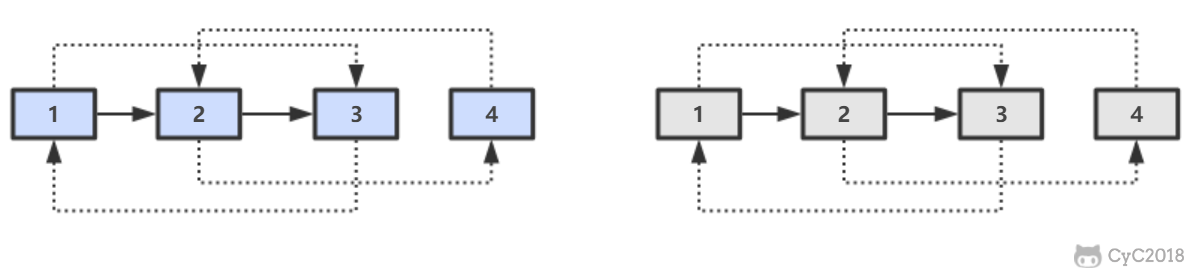
+ 
```java
public RandomListNode Clone(RandomListNode pHead) {
diff --git a/docs/notes/36. 二叉搜索树与双向链表.md b/docs/notes/36. 二叉搜索树与双向链表.md
index 5ab2372a..b68fba14 100644
--- a/docs/notes/36. 二叉搜索树与双向链表.md
+++ b/docs/notes/36. 二叉搜索树与双向链表.md
@@ -6,7 +6,7 @@
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。
- 
+ 
## 解题思路
diff --git a/docs/notes/4. 二维数组中的查找.md b/docs/notes/4. 二维数组中的查找.md
index ff28bd87..9f567a5b 100644
--- a/docs/notes/4. 二维数组中的查找.md
+++ b/docs/notes/4. 二维数组中的查找.md
@@ -28,7 +28,7 @@ Given target = 20, return false.
该二维数组中的一个数,小于它的数一定在其左边,大于它的数一定在其下边。因此,从右上角开始查找,就可以根据 target 和当前元素的大小关系来缩小查找区间,当前元素的查找区间为左下角的所有元素。
- 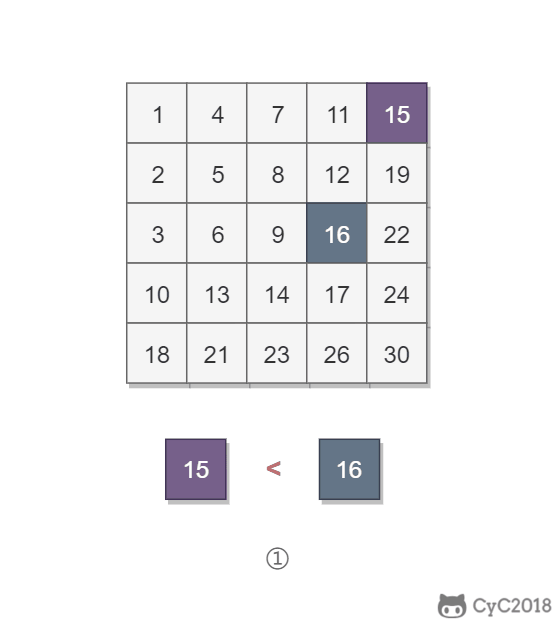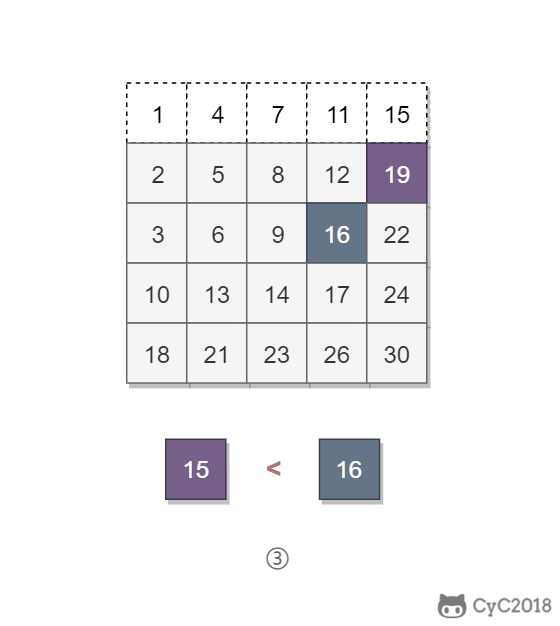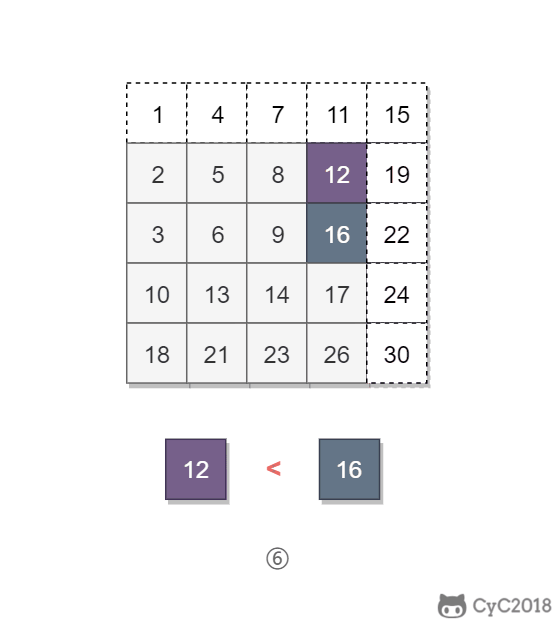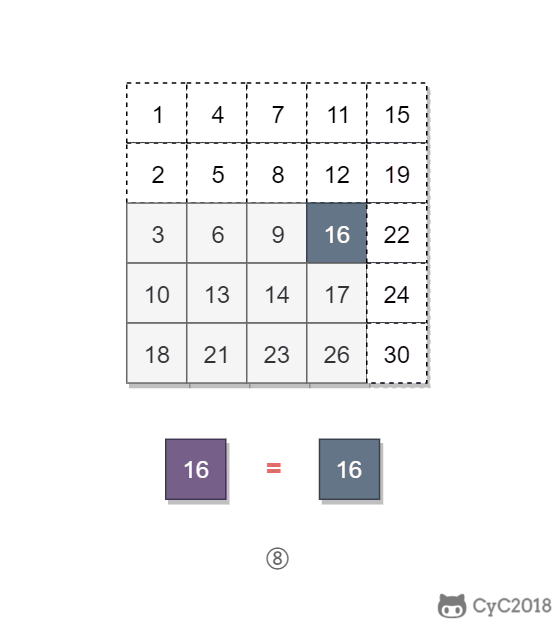
+ 
```java
public boolean Find(int target, int[][] matrix) {
diff --git a/docs/notes/5. 替换空格.md b/docs/notes/5. 替换空格.md
index efe83db6..452652e9 100644
--- a/docs/notes/5. 替换空格.md
+++ b/docs/notes/5. 替换空格.md
@@ -27,7 +27,7 @@ Output:
- 
+ 
```java
public String replaceSpace(StringBuffer str) {
diff --git a/docs/notes/52. 两个链表的第一个公共结点.md b/docs/notes/52. 两个链表的第一个公共结点.md
index 371e8341..b7e0cbdc 100644
--- a/docs/notes/52. 两个链表的第一个公共结点.md
+++ b/docs/notes/52. 两个链表的第一个公共结点.md
@@ -4,7 +4,7 @@
## 题目描述
- 
+ 
## 解题思路
diff --git a/docs/notes/55.1 二叉树的深度.md b/docs/notes/55.1 二叉树的深度.md
index 0aeb411e..8c49c2dc 100644
--- a/docs/notes/55.1 二叉树的深度.md
+++ b/docs/notes/55.1 二叉树的深度.md
@@ -6,7 +6,7 @@
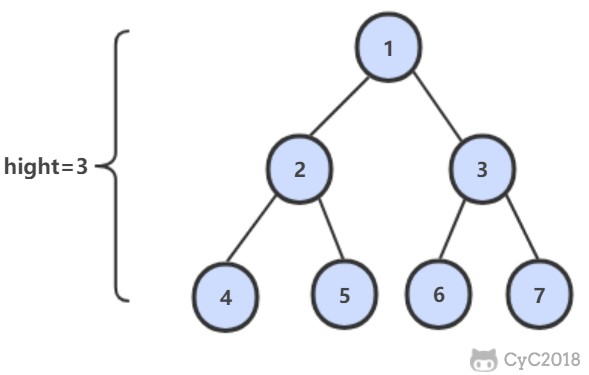
从根结点到叶结点依次经过的结点(含根、叶结点)形成树的一条路径,最长路径的长度为树的深度。
- 
+ 
## 解题思路
diff --git a/docs/notes/55.2 平衡二叉树.md b/docs/notes/55.2 平衡二叉树.md
index d2cdf538..56f8797f 100644
--- a/docs/notes/55.2 平衡二叉树.md
+++ b/docs/notes/55.2 平衡二叉树.md
@@ -6,7 +6,7 @@
平衡二叉树左右子树高度差不超过 1。
- 
+ 
## 解题思路
diff --git a/docs/notes/6. 从尾到头打印链表.md b/docs/notes/6. 从尾到头打印链表.md
index fb78ed03..d7bbb3b0 100644
--- a/docs/notes/6. 从尾到头打印链表.md
+++ b/docs/notes/6. 从尾到头打印链表.md
@@ -8,7 +8,7 @@
从尾到头反过来打印出每个结点的值。
- 
+ 
## 解题思路
@@ -39,13 +39,13 @@ node2.next = node3;
node1.next = node2;
```
- 
+ 
为了能将一个节点插入头部,我们引入了一个叫头结点的辅助节点,该节点不存储值,只是为了方便进行插入操作。不要将头结点与第一个节点混起来,第一个节点是链表中第一个真正存储值的节点。
- 
+ 
```java
public ArrayList printListFromTailToHead(ListNode listNode) {
@@ -72,7 +72,7 @@ public ArrayList printListFromTailToHead(ListNode listNode) {
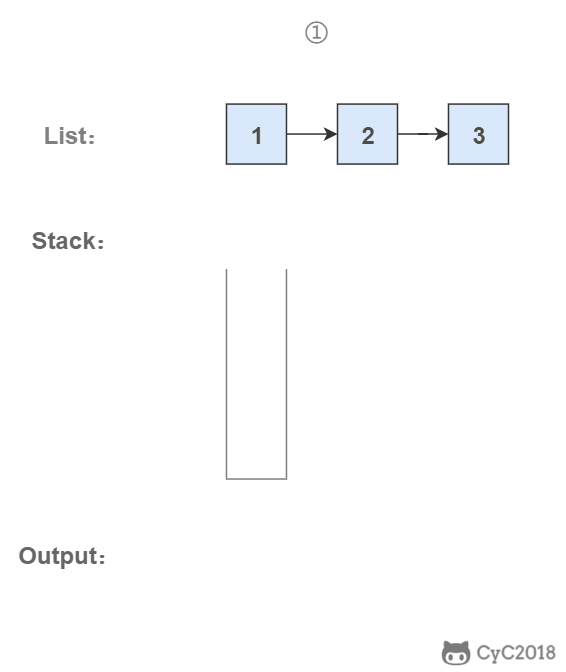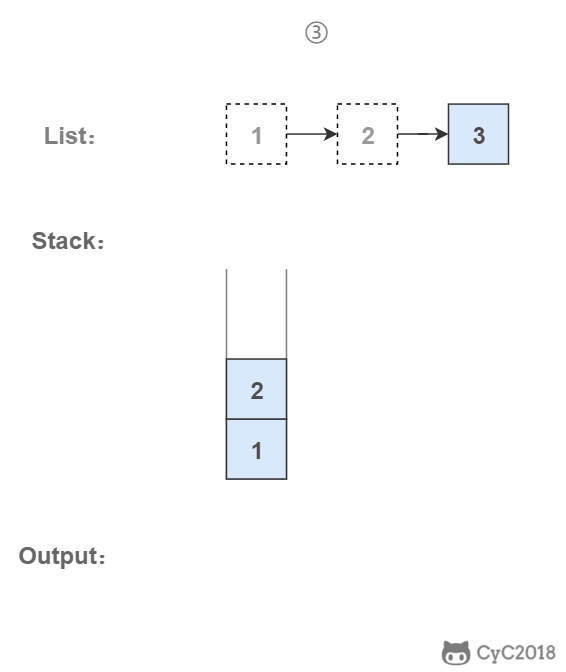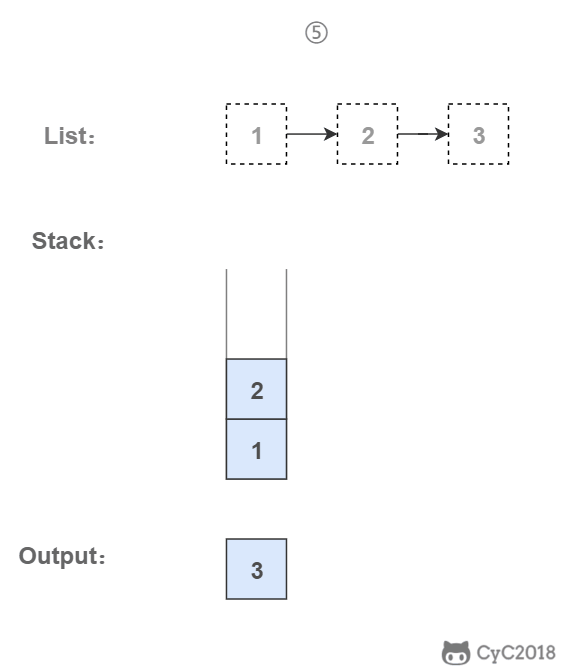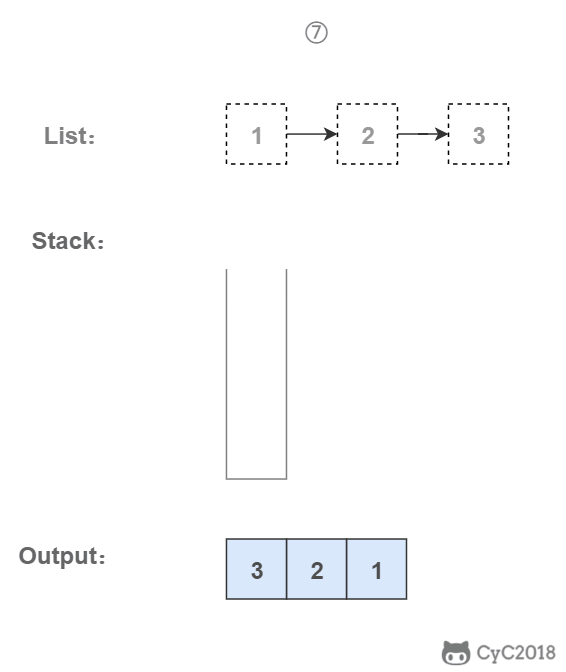
栈具有后进先出的特点,在遍历链表时将值按顺序放入栈中,最后出栈的顺序即为逆序。
- 
+ 
```java
public ArrayList printListFromTailToHead(ListNode listNode) {
diff --git a/docs/notes/60. n 个骰子的点数.md b/docs/notes/60. n 个骰子的点数.md
index d298cc9a..aaa42b66 100644
--- a/docs/notes/60. n 个骰子的点数.md
+++ b/docs/notes/60. n 个骰子的点数.md
@@ -8,7 +8,7 @@
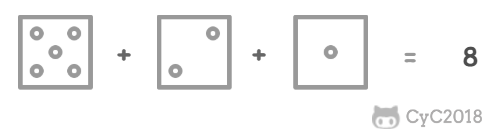
把 n 个骰子扔在地上,求点数和为 s 的概率。
- 
+ 
## 解题思路
diff --git a/docs/notes/61. 扑克牌顺子.md b/docs/notes/61. 扑克牌顺子.md
index 9fde275c..d71becc9 100644
--- a/docs/notes/61. 扑克牌顺子.md
+++ b/docs/notes/61. 扑克牌顺子.md
@@ -8,7 +8,7 @@
五张牌,其中大小鬼为癞子,牌面为 0。判断这五张牌是否能组成顺子。
- 
+ 
## 解题思路
diff --git a/docs/notes/63. 股票的最大利润.md b/docs/notes/63. 股票的最大利润.md
index 499319a5..a467388d 100644
--- a/docs/notes/63. 股票的最大利润.md
+++ b/docs/notes/63. 股票的最大利润.md
@@ -8,7 +8,7 @@
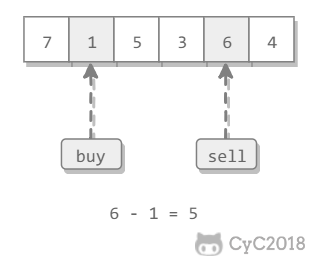
可以有一次买入和一次卖出,买入必须在前。求最大收益。
- 
+ 
## 解题思路
diff --git a/docs/notes/66. 构建乘积数组.md b/docs/notes/66. 构建乘积数组.md
index 8317ca2a..4829a10f 100644
--- a/docs/notes/66. 构建乘积数组.md
+++ b/docs/notes/66. 构建乘积数组.md
@@ -8,7 +8,7 @@
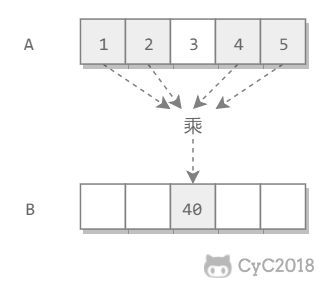
给定一个数组 A[0, 1,..., n-1],请构建一个数组 B[0, 1,..., n-1],其中 B 中的元素 B[i]=A[0]\*A[1]\*...\*A[i-1]\*A[i+1]\*...\*A[n-1]。要求不能使用除法。
- 
+ 
## 解题思路
diff --git a/docs/notes/68. 树中两个节点的最低公共祖先.md b/docs/notes/68. 树中两个节点的最低公共祖先.md
index e77c9665..c31d4348 100644
--- a/docs/notes/68. 树中两个节点的最低公共祖先.md
+++ b/docs/notes/68. 树中两个节点的最低公共祖先.md
@@ -11,7 +11,7 @@
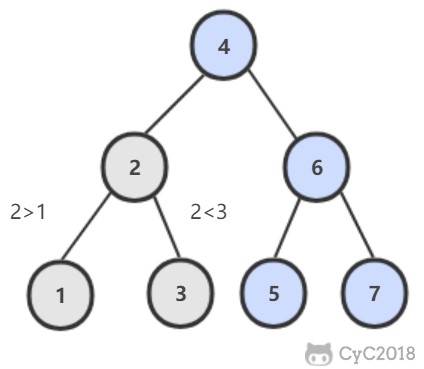
在二叉查找树中,两个节点 p, q 的公共祖先 root 满足 root.val >= p.val && root.val <= q.val。
- 
+ 
```java
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
@@ -35,7 +35,7 @@ public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
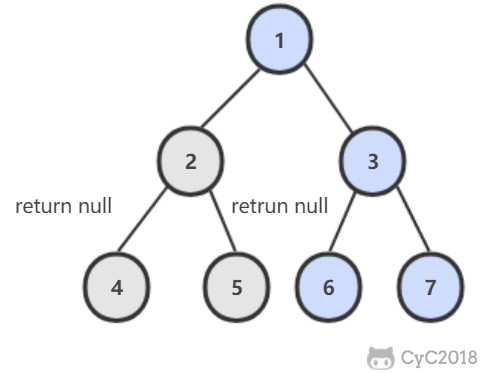
在左右子树中查找是否存在 p 或者 q,如果 p 和 q 分别在两个子树中,那么就说明根节点就是最低公共祖先。
- 
+ 
```java
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
diff --git a/docs/notes/7. 重建二叉树.md b/docs/notes/7. 重建二叉树.md
index b557ea0b..ff82f2aa 100644
--- a/docs/notes/7. 重建二叉树.md
+++ b/docs/notes/7. 重建二叉树.md
@@ -10,13 +10,13 @@
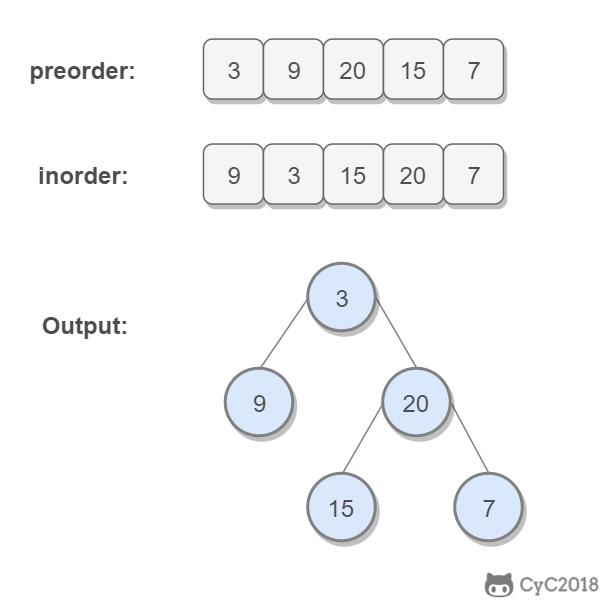
- 
+ 
## 解题思路
前序遍历的第一个值为根节点的值,使用这个值将中序遍历结果分成两部分,左部分为树的左子树中序遍历结果,右部分为树的右子树中序遍历的结果。然后分别对左右子树递归地求解。
- 
+ 
```java
// 缓存中序遍历数组每个值对应的索引
diff --git a/docs/notes/8. 二叉树的下一个结点.md b/docs/notes/8. 二叉树的下一个结点.md
index 38d26414..92bfe9a9 100644
--- a/docs/notes/8. 二叉树的下一个结点.md
+++ b/docs/notes/8. 二叉树的下一个结点.md
@@ -35,17 +35,17 @@ void traverse(TreeNode root) {
}
```
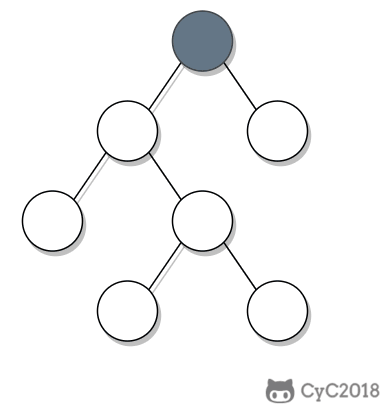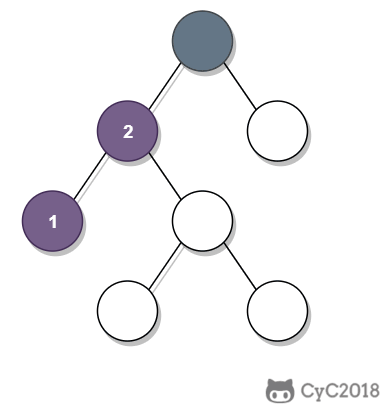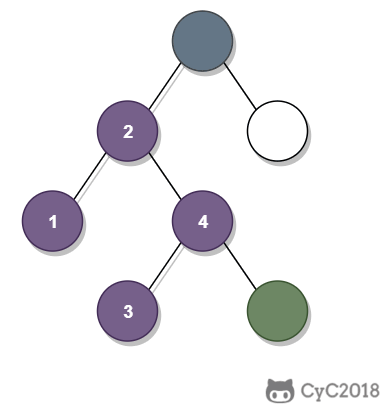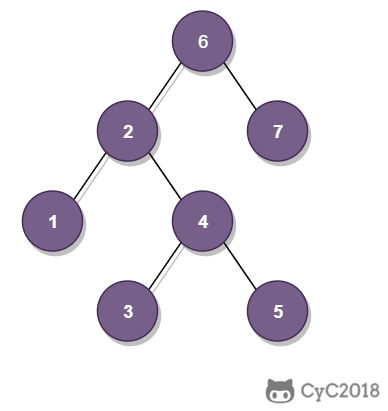
- 
+ 
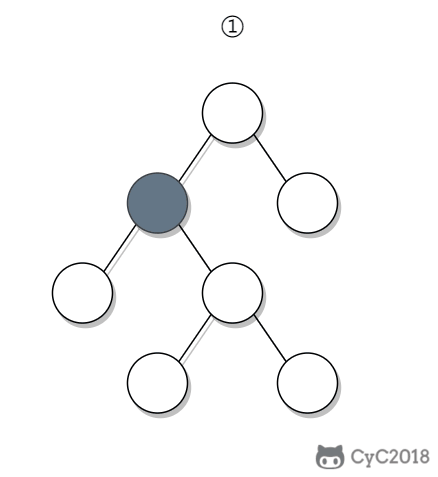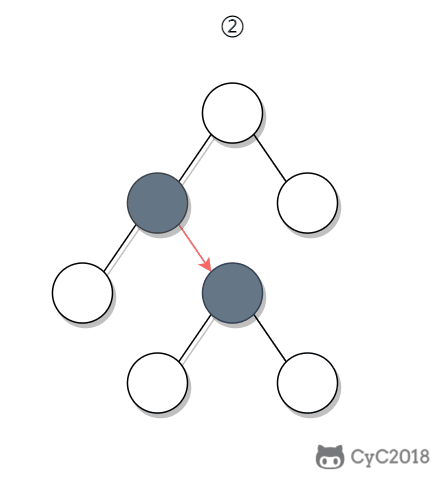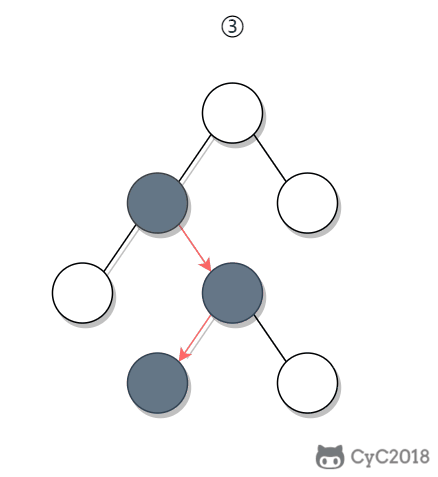
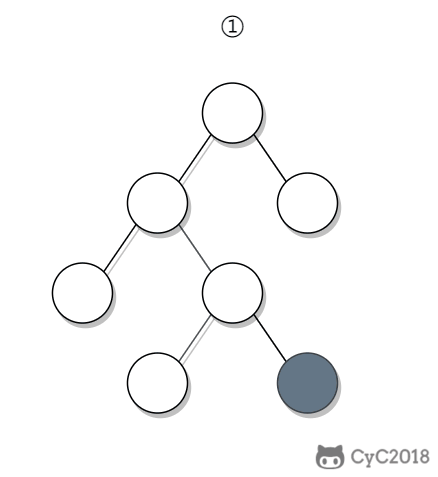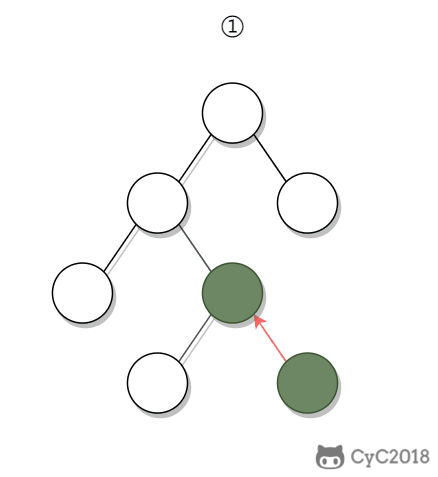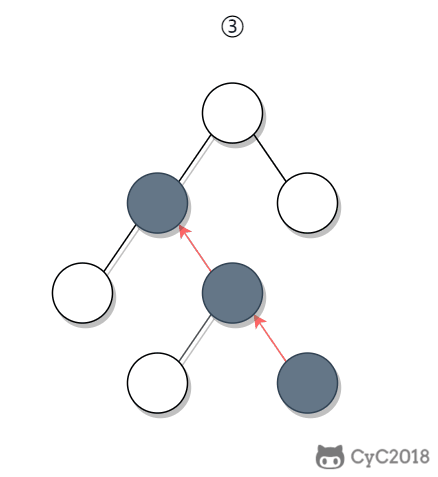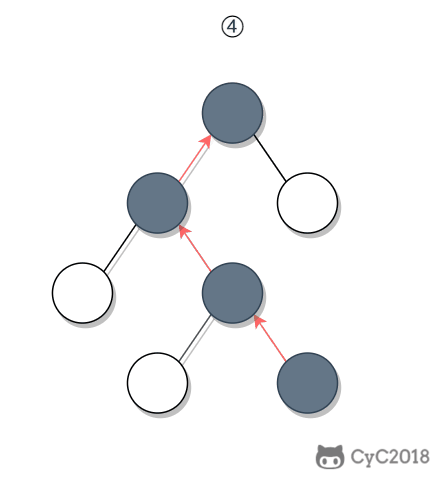
① 如果一个节点的右子树不为空,那么该节点的下一个节点是右子树的最左节点;
- 
+ 
② 否则,向上找第一个左链接指向的树包含该节点的祖先节点。
- 
+ 
```java
public TreeLinkNode GetNext(TreeLinkNode pNode) {
diff --git a/docs/notes/9. 用两个栈实现队列.md b/docs/notes/9. 用两个栈实现队列.md
index 7d1f24ec..bf9fd343 100644
--- a/docs/notes/9. 用两个栈实现队列.md
+++ b/docs/notes/9. 用两个栈实现队列.md
@@ -12,7 +12,7 @@
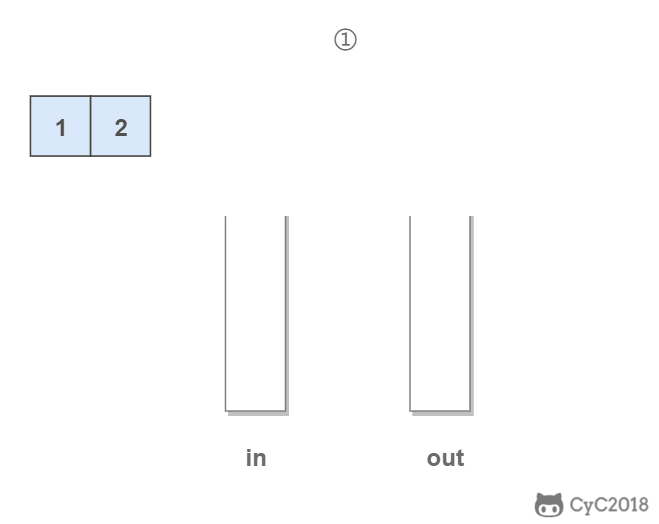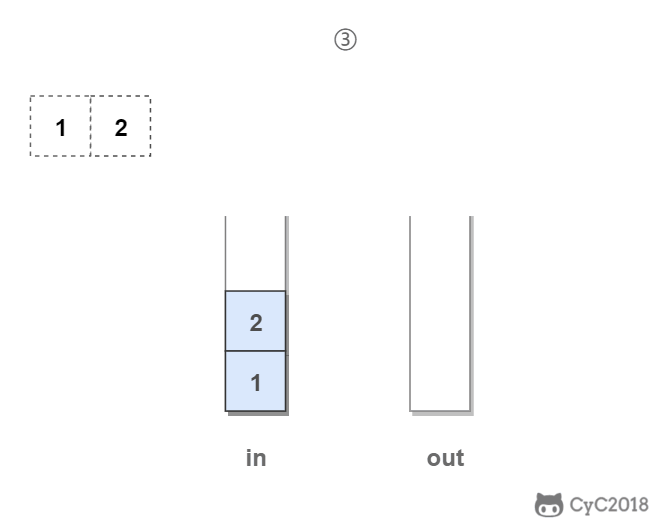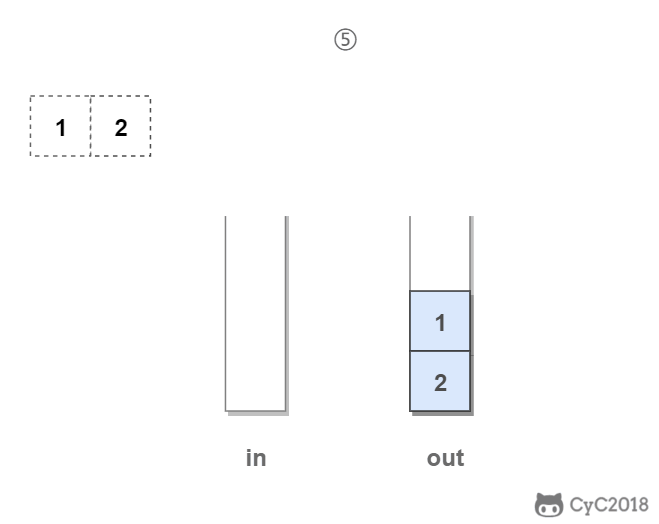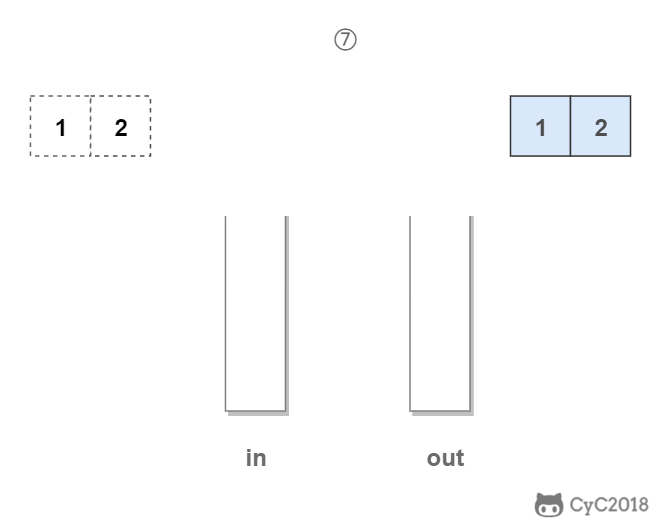
in 栈用来处理入栈(push)操作,out 栈用来处理出栈(pop)操作。一个元素进入 in 栈之后,出栈的顺序被反转。当元素要出栈时,需要先进入 out 栈,此时元素出栈顺序再一次被反转,因此出栈顺序就和最开始入栈顺序是相同的,先进入的元素先退出,这就是队列的顺序。
- 
+ 
```java
Stack in = new Stack();
diff --git a/docs/notes/Docker.md b/docs/notes/Docker.md
index 7647d26c..3df19303 100644
--- a/docs/notes/Docker.md
+++ b/docs/notes/Docker.md
@@ -14,13 +14,13 @@
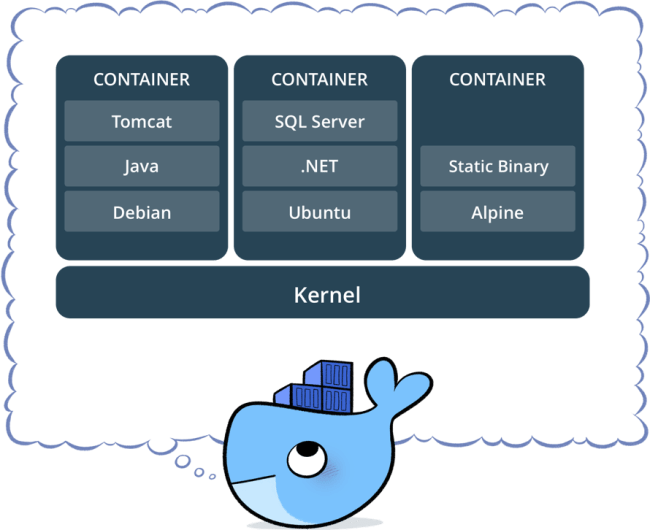
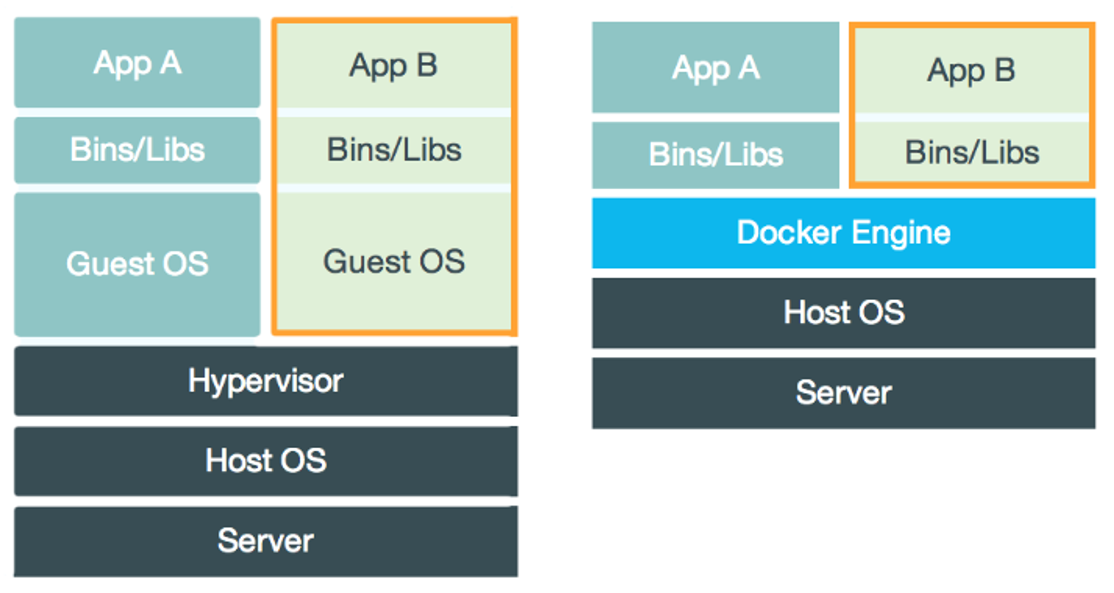
Docker 主要解决环境配置问题,它是一种虚拟化技术,对进程进行隔离,被隔离的进程独立于宿主操作系统和其它隔离的进程。使用 Docker 可以不修改应用程序代码,不需要开发人员学习特定环境下的技术,就能够将现有的应用程序部署在其它机器上。
- 
+ 
# 二、与虚拟机的比较
虚拟机也是一种虚拟化技术,它与 Docker 最大的区别在于它是通过模拟硬件,并在硬件上安装操作系统来实现。
- 
+ 
## 启动速度
@@ -74,7 +74,7 @@ Docker 轻量级的特点使得它很适合用于部署、维护、组合微服
构建容器时,通过在镜像的基础上添加一个可写层(writable layer),用来保存着容器运行过程中的修改。
- 
+ 
# 参考资料
diff --git a/docs/notes/Git.md b/docs/notes/Git.md
index c0939994..b4497648 100644
--- a/docs/notes/Git.md
+++ b/docs/notes/Git.md
@@ -18,7 +18,7 @@
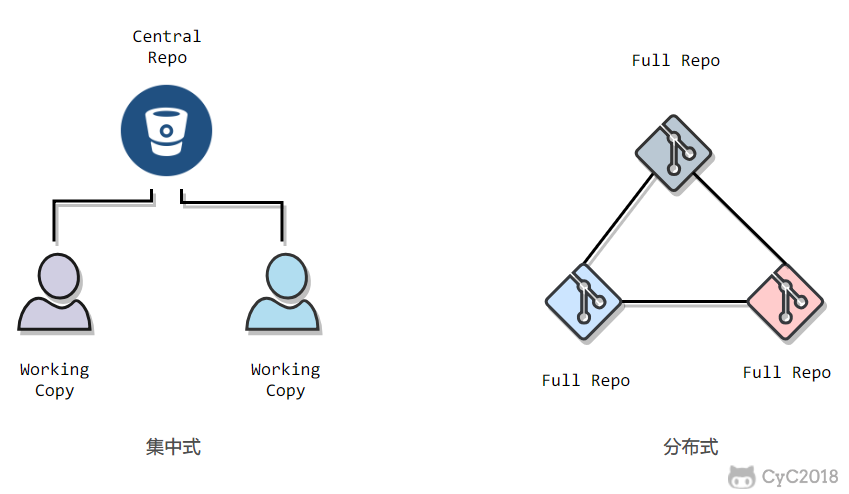
Git 属于分布式版本控制系统,而 SVN 属于集中式。
- 
+ 
集中式版本控制只有中心服务器拥有一份代码,而分布式版本控制每个人的电脑上就有一份完整的代码。
@@ -40,45 +40,45 @@ Github 就是一个中心服务器。
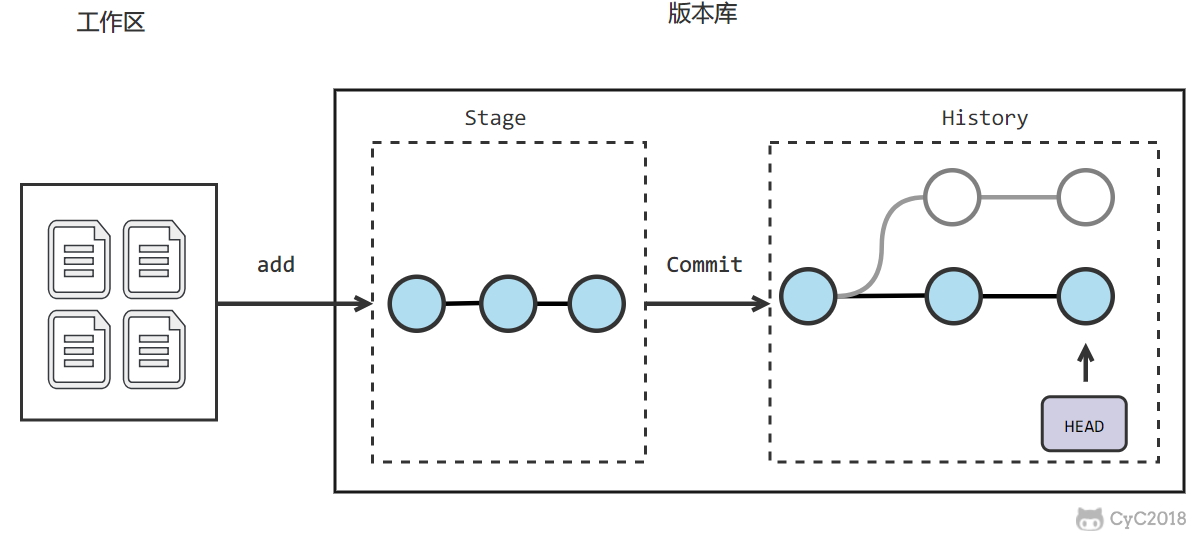
Git 的版本库有一个称为 Stage 的暂存区以及最后的 History 版本库,History 存储所有分支信息,使用一个 HEAD 指针指向当前分支。
- 
+ 
- git add files 把文件的修改添加到暂存区
- git commit 把暂存区的修改提交到当前分支,提交之后暂存区就被清空了
- git reset -- files 使用当前分支上的修改覆盖暂存区,用来撤销最后一次 git add files
- git checkout -- files 使用暂存区的修改覆盖工作目录,用来撤销本地修改
- 
+ 
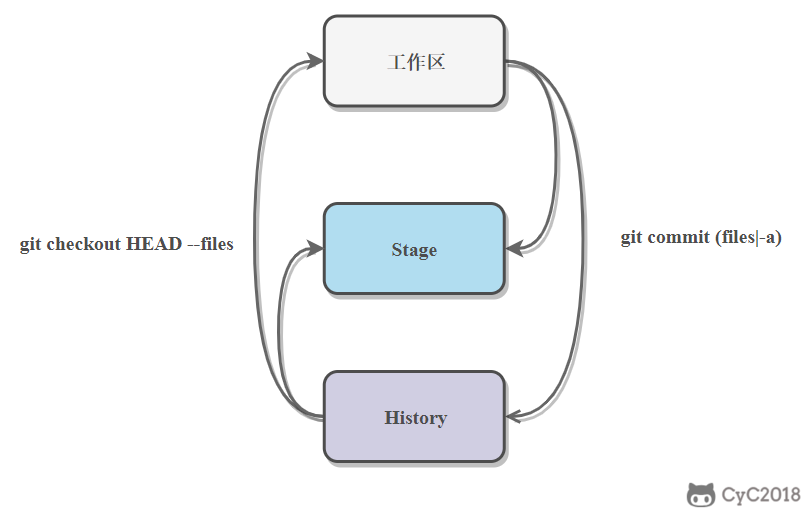
可以跳过暂存区域直接从分支中取出修改,或者直接提交修改到分支中。
- git commit -a 直接把所有文件的修改添加到暂存区然后执行提交
- git checkout HEAD -- files 取出最后一次修改,可以用来进行回滚操作
- 
+ 
# 分支实现
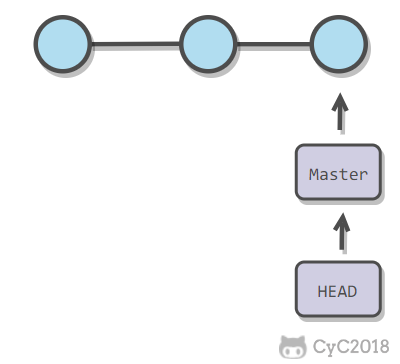
使用指针将每个提交连接成一条时间线,HEAD 指针指向当前分支指针。
- 
+ 
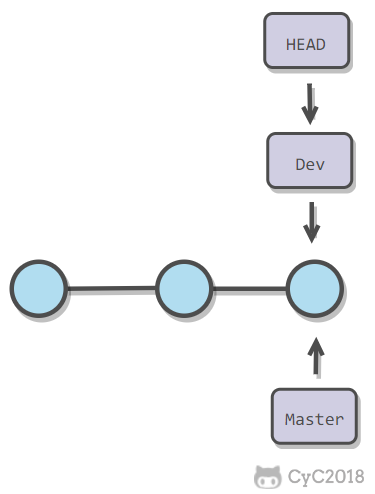
新建分支是新建一个指针指向时间线的最后一个节点,并让 HEAD 指针指向新分支,表示新分支成为当前分支。
- 
+ 
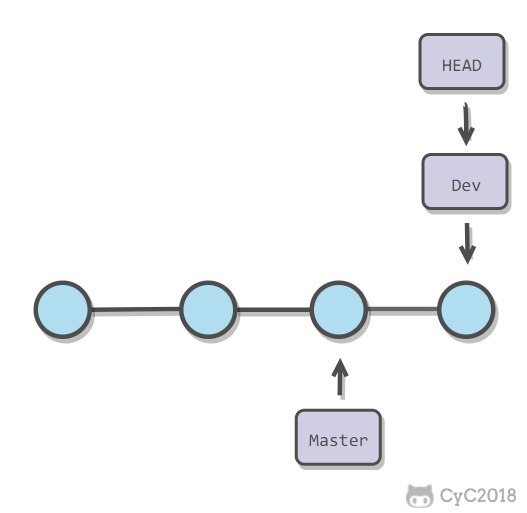
每次提交只会让当前分支指针向前移动,而其它分支指针不会移动。
- 
+ 
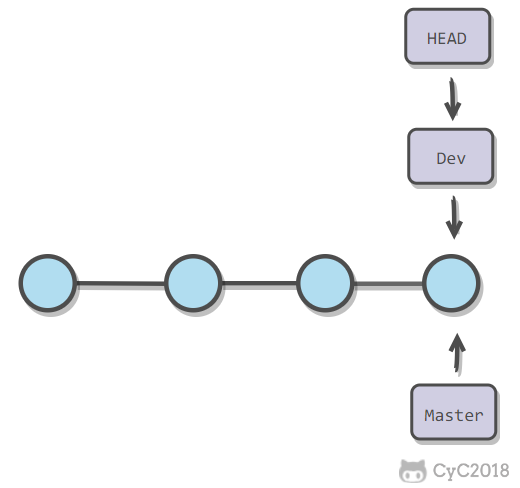
合并分支也只需要改变指针即可。
- 
+ 
# 冲突
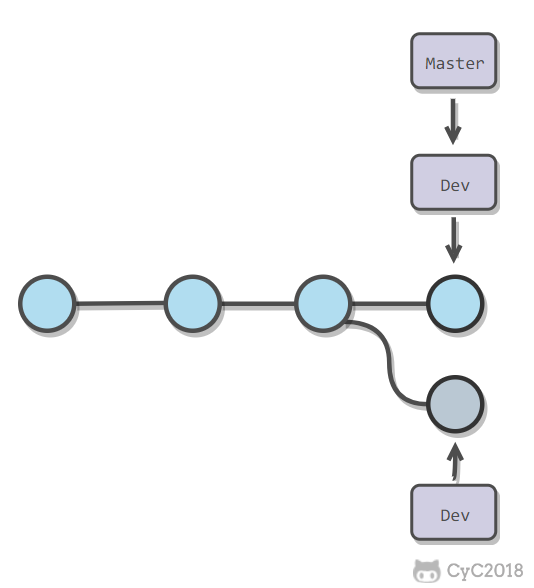
当两个分支都对同一个文件的同一行进行了修改,在分支合并时就会产生冲突。
- 
+ 
Git 会使用 <<<<<<< ,======= ,>>>>>>> 标记出不同分支的内容,只需要把不同分支中冲突部分修改成一样就能解决冲突。
@@ -100,7 +100,7 @@ Creating a new branch is quick AND simple.
$ git merge --no-ff -m "merge with no-ff" dev
```
- 
+ 
# 分支管理策略
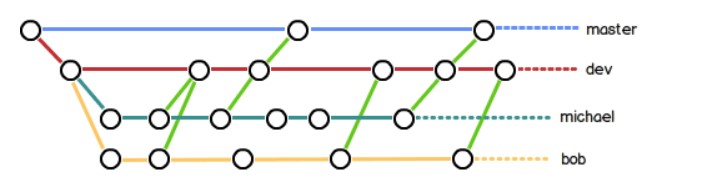
@@ -108,7 +108,7 @@ master 分支应该是非常稳定的,只用来发布新版本;
日常开发在开发分支 dev 上进行。
- 
+ 
# 储藏(Stashing)
@@ -148,7 +148,7 @@ $ ssh-keygen -t rsa -C "youremail@example.com"
# Git 命令一览
- 
+ 
比较详细的地址:http://www.cheat-sheets.org/saved-copy/git-cheat-sheet.pdf
diff --git a/docs/notes/HTTP.md b/docs/notes/HTTP.md
index 8501eff5..228951a1 100644
--- a/docs/notes/HTTP.md
+++ b/docs/notes/HTTP.md
@@ -62,17 +62,17 @@
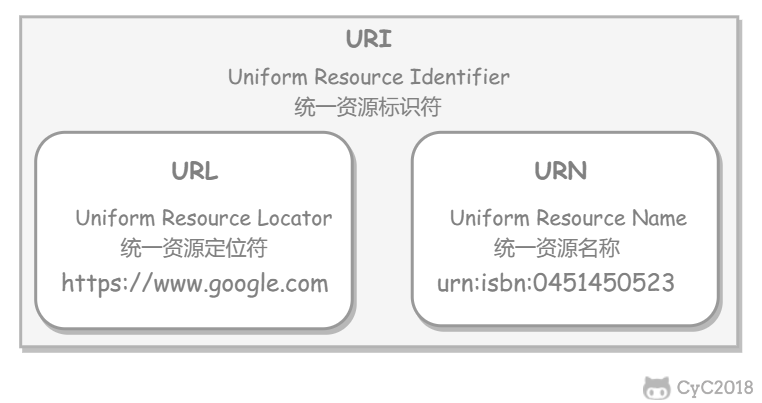
URI 包含 URL 和 URN。
- 
+ 
## 请求和响应报文
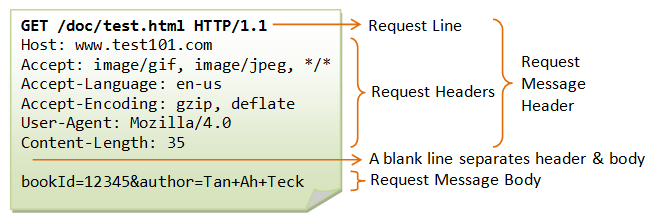
### 1. 请求报文
- 
+ 
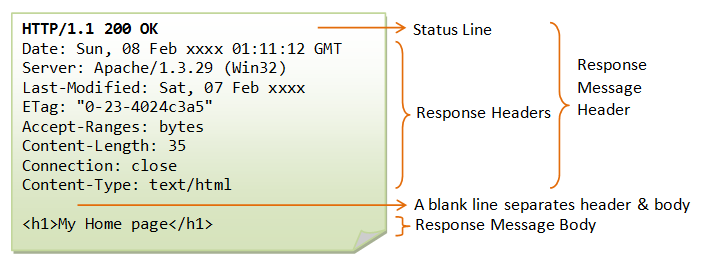
### 2. 响应报文
- 
+ 
# 二、HTTP 方法
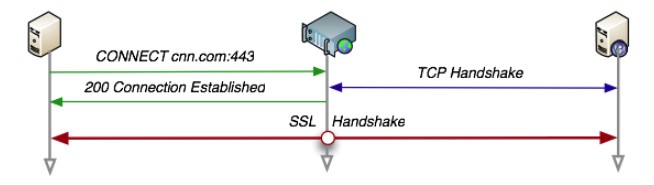
@@ -159,7 +159,7 @@ DELETE /file.html HTTP/1.1
CONNECT www.example.com:443 HTTP/1.1
```
- 
+ 
## TRACE
@@ -302,7 +302,7 @@ CONNECT www.example.com:443 HTTP/1.1
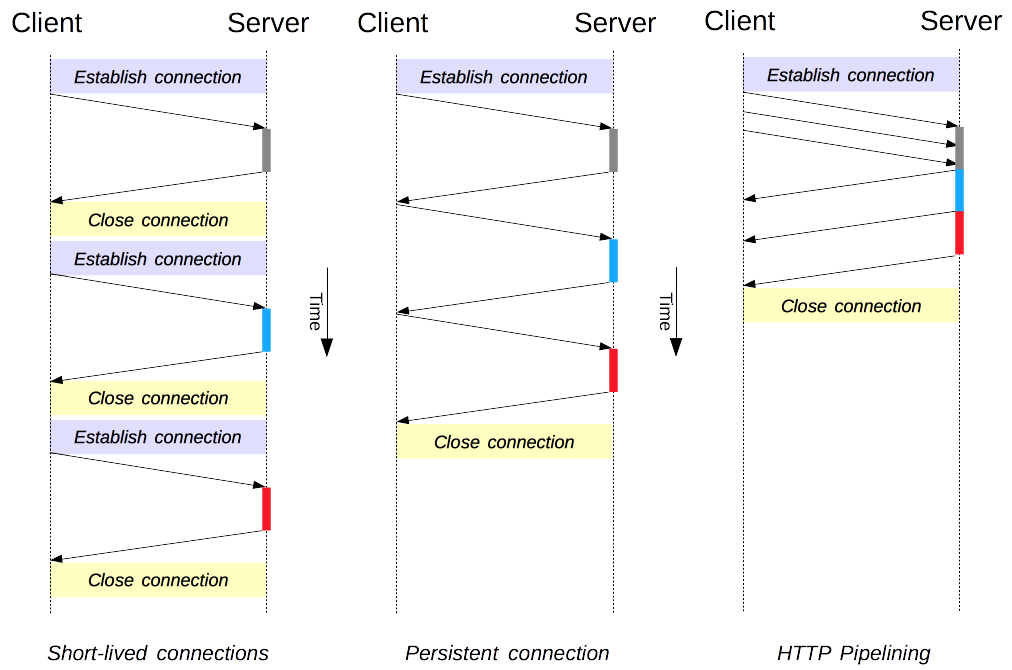
## 连接管理
- 
+ 
### 1. 短连接与长连接
@@ -631,11 +631,11 @@ HTTP/1.1 使用虚拟主机技术,使得一台服务器拥有多个域名,
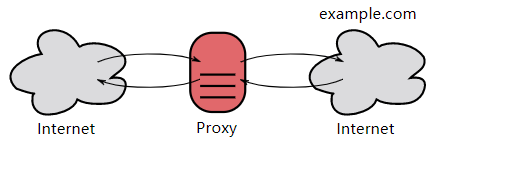
- 用户察觉得到正向代理的存在。
- 
+ 
- 而反向代理一般位于内部网络中,用户察觉不到。
- 
+ 
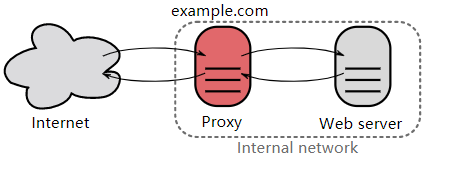
### 2. 网关
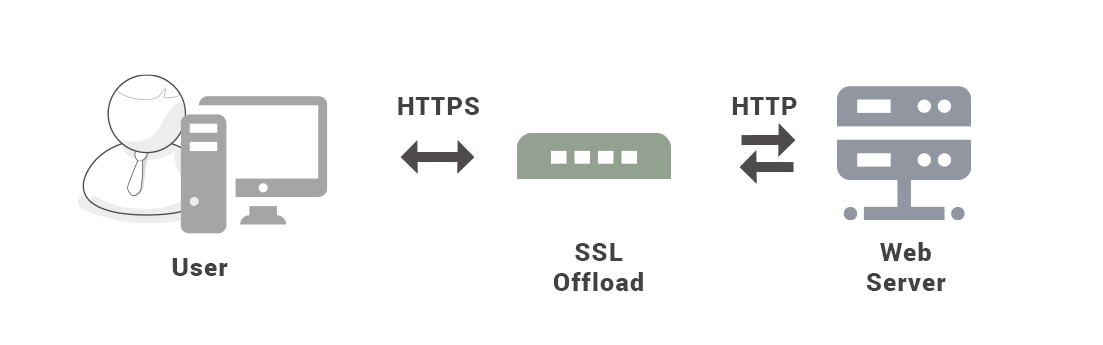
@@ -657,7 +657,7 @@ HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)
通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。
- 
+ 
## 加密
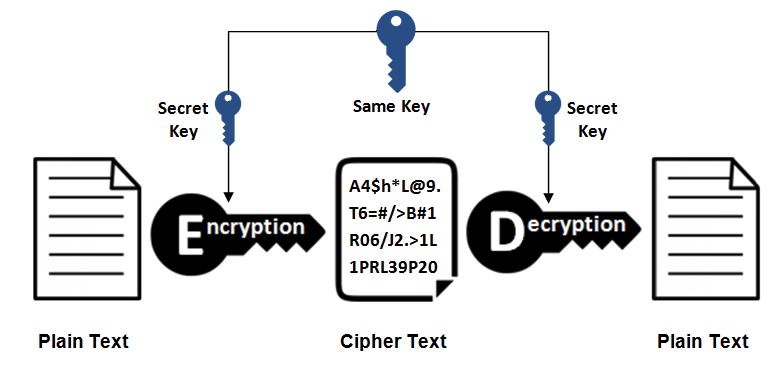
@@ -668,7 +668,7 @@ HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)
- 优点:运算速度快;
- 缺点:无法安全地将密钥传输给通信方。
- 
+ 
### 2.非对称密钥加密
@@ -681,7 +681,7 @@ HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)
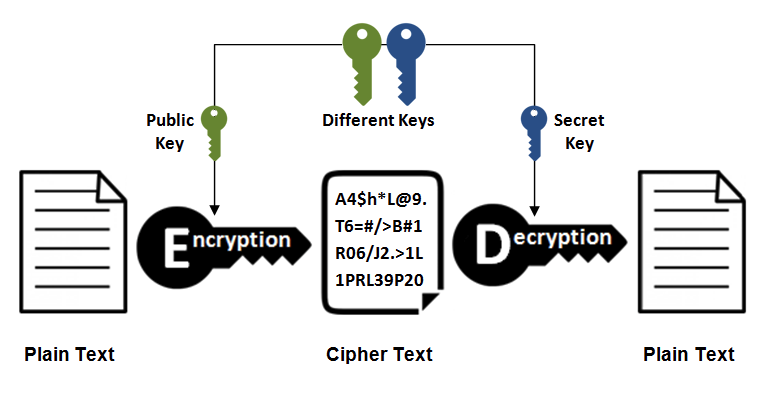
- 优点:可以更安全地将公开密钥传输给通信发送方;
- 缺点:运算速度慢。
- 
+ 
### 3. HTTPS 采用的加密方式
@@ -690,7 +690,7 @@ HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)
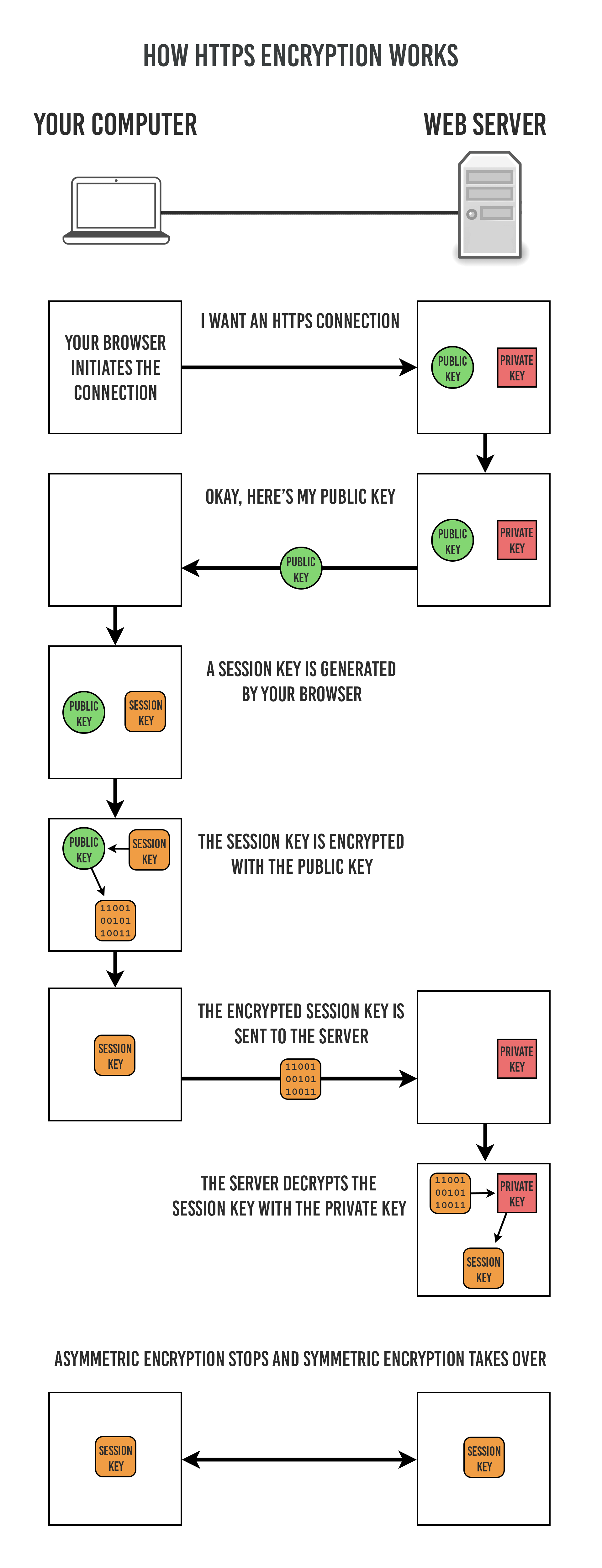
- 使用非对称密钥加密方式,传输对称密钥加密方式所需要的 Secret Key,从而保证安全性;
- 获取到 Secret Key 后,再使用对称密钥加密方式进行通信,从而保证效率。(下图中的 Session Key 就是 Secret Key)
- 
+ 
## 认证
@@ -702,7 +702,7 @@ HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)
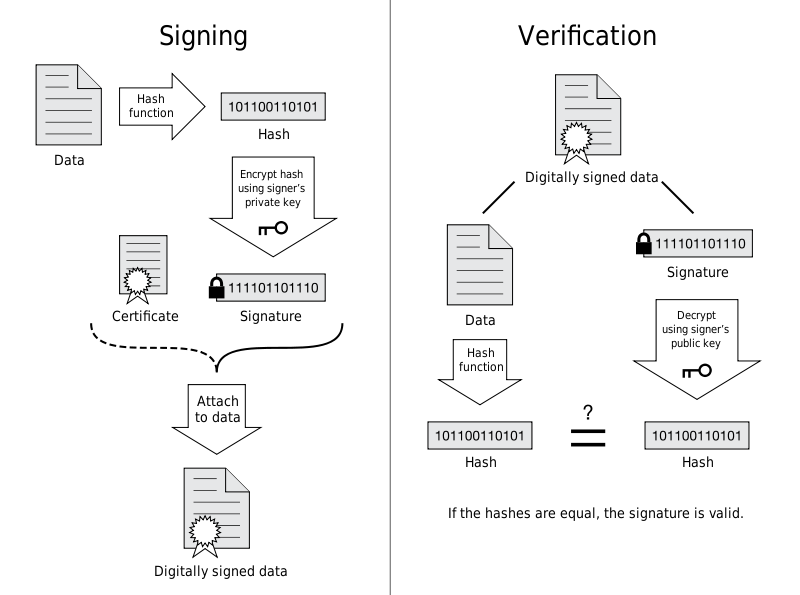
进行 HTTPS 通信时,服务器会把证书发送给客户端。客户端取得其中的公开密钥之后,先使用数字签名进行验证,如果验证通过,就可以开始通信了。
- 
+ 
## 完整性保护
@@ -731,7 +731,7 @@ HTTP/1.x 实现简单是以牺牲性能为代价的:
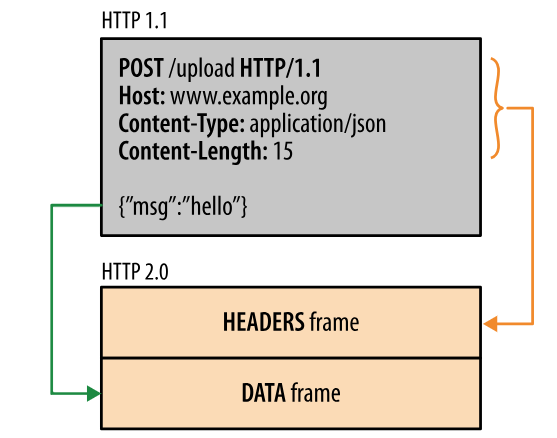
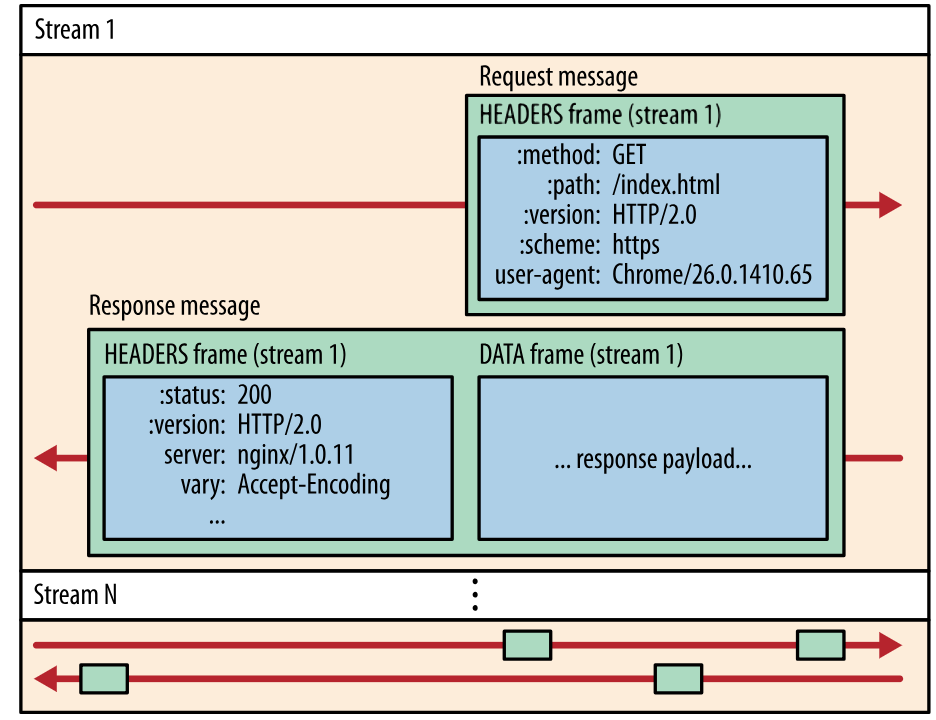
HTTP/2.0 将报文分成 HEADERS 帧和 DATA 帧,它们都是二进制格式的。
- 
+ 
在通信过程中,只会有一个 TCP 连接存在,它承载了任意数量的双向数据流(Stream)。
@@ -739,13 +739,13 @@ HTTP/2.0 将报文分成 HEADERS 帧和 DATA 帧,它们都是二进制格式
- 消息(Message)是与逻辑请求或响应对应的完整的一系列帧。
- 帧(Frame)是最小的通信单位,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
- 
+ 
## 服务端推送
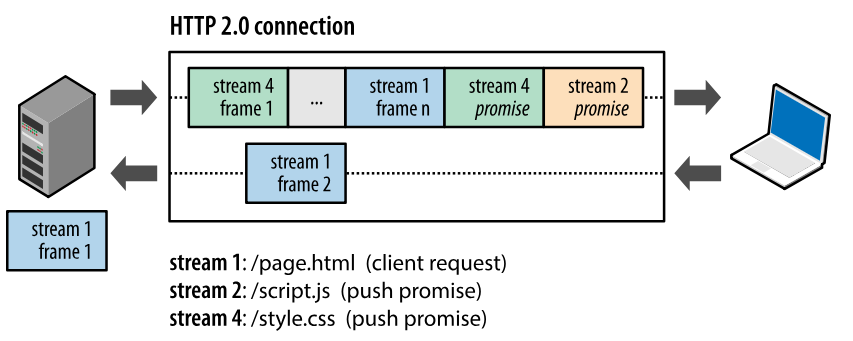
HTTP/2.0 在客户端请求一个资源时,会把相关的资源一起发送给客户端,客户端就不需要再次发起请求了。例如客户端请求 page.html 页面,服务端就把 script.js 和 style.css 等与之相关的资源一起发给客户端。
- 
+ 
## 首部压缩
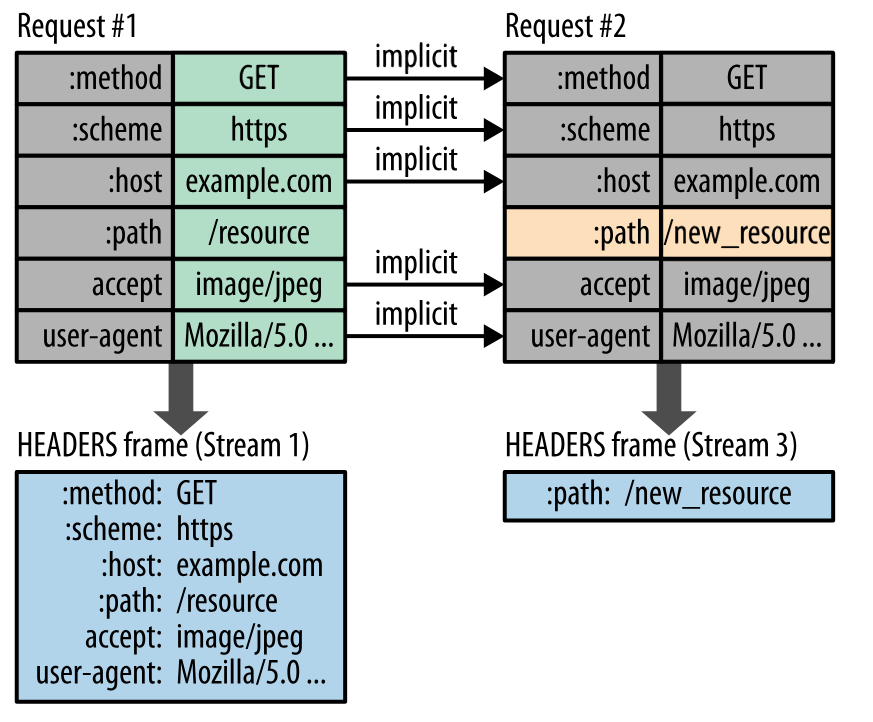
@@ -755,7 +755,7 @@ HTTP/2.0 要求客户端和服务器同时维护和更新一个包含之前见
不仅如此,HTTP/2.0 也使用 Huffman 编码对首部字段进行压缩。
- 
+ 
# 八、HTTP/1.1 新特性
diff --git a/docs/notes/Java IO.md b/docs/notes/Java IO.md
index 41b4ed3e..4af02337 100644
--- a/docs/notes/Java IO.md
+++ b/docs/notes/Java IO.md
@@ -97,7 +97,7 @@ Java I/O 使用了装饰者模式来实现。以 InputStream 为例,
- FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;
- FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
- 
+ 
实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
@@ -277,7 +277,7 @@ public static void main(String[] args) throws IOException {
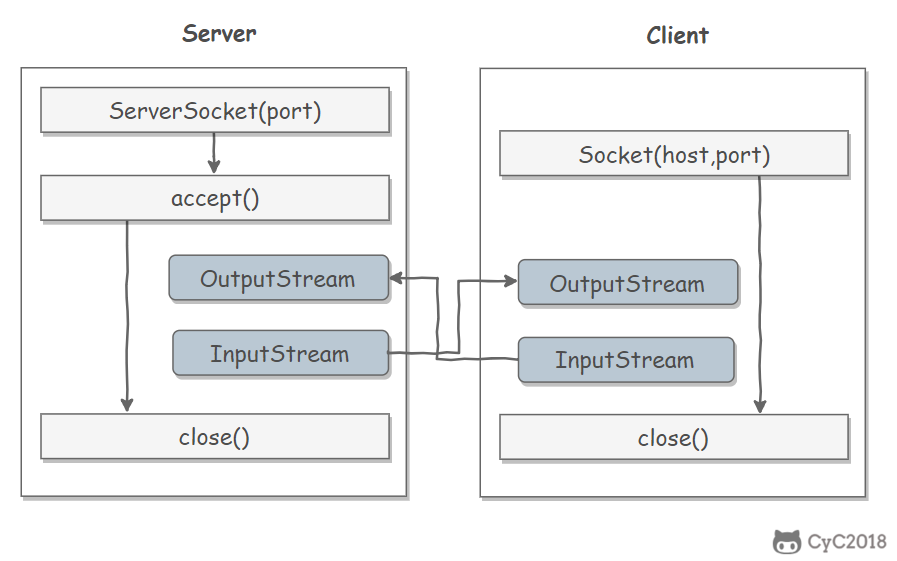
- Socket:客户端类
- 服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。
- 
+ 
## Datagram
@@ -339,23 +339,23 @@ I/O 包和 NIO 已经很好地集成了,java.io.\* 已经以 NIO 为基础重
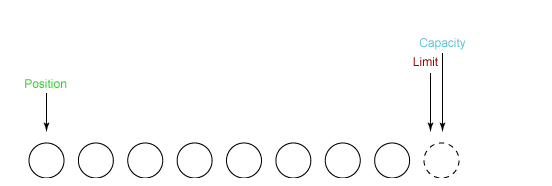
① 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。
- 
+ 
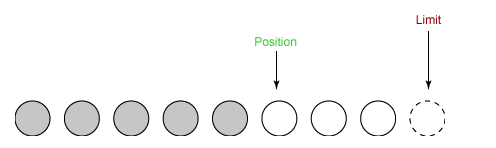
② 从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 为 5,limit 保持不变。
- 
+ 
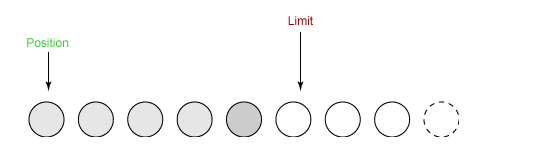
③ 在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。
- 
+ 
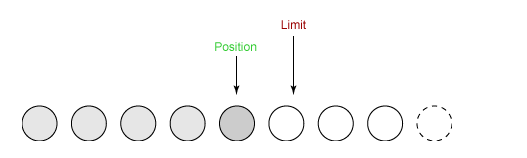
④ 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。
- 
+ 
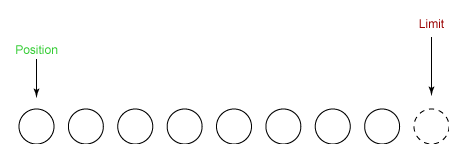
⑤ 最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。
- 
+ 
## 文件 NIO 实例
@@ -413,7 +413,7 @@ NIO 实现了 IO 多路复用中的 Reactor 模型,一个线程 Thread 使用
应该注意的是,只有套接字 Channel 才能配置为非阻塞,而 FileChannel 不能,为 FileChannel 配置非阻塞也没有意义。
- 
+ 
### 1. 创建选择器
diff --git a/docs/notes/Java 基础.md b/docs/notes/Java 基础.md
index c5046234..d0d43b3b 100644
--- a/docs/notes/Java 基础.md
+++ b/docs/notes/Java 基础.md
@@ -193,7 +193,7 @@ value 数组被声明为 final,这意味着 value 数组初始化之后就不
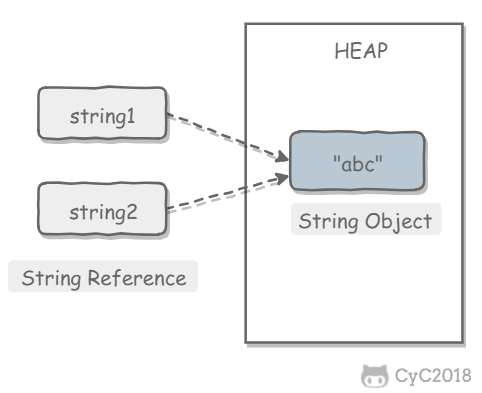
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
- 
+ 
**3. 安全性**
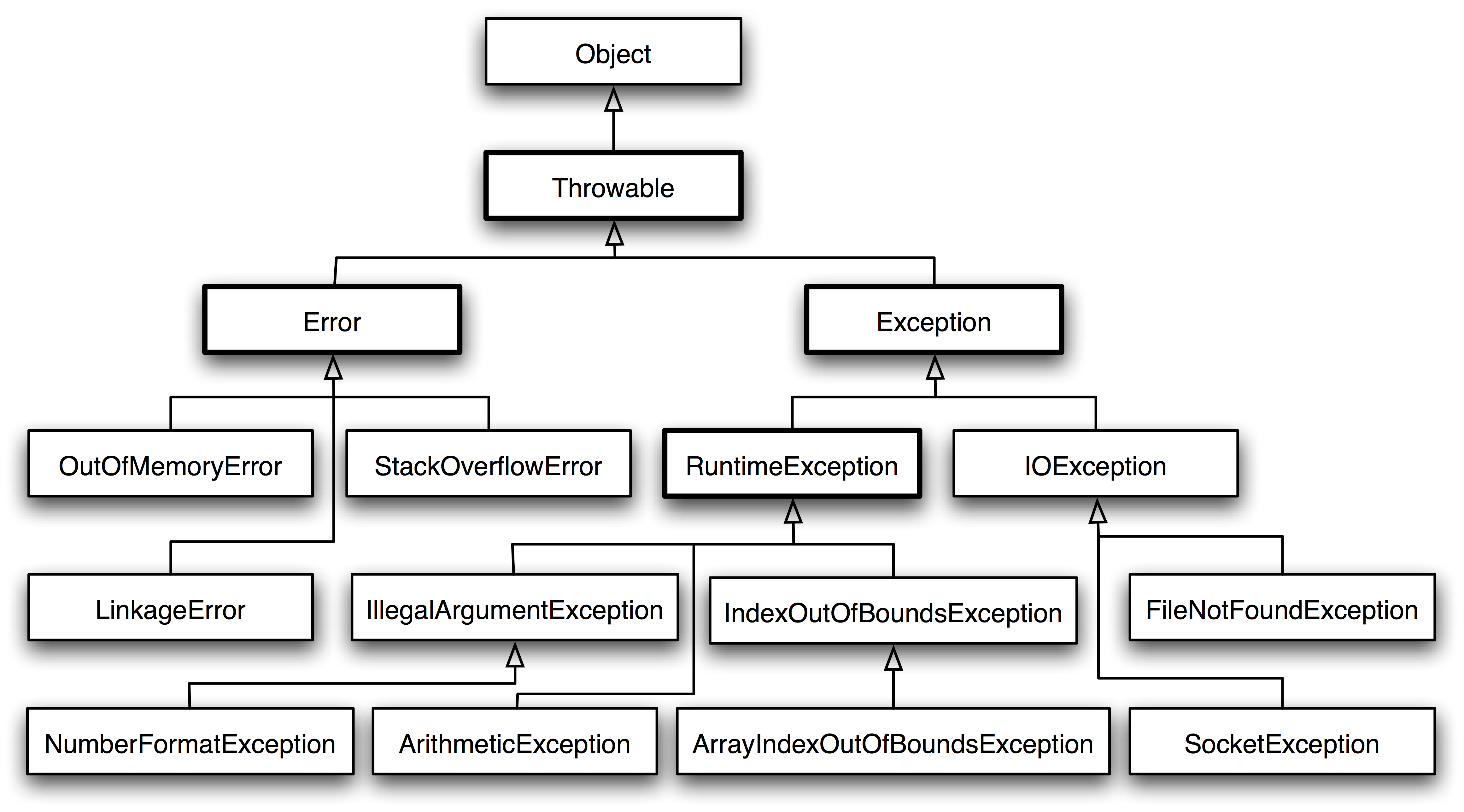
@@ -1356,7 +1356,7 @@ Throwable 可以用来表示任何可以作为异常抛出的类,分为两种
- **受检异常** :需要用 try...catch... 语句捕获并进行处理,并且可以从异常中恢复;
- **非受检异常** :是程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序崩溃并且无法恢复。
- 
+ 
- [Java 入门之异常处理](https://www.tianmaying.com/tutorial/Java-Exception)
- [Java 异常的面试问题及答案 -Part 1](http://www.importnew.com/7383.html)
diff --git a/docs/notes/Java 容器.md b/docs/notes/Java 容器.md
index 50b21fbc..23537532 100644
--- a/docs/notes/Java 容器.md
+++ b/docs/notes/Java 容器.md
@@ -24,7 +24,7 @@
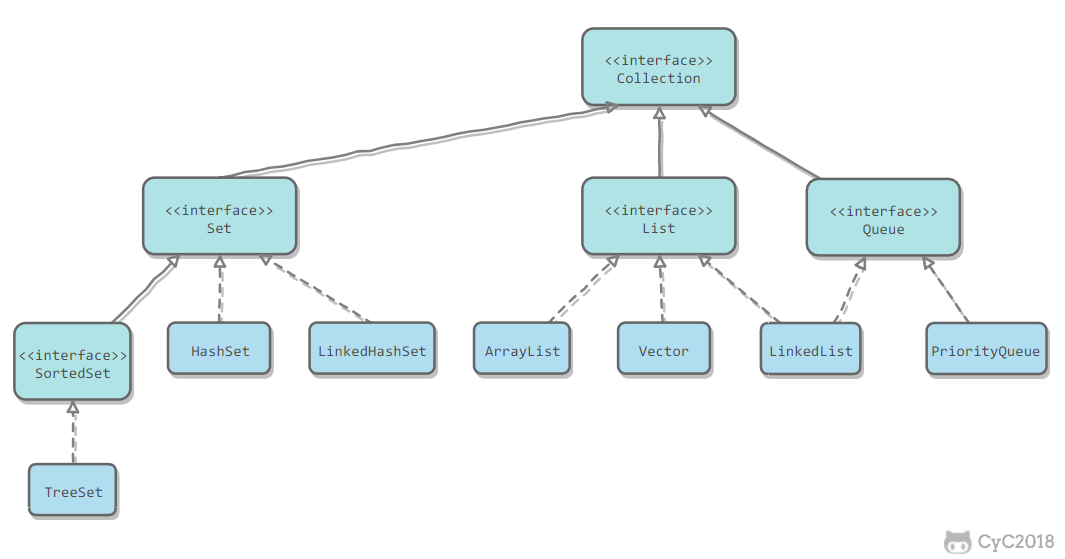
## Collection
- 
+ 
### 1. Set
@@ -50,7 +50,7 @@
## Map
- 
+ 
- TreeMap:基于红黑树实现。
@@ -65,7 +65,7 @@
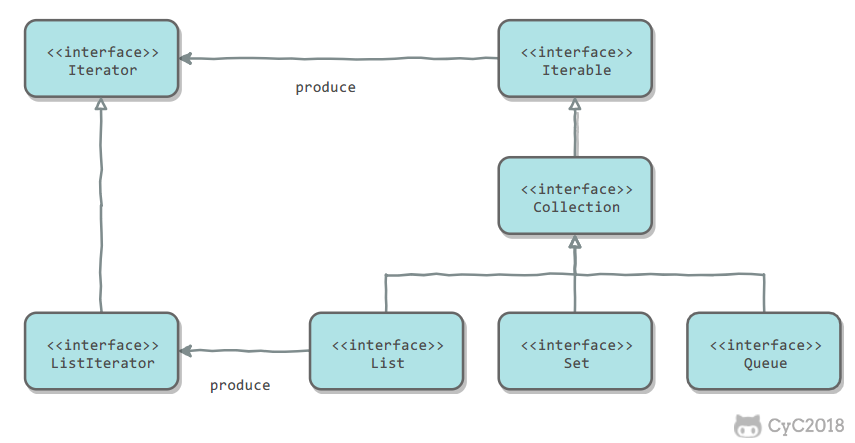
## 迭代器模式
- 
+ 
Collection 继承了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
@@ -126,7 +126,7 @@ public class ArrayList extends AbstractList
private static final int DEFAULT_CAPACITY = 10;
```
- 
+ 
### 2. 扩容
@@ -430,7 +430,7 @@ transient Node first;
transient Node last;
```
- 
+ 
### 2. 与 ArrayList 的比较
@@ -452,7 +452,7 @@ transient Entry[] table;
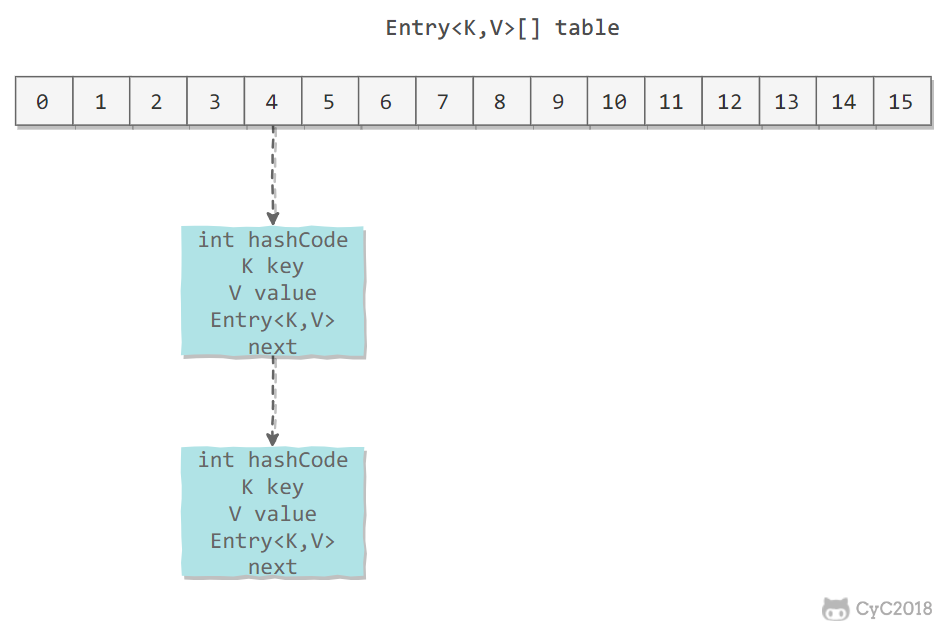
Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。
- 
+ 
```java
static class Entry implements Map.Entry {
@@ -528,7 +528,7 @@ map.put("K3", "V3");
- 计算键值对所在的桶;
- 在链表上顺序查找,时间复杂度显然和链表的长度成正比。
- 
+ 
### 3. put 操作
@@ -864,7 +864,7 @@ final Segment[] segments;
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
```
-
+
### 2. size 操作
diff --git a/docs/notes/Java 并发.md b/docs/notes/Java 并发.md
index ee8a6fd5..dc7e314d 100644
--- a/docs/notes/Java 并发.md
+++ b/docs/notes/Java 并发.md
@@ -61,7 +61,7 @@
# 一、线程状态转换
-
+
## 新建(New)
@@ -736,7 +736,7 @@ java.util.concurrent(J.U.C)大大提高了并发性能,AQS 被认为是 J.
维护了一个计数器 cnt,每次调用 countDown() 方法会让计数器的值减 1,减到 0 的时候,那些因为调用 await() 方法而在等待的线程就会被唤醒。
-
+
```java
public class CountdownLatchExample {
@@ -785,7 +785,7 @@ public CyclicBarrier(int parties) {
}
```
-
+
```java
public class CyclicBarrierExample {
@@ -1022,7 +1022,7 @@ public class ForkJoinPool extends AbstractExecutorService
ForkJoinPool 实现了工作窃取算法来提高 CPU 的利用率。每个线程都维护了一个双端队列,用来存储需要执行的任务。工作窃取算法允许空闲的线程从其它线程的双端队列中窃取一个任务来执行。窃取的任务必须是最晚的任务,避免和队列所属线程发生竞争。例如下图中,Thread2 从 Thread1 的队列中拿出最晚的 Task1 任务,Thread1 会拿出 Task2 来执行,这样就避免发生竞争。但是如果队列中只有一个任务时还是会发生竞争。
-
+
# 九、线程不安全示例
@@ -1077,19 +1077,19 @@ Java 内存模型试图屏蔽各种硬件和操作系统的内存访问差异,
加入高速缓存带来了一个新的问题:缓存一致性。如果多个缓存共享同一块主内存区域,那么多个缓存的数据可能会不一致,需要一些协议来解决这个问题。
-
+
所有的变量都存储在主内存中,每个线程还有自己的工作内存,工作内存存储在高速缓存或者寄存器中,保存了该线程使用的变量的主内存副本拷贝。
线程只能直接操作工作内存中的变量,不同线程之间的变量值传递需要通过主内存来完成。
-
+
## 内存间交互操作
Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互操作。
-
+
- read:把一个变量的值从主内存传输到工作内存中
- load:在 read 之后执行,把 read 得到的值放入工作内存的变量副本中
@@ -1112,11 +1112,11 @@ Java 内存模型保证了 read、load、use、assign、store、write、lock 和
下图演示了两个线程同时对 cnt 进行操作,load、assign、store 这一系列操作整体上看不具备原子性,那么在 T1 修改 cnt 并且还没有将修改后的值写入主内存,T2 依然可以读入旧值。可以看出,这两个线程虽然执行了两次自增运算,但是主内存中 cnt 的值最后为 1 而不是 2。因此对 int 类型读写操作满足原子性只是说明 load、assign、store 这些单个操作具备原子性。
-
+
AtomicInteger 能保证多个线程修改的原子性。
-
+
使用 AtomicInteger 重写之前线程不安全的代码之后得到以下线程安全实现:
@@ -1224,7 +1224,7 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
在一个线程内,在程序前面的操作先行发生于后面的操作。
-
+
### 2. 管程锁定规则
@@ -1232,7 +1232,7 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。
-
+
### 3. volatile 变量规则
@@ -1240,7 +1240,7 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。
-
+
### 4. 线程启动规则
@@ -1248,7 +1248,7 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
Thread 对象的 start() 方法调用先行发生于此线程的每一个动作。
-
+
### 5. 线程加入规则
@@ -1256,7 +1256,7 @@ Thread 对象的 start() 方法调用先行发生于此线程的每一个动作
Thread 对象的结束先行发生于 join() 方法返回。
-
+
### 6. 线程中断规则
@@ -1474,7 +1474,7 @@ public class ThreadLocalExample1 {
它所对应的底层结构图为:
-
+
每个 Thread 都有一个 ThreadLocal.ThreadLocalMap 对象。
@@ -1577,17 +1577,17 @@ JDK 1.6 引入了偏向锁和轻量级锁,从而让锁拥有了四个状态:
以下是 HotSpot 虚拟机对象头的内存布局,这些数据被称为 Mark Word。其中 tag bits 对应了五个状态,这些状态在右侧的 state 表格中给出。除了 marked for gc 状态,其它四个状态已经在前面介绍过了。
-
+
下图左侧是一个线程的虚拟机栈,其中有一部分称为 Lock Record 的区域,这是在轻量级锁运行过程创建的,用于存放锁对象的 Mark Word。而右侧就是一个锁对象,包含了 Mark Word 和其它信息。
-
+
轻量级锁是相对于传统的重量级锁而言,它使用 CAS 操作来避免重量级锁使用互斥量的开销。对于绝大部分的锁,在整个同步周期内都是不存在竞争的,因此也就不需要都使用互斥量进行同步,可以先采用 CAS 操作进行同步,如果 CAS 失败了再改用互斥量进行同步。
当尝试获取一个锁对象时,如果锁对象标记为 0 01,说明锁对象的锁未锁定(unlocked)状态。此时虚拟机在当前线程的虚拟机栈中创建 Lock Record,然后使用 CAS 操作将对象的 Mark Word 更新为 Lock Record 指针。如果 CAS 操作成功了,那么线程就获取了该对象上的锁,并且对象的 Mark Word 的锁标记变为 00,表示该对象处于轻量级锁状态。
-
+
如果 CAS 操作失败了,虚拟机首先会检查对象的 Mark Word 是否指向当前线程的虚拟机栈,如果是的话说明当前线程已经拥有了这个锁对象,那就可以直接进入同步块继续执行,否则说明这个锁对象已经被其他线程线程抢占了。如果有两条以上的线程争用同一个锁,那轻量级锁就不再有效,要膨胀为重量级锁。
@@ -1599,7 +1599,7 @@ JDK 1.6 引入了偏向锁和轻量级锁,从而让锁拥有了四个状态:
当有另外一个线程去尝试获取这个锁对象时,偏向状态就宣告结束,此时撤销偏向(Revoke Bias)后恢复到未锁定状态或者轻量级锁状态。
-
+
# 十三、多线程开发良好的实践
diff --git a/docs/notes/Java 虚拟机.md b/docs/notes/Java 虚拟机.md
index 1a6e0cff..e2a2bff1 100644
--- a/docs/notes/Java 虚拟机.md
+++ b/docs/notes/Java 虚拟机.md
@@ -32,7 +32,7 @@
# 一、运行时数据区域
-
+
## 程序计数器
@@ -42,7 +42,7 @@
每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
-
+
可以通过 -Xss 这个虚拟机参数来指定每个线程的 Java 虚拟机栈内存大小,在 JDK 1.4 中默认为 256K,而在 JDK 1.5+ 默认为 1M:
@@ -61,7 +61,7 @@ java -Xss2M HackTheJava
本地方法一般是用其它语言(C、C++ 或汇编语言等)编写的,并且被编译为基于本机硬件和操作系统的程序,对待这些方法需要特别处理。
-
+
## 堆
@@ -146,7 +146,7 @@ Java 虚拟机使用该算法来判断对象是否可被回收,GC Roots 一般
- 方法区中类静态属性引用的对象
- 方法区中的常量引用的对象
-
+
### 3. 方法区的回收
@@ -227,7 +227,7 @@ obj = null;
### 1. 标记 - 清除
-
+
在标记阶段,程序会检查每个对象是否为活动对象,如果是活动对象,则程序会在对象头部打上标记。
@@ -242,7 +242,7 @@ obj = null;
### 2. 标记 - 整理
-
+
让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
@@ -256,7 +256,7 @@ obj = null;
### 3. 复制
-
+
将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。
@@ -277,7 +277,7 @@ HotSpot 虚拟机的 Eden 和 Survivor 大小比例默认为 8:1,保证了内
## 垃圾收集器
-
+
以上是 HotSpot 虚拟机中的 7 个垃圾收集器,连线表示垃圾收集器可以配合使用。
@@ -286,7 +286,7 @@ HotSpot 虚拟机的 Eden 和 Survivor 大小比例默认为 8:1,保证了内
### 1. Serial 收集器
-
+
Serial 翻译为串行,也就是说它以串行的方式执行。
@@ -298,7 +298,7 @@ Serial 翻译为串行,也就是说它以串行的方式执行。
### 2. ParNew 收集器
-
+
它是 Serial 收集器的多线程版本。
@@ -318,7 +318,7 @@ Serial 翻译为串行,也就是说它以串行的方式执行。
### 4. Serial Old 收集器
-
+
是 Serial 收集器的老年代版本,也是给 Client 场景下的虚拟机使用。如果用在 Server 场景下,它有两大用途:
@@ -327,7 +327,7 @@ Serial 翻译为串行,也就是说它以串行的方式执行。
### 5. Parallel Old 收集器
-
+
是 Parallel Scavenge 收集器的老年代版本。
@@ -335,7 +335,7 @@ Serial 翻译为串行,也就是说它以串行的方式执行。
### 6. CMS 收集器
-
+
CMS(Concurrent Mark Sweep),Mark Sweep 指的是标记 - 清除算法。
@@ -360,17 +360,17 @@ G1(Garbage-First),它是一款面向服务端应用的垃圾收集器,
堆被分为新生代和老年代,其它收集器进行收集的范围都是整个新生代或者老年代,而 G1 可以直接对新生代和老年代一起回收。
-
+
G1 把堆划分成多个大小相等的独立区域(Region),新生代和老年代不再物理隔离。
-
+
通过引入 Region 的概念,从而将原来的一整块内存空间划分成多个的小空间,使得每个小空间可以单独进行垃圾回收。这种划分方法带来了很大的灵活性,使得可预测的停顿时间模型成为可能。通过记录每个 Region 垃圾回收时间以及回收所获得的空间(这两个值是通过过去回收的经验获得),并维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region。
每个 Region 都有一个 Remembered Set,用来记录该 Region 对象的引用对象所在的 Region。通过使用 Remembered Set,在做可达性分析的时候就可以避免全堆扫描。
-
+
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
@@ -458,7 +458,7 @@ G1 把堆划分成多个大小相等的独立区域(Region),新生代和
## 类的生命周期
-
+
包括以下 7 个阶段:
@@ -628,7 +628,7 @@ System.out.println(ConstClass.HELLOWORLD);
下图展示了类加载器之间的层次关系,称为双亲委派模型(Parents Delegation Model)。该模型要求除了顶层的启动类加载器外,其它的类加载器都要有自己的父类加载器。这里的父子关系一般通过组合关系(Composition)来实现,而不是继承关系(Inheritance)。
-
+
### 1. 工作过程
diff --git a/docs/notes/Leetcode 题解 - 动态规划.md b/docs/notes/Leetcode 题解 - 动态规划.md
index 305174be..eb3ce48b 100644
--- a/docs/notes/Leetcode 题解 - 动态规划.md
+++ b/docs/notes/Leetcode 题解 - 动态规划.md
@@ -61,7 +61,7 @@
-
+
考虑到 dp[i] 只与 dp[i - 1] 和 dp[i - 2] 有关,因此可以只用两个变量来存储 dp[i - 1] 和 dp[i - 2],使得原来的 O(N) 空间复杂度优化为 O(1) 复杂度。
@@ -94,7 +94,7 @@ public int climbStairs(int n) {
-
+
```java
public int rob(int[] nums) {
@@ -150,7 +150,7 @@ private int rob(int[] nums, int first, int last) {
-
+
## 5. 母牛生产
@@ -162,7 +162,7 @@ private int rob(int[] nums, int first, int last) {
-
+
# 矩阵路径
@@ -212,7 +212,7 @@ public int minPathSum(int[][] grid) {
题目描述:统计从矩阵左上角到右下角的路径总数,每次只能向右或者向下移动。
-
+
```java
public int uniquePaths(int m, int n) {
@@ -443,7 +443,7 @@ public int numDecodings(String s) {
-
+
对于一个长度为 N 的序列,最长递增子序列并不一定会以 SN 为结尾,因此 dp[N] 不是序列的最长递增子序列的长度,需要遍历 dp 数组找出最大值才是所要的结果,max{ dp[i] | 1 <= i <= N} 即为所求。
@@ -616,7 +616,7 @@ public int wiggleMaxLength(int[] nums) {
-
+
对于长度为 N 的序列 S1 和长度为 M 的序列 S2,dp[N][M] 就是序列 S1 和序列 S2 的最长公共子序列长度。
@@ -662,7 +662,7 @@ public int wiggleMaxLength(int[] nums) {
- 
+ 
```java
// W 为背包总体积
@@ -691,7 +691,7 @@ public int knapsack(int W, int N, int[] weights, int[] values) {
- 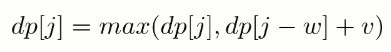
+ 
因为 dp[j-w] 表示 dp[i-1][j-w],因此不能先求 dp[i][j-w],防止将 dp[i-1][j-w] 覆盖。也就是说要先计算 dp[i][j] 再计算 dp[i][j-w],在程序实现时需要按倒序来循环求解。
@@ -1055,7 +1055,7 @@ public int combinationSum4(int[] nums, int target) {
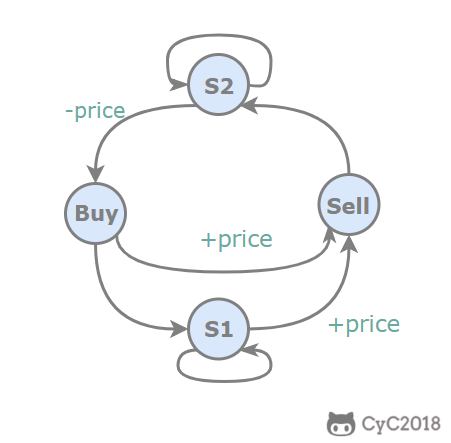
题目描述:交易之后需要有一天的冷却时间。
- 
+ 
```java
public int maxProfit(int[] prices) {
@@ -1098,7 +1098,7 @@ The total profit is ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
题目描述:每交易一次,都要支付一定的费用。
- 
+ 
```java
public int maxProfit(int[] prices, int fee) {
diff --git a/docs/notes/Leetcode 题解 - 双指针.md b/docs/notes/Leetcode 题解 - 双指针.md
index b24ab780..5db6895d 100644
--- a/docs/notes/Leetcode 题解 - 双指针.md
+++ b/docs/notes/Leetcode 题解 - 双指针.md
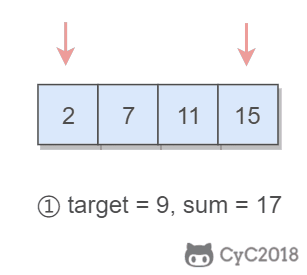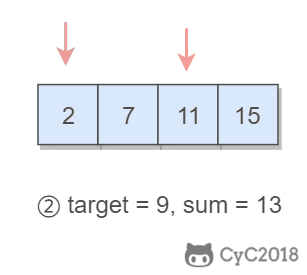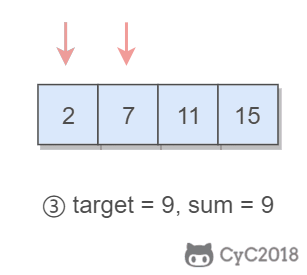
@@ -32,7 +32,7 @@ Output: index1=1, index2=2
数组中的元素最多遍历一次,时间复杂度为 O(N)。只使用了两个额外变量,空间复杂度为 O(1)。
- 
+ 
```java
public int[] twoSum(int[] numbers, int target) {
@@ -102,7 +102,7 @@ Explanation: 1 * 1 + 2 * 2 = 5
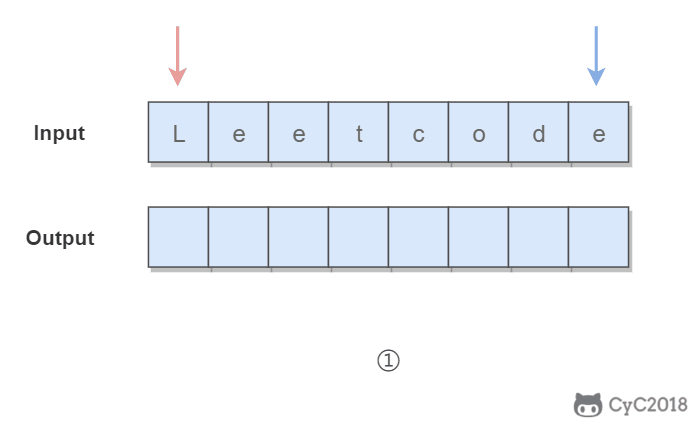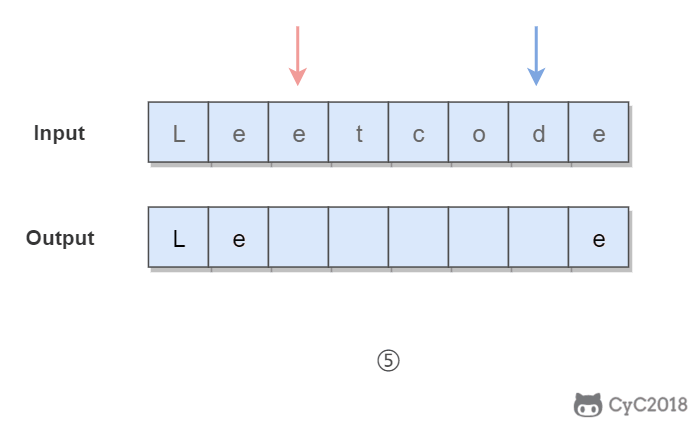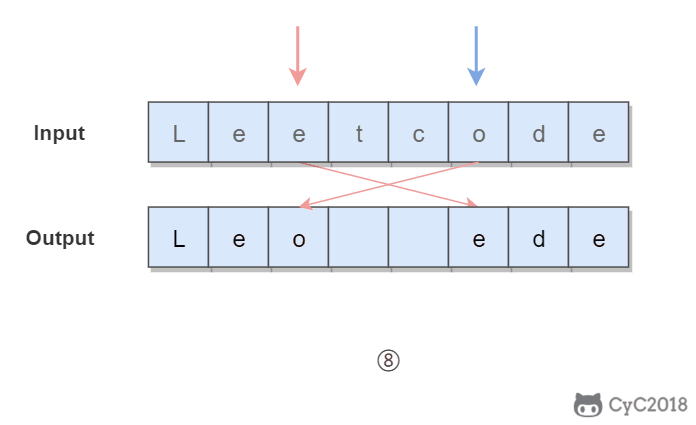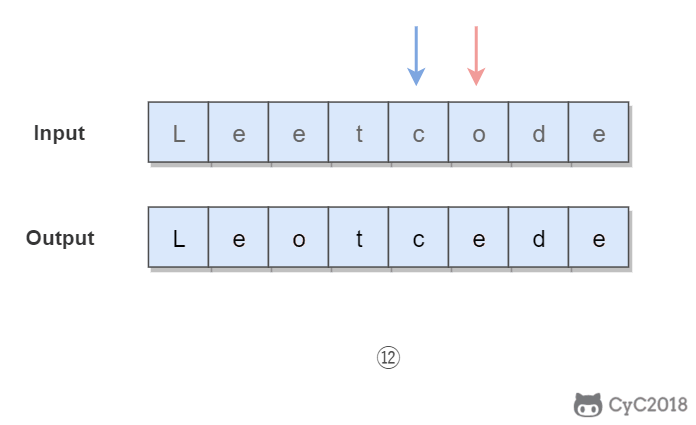
Given s = "leetcode", return "leotcede".
```
- 
+ 
使用双指针,一个指针从头向尾遍历,一个指针从尾到头遍历,当两个指针都遍历到元音字符时,交换这两个元音字符。
@@ -111,7 +111,7 @@ Given s = "leetcode", return "leotcede".
- 时间复杂度为 O(N):只需要遍历所有元素一次
- 空间复杂度 O(1):只需要使用两个额外变量
- 
+ 
```java
private final static HashSet vowels = new HashSet<>(
@@ -155,7 +155,7 @@ Explanation: You could delete the character 'c'.
使用双指针可以很容易判断一个字符串是否是回文字符串:令一个指针从左到右遍历,一个指针从右到左遍历,这两个指针同时移动一个位置,每次都判断两个指针指向的字符是否相同,如果都相同,字符串才是具有左右对称性质的回文字符串。
- 
+ 
本题的关键是处理删除一个字符。在使用双指针遍历字符串时,如果出现两个指针指向的字符不相等的情况,我们就试着删除一个字符,再判断删除完之后的字符串是否是回文字符串。
@@ -163,7 +163,7 @@ Explanation: You could delete the character 'c'.
在试着删除字符时,我们既可以删除左指针指向的字符,也可以删除右指针指向的字符。
- 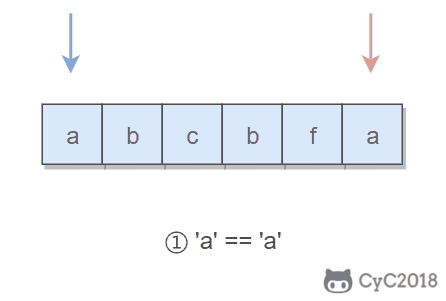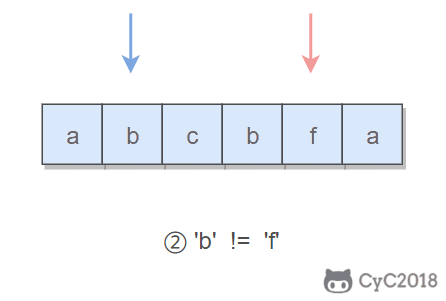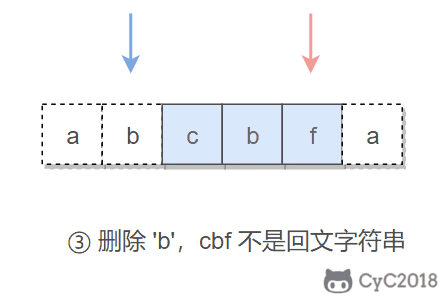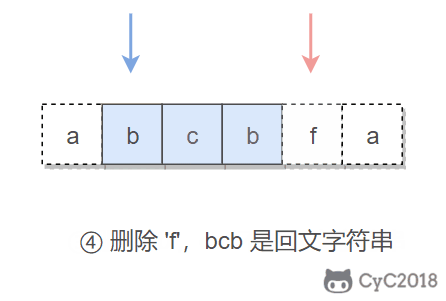
+ 
```java
public boolean validPalindrome(String s) {
diff --git a/docs/notes/Leetcode 题解 - 排序.md b/docs/notes/Leetcode 题解 - 排序.md
index 09fdc70d..b5155262 100644
--- a/docs/notes/Leetcode 题解 - 排序.md
+++ b/docs/notes/Leetcode 题解 - 排序.md
@@ -200,7 +200,7 @@ public String frequencySort(String s) {
有三种颜色的球,算法的目标是将这三种球按颜色顺序正确地排列。它其实是三向切分快速排序的一种变种,在三向切分快速排序中,每次切分都将数组分成三个区间:小于切分元素、等于切分元素、大于切分元素,而该算法是将数组分成三个区间:等于红色、等于白色、等于蓝色。
- 
+ 
## 1. 按颜色进行排序
diff --git a/docs/notes/Leetcode 题解 - 搜索.md b/docs/notes/Leetcode 题解 - 搜索.md
index 9f14efbd..6f3735d9 100644
--- a/docs/notes/Leetcode 题解 - 搜索.md
+++ b/docs/notes/Leetcode 题解 - 搜索.md
@@ -32,7 +32,7 @@
# BFS
- 
+ 
广度优先搜索一层一层地进行遍历,每层遍历都以上一层遍历的结果作为起点,遍历一个距离能访问到的所有节点。需要注意的是,遍历过的节点不能再次被遍历。
@@ -269,7 +269,7 @@ private int getShortestPath(List[] graphic, int start, int end) {
# DFS
- 
+ 
广度优先搜索一层一层遍历,每一层得到的所有新节点,要用队列存储起来以备下一层遍历的时候再遍历。
@@ -591,7 +591,7 @@ Backtracking(回溯)属于 DFS。
[Leetcode](https://leetcode.com/problems/letter-combinations-of-a-phone-number/description/) / [力扣](https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number/description/)
- 
+ 
```html
Input:Digit string "23"
@@ -1194,7 +1194,7 @@ private boolean isPalindrome(String s, int begin, int end) {
[Leetcode](https://leetcode.com/problems/sudoku-solver/description/) / [力扣](https://leetcode-cn.com/problems/sudoku-solver/description/)
- 
+ 
```java
private boolean[][] rowsUsed = new boolean[9][10];
@@ -1253,7 +1253,7 @@ private int cubeNum(int i, int j) {
[Leetcode](https://leetcode.com/problems/n-queens/description/) / [力扣](https://leetcode-cn.com/problems/n-queens/description/)
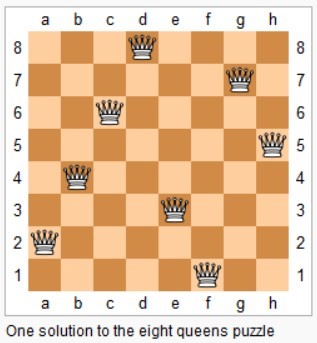
- 
+ 
在 n\*n 的矩阵中摆放 n 个皇后,并且每个皇后不能在同一行,同一列,同一对角线上,求所有的 n 皇后的解。
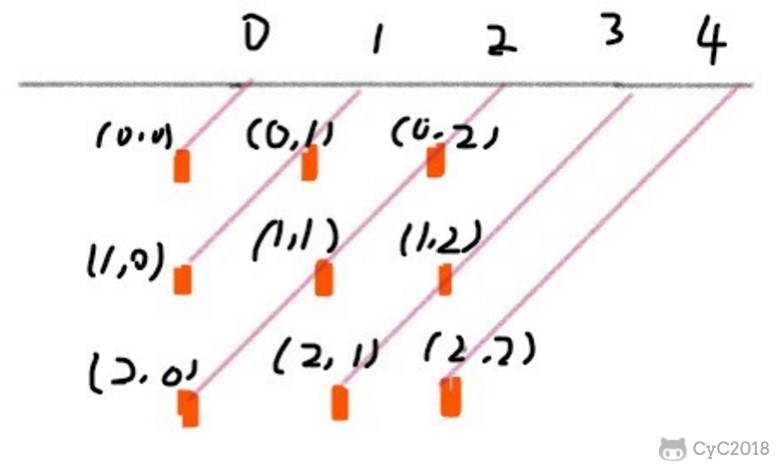
@@ -1261,12 +1261,12 @@ private int cubeNum(int i, int j) {
45 度对角线标记数组的长度为 2 \* n - 1,通过下图可以明确 (r, c) 的位置所在的数组下标为 r + c。
- 
+ 
135 度对角线标记数组的长度也是 2 \* n - 1,(r, c) 的位置所在的数组下标为 n - 1 - (r - c)。
- 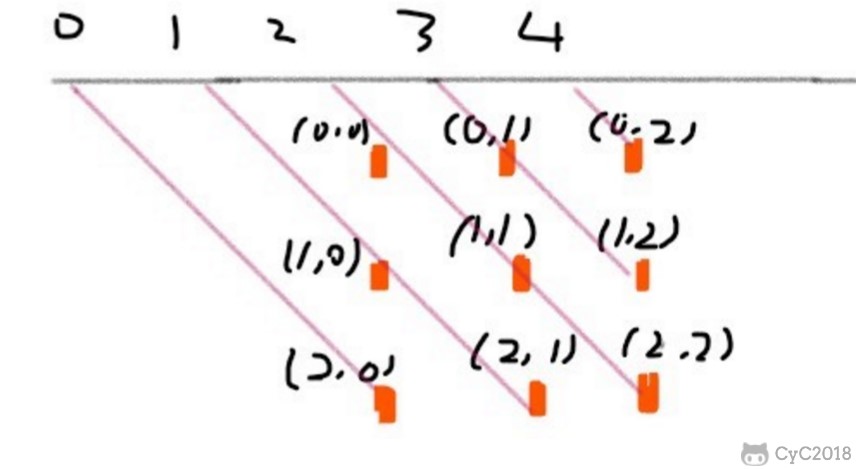
+ 
```java
private List> solutions;
diff --git a/docs/notes/Leetcode 题解 - 树.md b/docs/notes/Leetcode 题解 - 树.md
index e21daeea..70834503 100644
--- a/docs/notes/Leetcode 题解 - 树.md
+++ b/docs/notes/Leetcode 题解 - 树.md
@@ -1045,7 +1045,7 @@ private void inOrder(TreeNode node, List nums) {
# Trie
-
+
Trie,又称前缀树或字典树,用于判断字符串是否存在或者是否具有某种字符串前缀。
diff --git a/docs/notes/Leetcode 题解 - 贪心思想.md b/docs/notes/Leetcode 题解 - 贪心思想.md
index f75bddc9..9a9a20fd 100644
--- a/docs/notes/Leetcode 题解 - 贪心思想.md
+++ b/docs/notes/Leetcode 题解 - 贪心思想.md
@@ -35,7 +35,7 @@ Output: 2
证明:假设在某次选择中,贪心策略选择给当前满足度最小的孩子分配第 m 个饼干,第 m 个饼干为可以满足该孩子的最小饼干。假设存在一种最优策略,可以给该孩子分配第 n 个饼干,并且 m < n。我们可以发现,经过这一轮分配,贪心策略分配后剩下的饼干一定有一个比最优策略来得大。因此在后续的分配中,贪心策略一定能满足更多的孩子。也就是说不存在比贪心策略更优的策略,即贪心策略就是最优策略。
-
+
```java
public int findContentChildren(int[] grid, int[] size) {
diff --git a/docs/notes/Linux.md b/docs/notes/Linux.md
index b1ba8c58..924d87c4 100644
--- a/docs/notes/Linux.md
+++ b/docs/notes/Linux.md
@@ -165,7 +165,7 @@ Linux 发行版是 Linux 内核及各种应用软件的集成版本。
- 编辑模式(Insert mode):按下 "i" 等按键之后进入,可以对文本进行编辑;
- 指令列模式(Bottom-line mode):按下 ":" 按键之后进入,用于保存退出等操作。
-
+
在指令列模式下,有以下命令用于离开或者保存文件。
@@ -199,25 +199,25 @@ GNU 计划,译为革奴计划,它的目标是创建一套完全自由的操
IDE(ATA)全称 Advanced Technology Attachment,接口速度最大为 133MB/s,因为并口线的抗干扰性太差,且排线占用空间较大,不利电脑内部散热,已逐渐被 SATA 所取代。
-
+
### 2. SATA
SATA 全称 Serial ATA,也就是使用串口的 ATA 接口,抗干扰性强,且对数据线的长度要求比 ATA 低很多,支持热插拔等功能。SATA-II 的接口速度为 300MiB/s,而 SATA-III 标准可达到 600MiB/s 的传输速度。SATA 的数据线也比 ATA 的细得多,有利于机箱内的空气流通,整理线材也比较方便。
-
+
### 3. SCSI
SCSI 全称是 Small Computer System Interface(小型机系统接口),SCSI 硬盘广为工作站以及个人电脑以及服务器所使用,因此会使用较为先进的技术,如碟片转速 15000rpm 的高转速,且传输时 CPU 占用率较低,但是单价也比相同容量的 ATA 及 SATA 硬盘更加昂贵。
-
+
### 4. SAS
SAS(Serial Attached SCSI)是新一代的 SCSI 技术,和 SATA 硬盘相同,都是采取序列式技术以获得更高的传输速度,可达到 6Gb/s。此外也通过缩小连接线改善系统内部空间等。
-
+
## 磁盘的文件名
@@ -252,7 +252,7 @@ GPT 没有扩展分区概念,都是主分区,每个 LBA 可以分 4 个分
MBR 不支持 2.2 TB 以上的硬盘,GPT 则最多支持到 233 TB = 8 ZB。
-
+
## 开机检测程序
@@ -260,7 +260,7 @@ MBR 不支持 2.2 TB 以上的硬盘,GPT 则最多支持到 233 TB
BIOS(Basic Input/Output System,基本输入输出系统),它是一个固件(嵌入在硬件中的软件),BIOS 程序存放在断电后内容不会丢失的只读内存中。
-
+
BIOS 是开机的时候计算机执行的第一个程序,这个程序知道可以开机的磁盘,并读取磁盘第一个扇区的主要开机记录(MBR),由主要开机记录(MBR)执行其中的开机管理程序,这个开机管理程序会加载操作系统的核心文件。
@@ -268,7 +268,7 @@ BIOS 是开机的时候计算机执行的第一个程序,这个程序知道可
下图中,第一扇区的主要开机记录(MBR)中的开机管理程序提供了两个选单:M1、M2,M1 指向了 Windows 操作系统,而 M2 指向其它分区的启动扇区,里面包含了另外一个开机管理程序,提供了一个指向 Linux 的选单。
-
+
安装多重引导,最好先安装 Windows 再安装 Linux。因为安装 Windows 时会覆盖掉主要开机记录(MBR),而 Linux 可以选择将开机管理程序安装在主要开机记录(MBR)或者其它分区的启动扇区,并且可以设置开机管理程序的选单。
@@ -294,17 +294,17 @@ BIOS 不可以读取 GPT 分区表,而 UEFI 可以。
- superblock:记录文件系统的整体信息,包括 inode 和 block 的总量、使用量、剩余量,以及文件系统的格式与相关信息等;
- block bitmap:记录 block 是否被使用的位图。
-
+
## 文件读取
对于 Ext2 文件系统,当要读取一个文件的内容时,先在 inode 中查找文件内容所在的所有 block,然后把所有 block 的内容读出来。
-
+
而对于 FAT 文件系统,它没有 inode,每个 block 中存储着下一个 block 的编号。
-
+
## 磁盘碎片
@@ -341,7 +341,7 @@ inode 具有以下特点:
inode 中记录了文件内容所在的 block 编号,但是每个 block 非常小,一个大文件随便都需要几十万的 block。而一个 inode 大小有限,无法直接引用这么多 block 编号。因此引入了间接、双间接、三间接引用。间接引用让 inode 记录的引用 block 块记录引用信息。
-
+
## 目录
@@ -367,7 +367,7 @@ ext3/ext4 文件系统引入了日志功能,可以利用日志来修复文件
- /usr (unix software resource):所有系统默认软件都会安装到这个目录;
- /var (variable):存放系统或程序运行过程中的数据文件。
-
+
# 五、文件
@@ -534,7 +534,7 @@ cp [-adfilprsu] source destination
## 链接
-
+
```html
@@ -662,7 +662,7 @@ example: find . -name "shadow*"
+4、4 和 -4 的指示的时间范围如下:
-
+
**② 与文件拥有者和所属群组有关的选项**
@@ -1176,7 +1176,7 @@ dmtsai lines: 5 columns: 9
| T | stopped (either by a job control signal or because it is being traced)
结束,进程既可以被作业控制信号结束,也可能是正在被追踪。|
-
+
## SIGCHLD
@@ -1189,7 +1189,7 @@ dmtsai lines: 5 columns: 9
在子进程退出时,它的进程描述符不会立即释放,这是为了让父进程得到子进程信息,父进程通过 wait() 和 waitpid() 来获得一个已经退出的子进程的信息。
-
+
## wait()
diff --git a/docs/notes/MySQL.md b/docs/notes/MySQL.md
index 2239d48a..14da3201 100644
--- a/docs/notes/MySQL.md
+++ b/docs/notes/MySQL.md
@@ -42,7 +42,7 @@ B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具
在 B+ Tree 中,一个节点中的 key 从左到右非递减排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,且不为 null,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
-
+
### 2. 操作
@@ -84,11 +84,11 @@ B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具
InnoDB 的 B+Tree 索引分为主索引和辅助索引。主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
-
+
辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找。
-
+
### 2. 哈希索引
@@ -350,7 +350,7 @@ MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提
当一个表的数据不断增多时,Sharding 是必然的选择,它可以将数据分布到集群的不同节点上,从而缓存单个数据库的压力。
-
+
## 垂直切分
@@ -358,7 +358,7 @@ MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提
在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不同的库中,例如将原来的电商数据库垂直切分成商品数据库、用户数据库等。
-
+
## Sharding 策略
@@ -392,7 +392,7 @@ MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提
- **I/O 线程** :负责从主服务器上读取二进制日志,并写入从服务器的中继日志(Relay log)。
- **SQL 线程** :负责读取中继日志,解析出主服务器已经执行的数据更改并在从服务器中重放(Replay)。
-
+
## 读写分离
@@ -406,7 +406,7 @@ MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提
读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。
-
+
# 参考资料
diff --git a/docs/notes/Redis.md b/docs/notes/Redis.md
index a8b71352..38901f41 100644
--- a/docs/notes/Redis.md
+++ b/docs/notes/Redis.md
@@ -67,7 +67,7 @@ Redis 支持很多特性,例如将内存中的数据持久化到硬盘中,
## STRING
-
+
```html
> set hello world
@@ -82,7 +82,7 @@ OK
## LIST
-
+
```html
> rpush list-key item
@@ -110,7 +110,7 @@ OK
## SET
-
+
```html
> sadd set-key item
@@ -144,7 +144,7 @@ OK
## HASH
-
+
```html
> hset hash-key sub-key1 value1
@@ -175,7 +175,7 @@ OK
## ZSET
-
+
```html
> zadd zset-key 728 member1
@@ -317,11 +317,11 @@ int dictRehash(dict *d, int n) {
跳跃表是基于多指针有序链表实现的,可以看成多个有序链表。
-
+
在查找时,从上层指针开始查找,找到对应的区间之后再到下一层去查找。下图演示了查找 22 的过程。
-
+
与红黑树等平衡树相比,跳跃表具有以下优点:
@@ -472,7 +472,7 @@ Redis 服务器是一个事件驱动程序。
Redis 基于 Reactor 模式开发了自己的网络事件处理器,使用 I/O 多路复用程序来同时监听多个套接字,并将到达的事件传送给文件事件分派器,分派器会根据套接字产生的事件类型调用相应的事件处理器。
-
+
## 时间事件
@@ -525,7 +525,7 @@ def main():
从事件处理的角度来看,服务器运行流程如下:
-
+
# 十一、复制
@@ -545,7 +545,7 @@ def main():
随着负载不断上升,主服务器可能无法很快地更新所有从服务器,或者重新连接和重新同步从服务器将导致系统超载。为了解决这个问题,可以创建一个中间层来分担主服务器的复制工作。中间层的服务器是最上层服务器的从服务器,又是最下层服务器的主服务器。
-
+
# 十二、Sentinel
@@ -580,7 +580,7 @@ Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入
Redis 没有关系型数据库中的表这一概念来将同种类型的数据存放在一起,而是使用命名空间的方式来实现这一功能。键名的前面部分存储命名空间,后面部分的内容存储 ID,通常使用 : 来进行分隔。例如下面的 HASH 的键名为 article:92617,其中 article 为命名空间,ID 为 92617。
-
+
## 点赞功能
@@ -588,13 +588,13 @@ Redis 没有关系型数据库中的表这一概念来将同种类型的数据
为了节约内存,规定一篇文章发布满一周之后,就不能再对它进行投票,而文章的已投票集合也会被删除,可以为文章的已投票集合设置一个一周的过期时间就能实现这个规定。
-
+
## 对文章进行排序
为了按发布时间和点赞数进行排序,可以建立一个文章发布时间的有序集合和一个文章点赞数的有序集合。(下图中的 score 就是这里所说的点赞数;下面所示的有序集合分值并不直接是时间和点赞数,而是根据时间和点赞数间接计算出来的)
-
+
# 参考资料
diff --git a/docs/notes/Socket.md b/docs/notes/Socket.md
index 64fc6300..5dc40ed8 100644
--- a/docs/notes/Socket.md
+++ b/docs/notes/Socket.md
@@ -46,7 +46,7 @@ Unix 有五种 I/O 模型:
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);
```
-
+
## 非阻塞式 I/O
@@ -54,7 +54,7 @@ ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *
由于 CPU 要处理更多的系统调用,因此这种模型的 CPU 利用率比较低。
-
+
## I/O 复用
@@ -64,7 +64,7 @@ ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *
如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket 连接都需要创建一个线程去处理。如果同时有几万个连接,那么就需要创建相同数量的线程。相比于多进程和多线程技术,I/O 复用不需要进程线程创建和切换的开销,系统开销更小。
-
+
## 信号驱动 I/O
@@ -72,7 +72,7 @@ ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高。
-
+
## 异步 I/O
@@ -80,7 +80,7 @@ ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O。
-
+
## 五大 I/O 模型比较
@@ -91,7 +91,7 @@ ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *
非阻塞式 I/O 、信号驱动 I/O 和异步 I/O 在第一阶段不会阻塞。
-
+
# 二、I/O 复用
diff --git a/docs/notes/代码可读性.md b/docs/notes/代码可读性.md
index 09a932d7..475bbc56 100644
--- a/docs/notes/代码可读性.md
+++ b/docs/notes/代码可读性.md
@@ -48,11 +48,11 @@
- 用 min、max 表示数量范围;
- 用 first、last 表示访问空间的包含范围;
-
+
- begin、end 表示访问空间的排除范围,即 end 不包含尾部。
-
+
# 四、良好的代码风格
diff --git a/docs/notes/分布式.md b/docs/notes/分布式.md
index cee7f705..bf23703c 100644
--- a/docs/notes/分布式.md
+++ b/docs/notes/分布式.md
@@ -70,7 +70,7 @@ EXPIRE 指令可以为一个键值对设置一个过期时间,从而避免了
Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节点为 /app1。
-
+
### 2. 节点类型
@@ -118,7 +118,7 @@ Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节
协调者询问参与者事务是否执行成功,参与者发回事务执行结果。询问可以看成一种投票,需要参与者都同意才能执行。
-
+
#### 1.2 提交阶段
@@ -126,7 +126,7 @@ Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节
需要注意的是,在准备阶段,参与者执行了事务,但是还未提交。只有在提交阶段接收到协调者发来的通知后,才进行提交或者回滚。
-
+
### 2. 存在的问题
@@ -154,14 +154,14 @@ Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节
2. 之后将本地消息表中的消息转发到消息队列中,如果转发成功则将消息从本地消息表中删除,否则继续重新转发。
3. 在分布式事务操作的另一方从消息队列中读取一个消息,并执行消息中的操作。
-
+
# 三、CAP
分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)和分区容忍性(P:Partition Tolerance),最多只能同时满足其中两项。
-
+
## 一致性
@@ -225,7 +225,7 @@ ACID 要求强一致性,通常运用在传统的数据库系统上。而 BASE
- 接受者(Acceptor):对每个提议进行投票;
- 告知者(Learner):被告知投票的结果,不参与投票过程。
-
+
## 执行过程
@@ -235,19 +235,19 @@ ACID 要求强一致性,通常运用在传统的数据库系统上。而 BASE
下图演示了两个 Proposer 和三个 Acceptor 的系统中运行该算法的初始过程,每个 Proposer 都会向所有 Acceptor 发送 Prepare 请求。
-
+
当 Acceptor 接收到一个 Prepare 请求,包含的提议为 [n1, v1],并且之前还未接收过 Prepare 请求,那么发送一个 Prepare 响应,设置当前接收到的提议为 [n1, v1],并且保证以后不会再接受序号小于 n1 的提议。
如下图,Acceptor X 在收到 [n=2, v=8] 的 Prepare 请求时,由于之前没有接收过提议,因此就发送一个 [no previous] 的 Prepare 响应,设置当前接收到的提议为 [n=2, v=8],并且保证以后不会再接受序号小于 2 的提议。其它的 Acceptor 类似。
-
+
如果 Acceptor 接收到一个 Prepare 请求,包含的提议为 [n2, v2],并且之前已经接收过提议 [n1, v1]。如果 n1 > n2,那么就丢弃该提议请求;否则,发送 Prepare 响应,该 Prepare 响应包含之前已经接收过的提议 [n1, v1],设置当前接收到的提议为 [n2, v2],并且保证以后不会再接受序号小于 n2 的提议。
如下图,Acceptor Z 收到 Proposer A 发来的 [n=2, v=8] 的 Prepare 请求,由于之前已经接收过 [n=4, v=5] 的提议,并且 n > 2,因此就抛弃该提议请求;Acceptor X 收到 Proposer B 发来的 [n=4, v=5] 的 Prepare 请求,因为之前接收到的提议为 [n=2, v=8],并且 2 <= 4,因此就发送 [n=2, v=8] 的 Prepare 响应,设置当前接收到的提议为 [n=4, v=5],并且保证以后不会再接受序号小于 4 的提议。Acceptor Y 类似。
-
+
### 2. Accept 阶段
@@ -257,13 +257,13 @@ Proposer A 接收到两个 Prepare 响应之后,就发送 [n=2, v=8] Accept
Proposer B 过后也收到了两个 Prepare 响应,因此也开始发送 Accept 请求。需要注意的是,Accept 请求的 v 需要取它收到的最大提议编号对应的 v 值,也就是 8。因此它发送 [n=4, v=8] 的 Accept 请求。
-
+
### 3. Learn 阶段
Acceptor 接收到 Accept 请求时,如果序号大于等于该 Acceptor 承诺的最小序号,那么就发送 Learn 提议给所有的 Learner。当 Learner 发现有大多数的 Acceptor 接收了某个提议,那么该提议的提议值就被 Paxos 选择出来。
-
+
## 约束条件
@@ -291,47 +291,47 @@ Raft 也是分布式一致性协议,主要是用来竞选主节点。
- 下图展示一个分布式系统的最初阶段,此时只有 Follower 没有 Leader。Node A 等待一个随机的竞选超时时间之后,没收到 Leader 发来的心跳包,因此进入竞选阶段。
-
+
- 此时 Node A 发送投票请求给其它所有节点。
-
+
- 其它节点会对请求进行回复,如果超过一半的节点回复了,那么该 Candidate 就会变成 Leader。
-
+
- 之后 Leader 会周期性地发送心跳包给 Follower,Follower 接收到心跳包,会重新开始计时。
-
+
## 多个 Candidate 竞选
- 如果有多个 Follower 成为 Candidate,并且所获得票数相同,那么就需要重新开始投票。例如下图中 Node B 和 Node D 都获得两票,需要重新开始投票。
-
+
- 由于每个节点设置的随机竞选超时时间不同,因此下一次再次出现多个 Candidate 并获得同样票数的概率很低。
-
+
## 数据同步
- 来自客户端的修改都会被传入 Leader。注意该修改还未被提交,只是写入日志中。
-
+
- Leader 会把修改复制到所有 Follower。
-
+
- Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。
-
+
- 此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。
-
+
# 参考
diff --git a/docs/notes/剑指 Offer 题解 - 10~19.md b/docs/notes/剑指 Offer 题解 - 10~19.md
index 1b40238c..46931b58 100644
--- a/docs/notes/剑指 Offer 题解 - 10~19.md
+++ b/docs/notes/剑指 Offer 题解 - 10~19.md
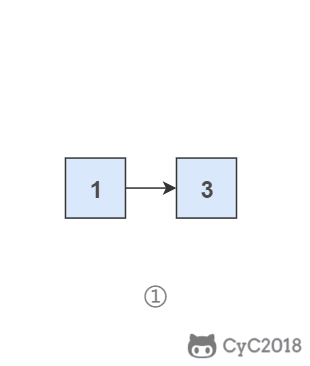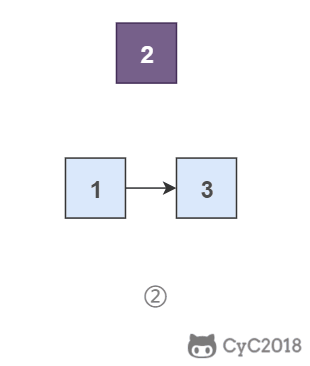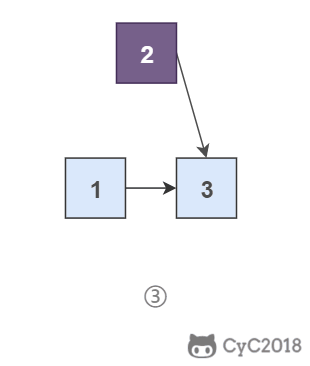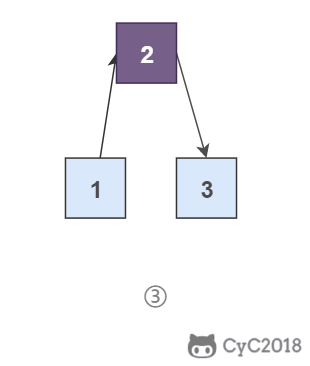
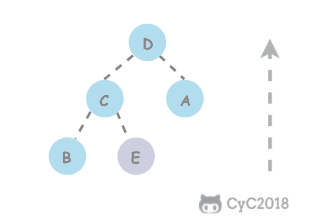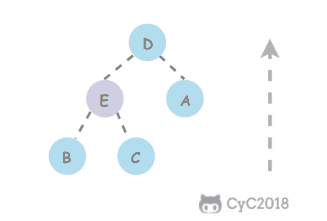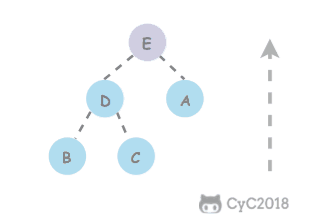
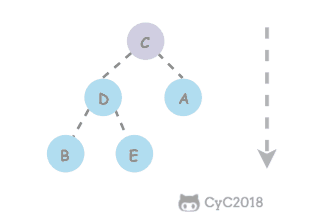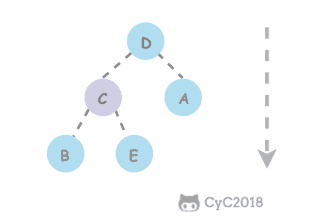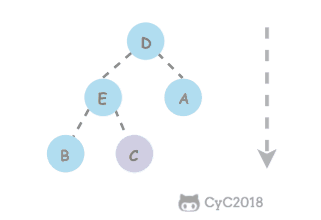
@@ -26,13 +26,13 @@
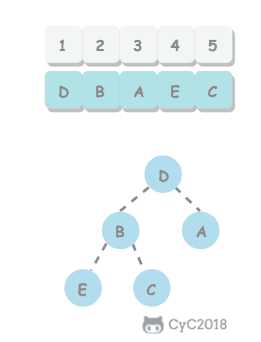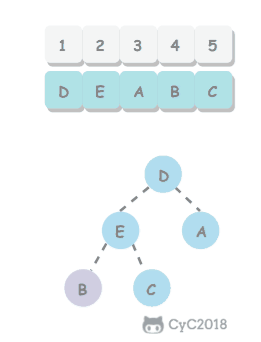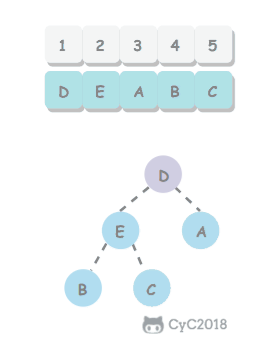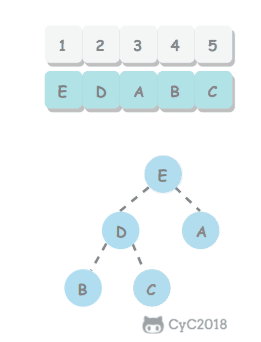
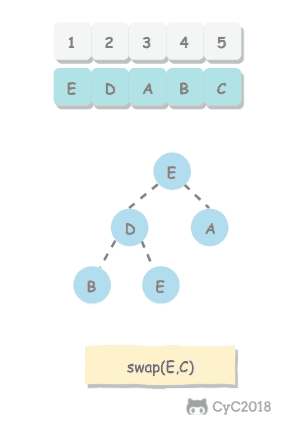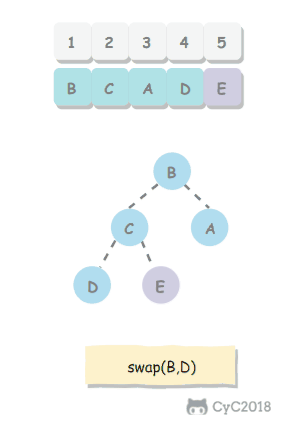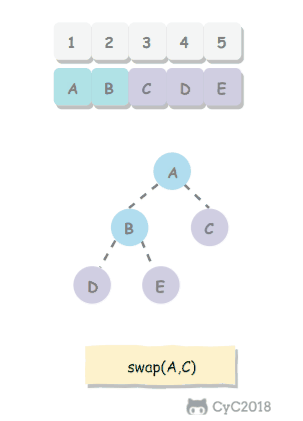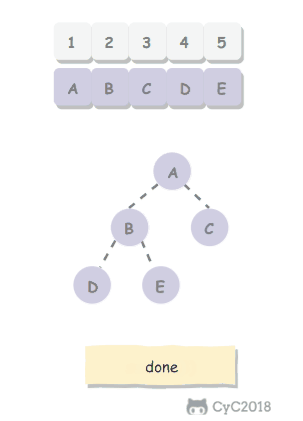
-
+
## 解题思路
如果使用递归求解,会重复计算一些子问题。例如,计算 f(4) 需要计算 f(3) 和 f(2),计算 f(3) 需要计算 f(2) 和 f(1),可以看到 f(2) 被重复计算了。
-
+
递归是将一个问题划分成多个子问题求解,动态规划也是如此,但是动态规划会把子问题的解缓存起来,从而避免重复求解子问题。
@@ -92,23 +92,23 @@ public class Solution {
我们可以用 2\*1 的小矩形横着或者竖着去覆盖更大的矩形。请问用 n 个 2\*1 的小矩形无重叠地覆盖一个 2\*n 的大矩形,总共有多少种方法?
-
+
## 解题思路
当 n 为 1 时,只有一种覆盖方法:
-
+
当 n 为 2 时,有两种覆盖方法:
-
+
要覆盖 2\*n 的大矩形,可以先覆盖 2\*1 的矩形,再覆盖 2\*(n-1) 的矩形;或者先覆盖 2\*2 的矩形,再覆盖 2\*(n-2) 的矩形。而覆盖 2\*(n-1) 和 2\*(n-2) 的矩形可以看成子问题。该问题的递推公式如下:
-
+
```java
public int RectCover(int n) {
@@ -133,21 +133,21 @@ public int RectCover(int n) {
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
-
+
## 解题思路
当 n = 1 时,只有一种跳法:
-
+
当 n = 2 时,有两种跳法:
-
+
跳 n 阶台阶,可以先跳 1 阶台阶,再跳 n-1 阶台阶;或者先跳 2 阶台阶,再跳 n-2 阶台阶。而 n-1 和 n-2 阶台阶的跳法可以看成子问题,该问题的递推公式为:
-
+
```java
public int JumpFloor(int n) {
@@ -172,7 +172,7 @@ public int JumpFloor(int n) {
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级... 它也可以跳上 n 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
-
+
## 解题思路
@@ -232,13 +232,13 @@ public int JumpFloorII(int target) {
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。
-
+
## 解题思路
将旋转数组对半分可以得到一个包含最小元素的新旋转数组,以及一个非递减排序的数组。新的旋转数组的数组元素是原数组的一半,从而将问题规模减少了一半,这种折半性质的算法的时间复杂度为 O(logN)(为了方便,这里将 log2N 写为 logN)。
-
+
此时问题的关键在于确定对半分得到的两个数组哪一个是旋转数组,哪一个是非递减数组。我们很容易知道非递减数组的第一个元素一定小于等于最后一个元素。
@@ -300,13 +300,13 @@ private int minNumber(int[] nums, int l, int h) {
例如下面的矩阵包含了一条 bfce 路径。
-
+
## 解题思路
使用回溯法(backtracking)进行求解,它是一种暴力搜索方法,通过搜索所有可能的结果来求解问题。回溯法在一次搜索结束时需要进行回溯(回退),将这一次搜索过程中设置的状态进行清除,从而开始一次新的搜索过程。例如下图示例中,从 f 开始,下一步有 4 种搜索可能,如果先搜索 b,需要将 b 标记为已经使用,防止重复使用。在这一次搜索结束之后,需要将 b 的已经使用状态清除,并搜索 c。
-
+
本题的输入是数组而不是矩阵(二维数组),因此需要先将数组转换成矩阵。
@@ -522,7 +522,7 @@ public int NumberOf1(int n) {
-
+
因为 (x\*x)n/2 可以通过递归求解,并且每次递归 n 都减小一半,因此整个算法的时间复杂度为 O(logN)。
@@ -592,11 +592,11 @@ private void printNumber(char[] number) {
① 如果该节点不是尾节点,那么可以直接将下一个节点的值赋给该节点,然后令该节点指向下下个节点,再删除下一个节点,时间复杂度为 O(1)。
-
+
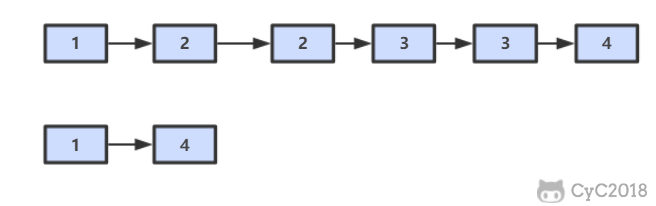
② 否则,就需要先遍历链表,找到节点的前一个节点,然后让前一个节点指向 null,时间复杂度为 O(N)。
-
+
综上,如果进行 N 次操作,那么大约需要操作节点的次数为 N-1+N=2N-1,其中 N-1 表示 N-1 个不是尾节点的每个节点以 O(1) 的时间复杂度操作节点的总次数,N 表示 1 个尾节点以 O(N) 的时间复杂度操作节点的总次数。(2N-1)/N \~ 2,因此该算法的平均时间复杂度为 O(1)。
@@ -630,7 +630,7 @@ public ListNode deleteNode(ListNode head, ListNode tobeDelete) {
## 题目描述
-
+
## 解题描述
diff --git a/docs/notes/剑指 Offer 题解 - 20~29.md b/docs/notes/剑指 Offer 题解 - 20~29.md
index 85438827..aff1be3c 100644
--- a/docs/notes/剑指 Offer 题解 - 20~29.md
+++ b/docs/notes/剑指 Offer 题解 - 20~29.md
@@ -70,7 +70,7 @@ public boolean isNumeric(char[] str) {
需要保证奇数和奇数,偶数和偶数之间的相对位置不变,这和书本不太一样。
-
+
## 解题思路
@@ -131,7 +131,7 @@ private void swap(int[] nums, int i, int j) {
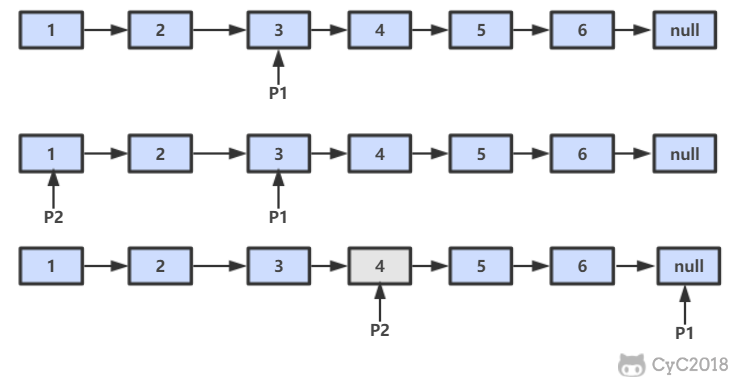
设链表的长度为 N。设置两个指针 P1 和 P2,先让 P1 移动 K 个节点,则还有 N - K 个节点可以移动。此时让 P1 和 P2 同时移动,可以知道当 P1 移动到链表结尾时,P2 移动到第 N - K 个节点处,该位置就是倒数第 K 个节点。
-
+
```java
public ListNode FindKthToTail(ListNode head, int k) {
@@ -165,7 +165,7 @@ public ListNode FindKthToTail(ListNode head, int k) {
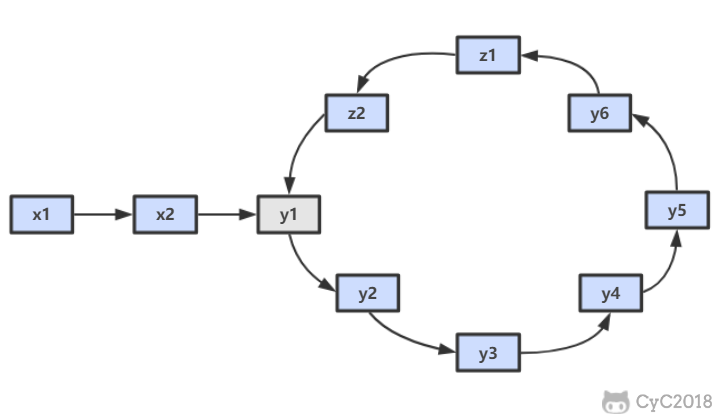
在相遇点,slow 要到环的入口点还需要移动 z 个节点,如果让 fast 重新从头开始移动,并且速度变为每次移动一个节点,那么它到环入口点还需要移动 x 个节点。在上面已经推导出 x=z,因此 fast 和 slow 将在环入口点相遇。
-
+
```java
public ListNode EntryNodeOfLoop(ListNode pHead) {
@@ -228,7 +228,7 @@ public ListNode ReverseList(ListNode head) {
## 题目描述
-
+
## 解题思路
@@ -280,7 +280,7 @@ public ListNode Merge(ListNode list1, ListNode list2) {
## 题目描述
-
+
## 解题思路
@@ -308,7 +308,7 @@ private boolean isSubtreeWithRoot(TreeNode root1, TreeNode root2) {
## 题目描述
-
+
## 解题思路
@@ -334,7 +334,7 @@ private void swap(TreeNode root) {
## 题目描述
-
+
## 解题思路
@@ -364,7 +364,7 @@ boolean isSymmetrical(TreeNode t1, TreeNode t2) {
下图的矩阵顺时针打印结果为:1, 2, 3, 4, 8, 12, 16, 15, 14, 13, 9, 5, 6, 7, 11, 10
-
+
## 解题思路
diff --git a/docs/notes/剑指 Offer 题解 - 30~39.md b/docs/notes/剑指 Offer 题解 - 30~39.md
index f8853033..d897d973 100644
--- a/docs/notes/剑指 Offer 题解 - 30~39.md
+++ b/docs/notes/剑指 Offer 题解 - 30~39.md
@@ -87,7 +87,7 @@ public boolean IsPopOrder(int[] pushSequence, int[] popSequence) {
例如,以下二叉树层次遍历的结果为:1,2,3,4,5,6,7
-
+
## 解题思路
@@ -195,7 +195,7 @@ public ArrayList> Print(TreeNode pRoot) {
例如,下图是后序遍历序列 1,3,2 所对应的二叉搜索树。
-
+
## 解题思路
@@ -230,7 +230,7 @@ private boolean verify(int[] sequence, int first, int last) {
下图的二叉树有两条和为 22 的路径:10, 5, 7 和 10, 12
-
+
## 解题思路
@@ -277,21 +277,21 @@ public class RandomListNode {
}
```
-
+
## 解题思路
第一步,在每个节点的后面插入复制的节点。
-
+
第二步,对复制节点的 random 链接进行赋值。
-
+
第三步,拆分。
-
+
```java
public RandomListNode Clone(RandomListNode pHead) {
@@ -333,7 +333,7 @@ public RandomListNode Clone(RandomListNode pHead) {
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。
-
+
## 解题思路
diff --git a/docs/notes/剑指 Offer 题解 - 3~9.md b/docs/notes/剑指 Offer 题解 - 3~9.md
index c0d701f7..2bcc5e84 100644
--- a/docs/notes/剑指 Offer 题解 - 3~9.md
+++ b/docs/notes/剑指 Offer 题解 - 3~9.md
@@ -33,7 +33,7 @@ Output:
以 (2, 3, 1, 0, 2, 5) 为例,遍历到位置 4 时,该位置上的数为 2,但是第 2 个位置上已经有一个 2 的值了,因此可以知道 2 重复:
- 
+ 
```java
@@ -87,7 +87,7 @@ Given target = 20, return false.
该二维数组中的一个数,小于它的数一定在其左边,大于它的数一定在其下边。因此,从右上角开始查找,就可以根据 target 和当前元素的大小关系来缩小查找区间,当前元素的查找区间为左下角的所有元素。
- 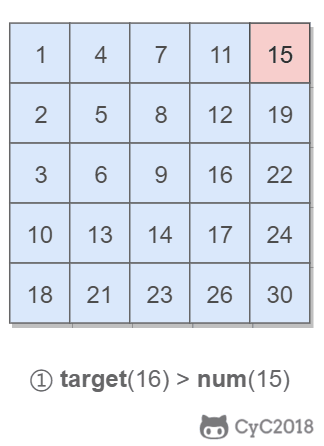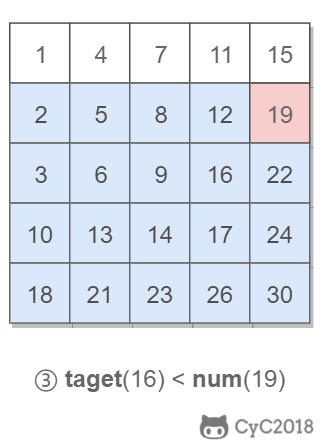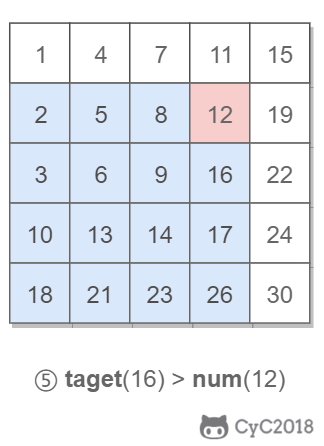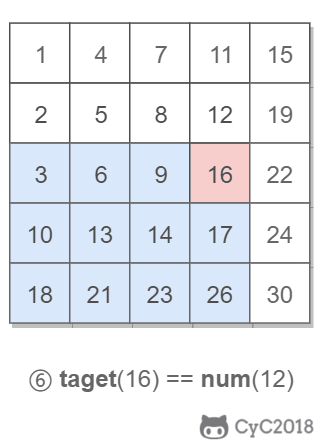
+ 
```java
public boolean Find(int target, int[][] matrix) {
@@ -132,7 +132,7 @@ Output:
从后向前遍是为了在改变 P2 所指向的内容时,不会影响到 P1 遍历原来字符串的内容。
- 
+ 
```java
public String replaceSpace(StringBuffer str) {
@@ -164,7 +164,7 @@ public String replaceSpace(StringBuffer str) {
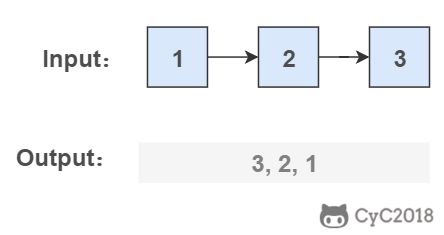
从尾到头反过来打印出每个结点的值。
-
+
## 解题思路
@@ -192,7 +192,7 @@ public ArrayList printListFromTailToHead(ListNode listNode) {
- 头结点是在头插法中使用的一个额外节点,这个节点不存储值;
- 第一个节点就是链表的第一个真正存储值的节点。
- 
+ 
```java
public ArrayList printListFromTailToHead(ListNode listNode) {
@@ -219,7 +219,7 @@ public ArrayList printListFromTailToHead(ListNode listNode) {
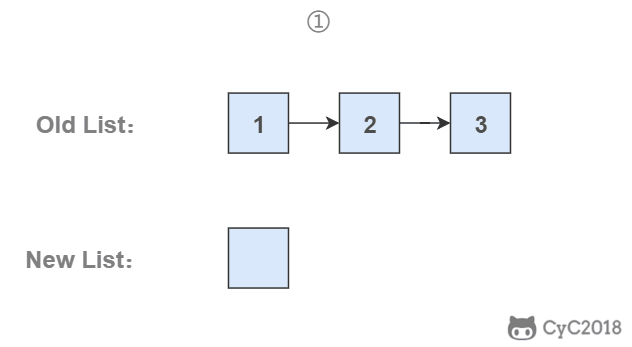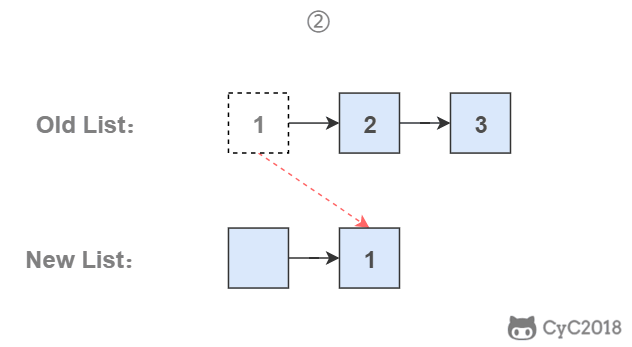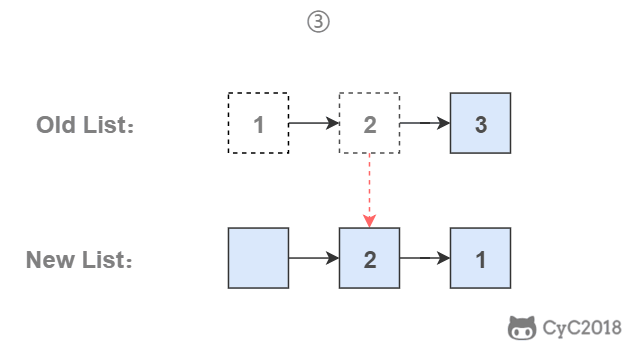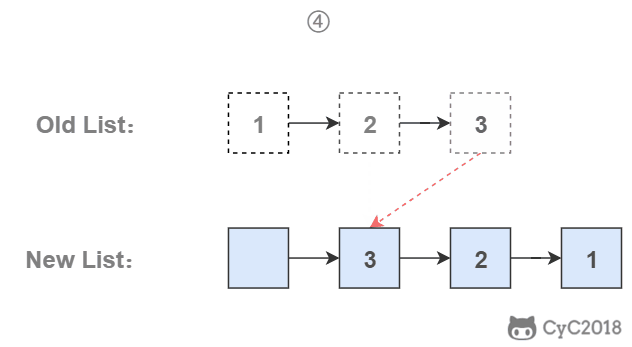
栈具有后进先出的特点,在遍历链表时将值按顺序放入栈中,最后出栈的顺序即为逆序。
-
+
```java
public ArrayList printListFromTailToHead(ListNode listNode) {
@@ -244,13 +244,13 @@ public ArrayList printListFromTailToHead(ListNode listNode) {
根据二叉树的前序遍历和中序遍历的结果,重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
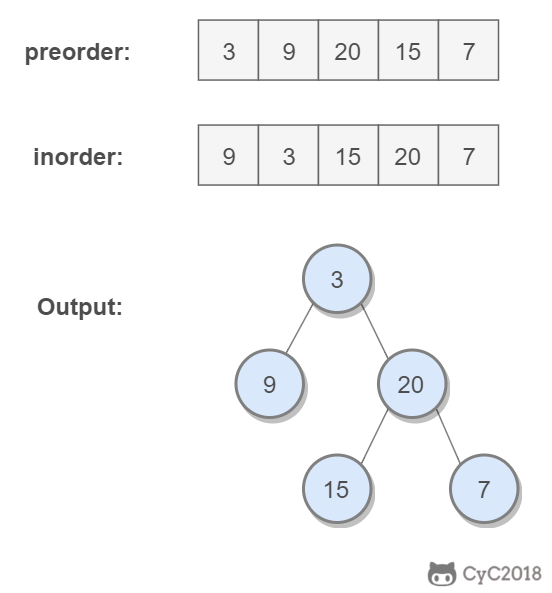
- 
+ 
## 解题思路
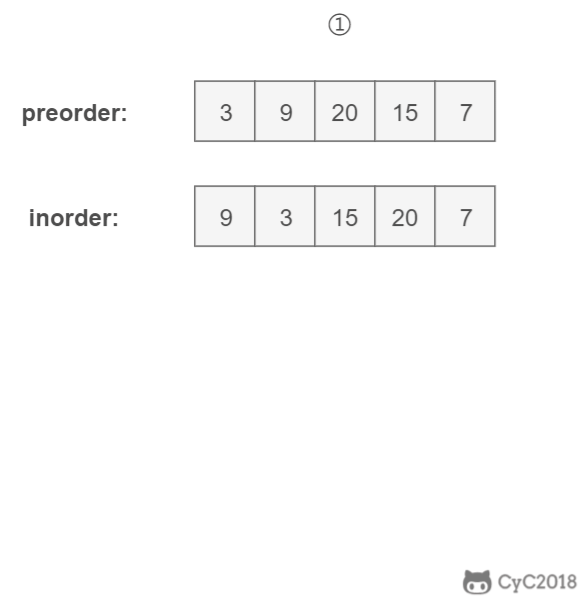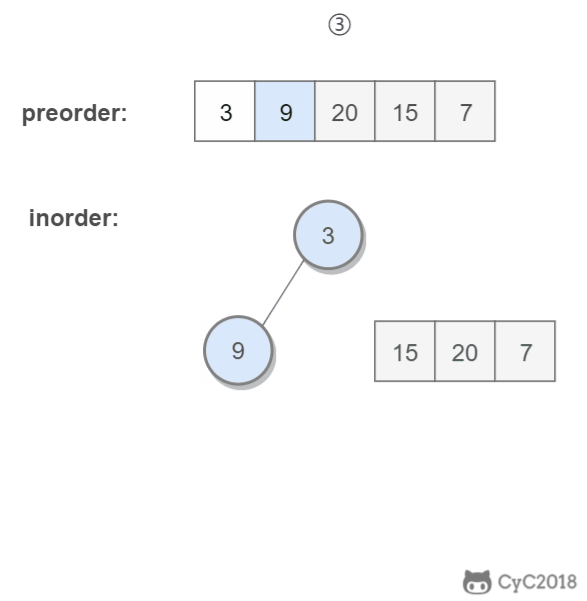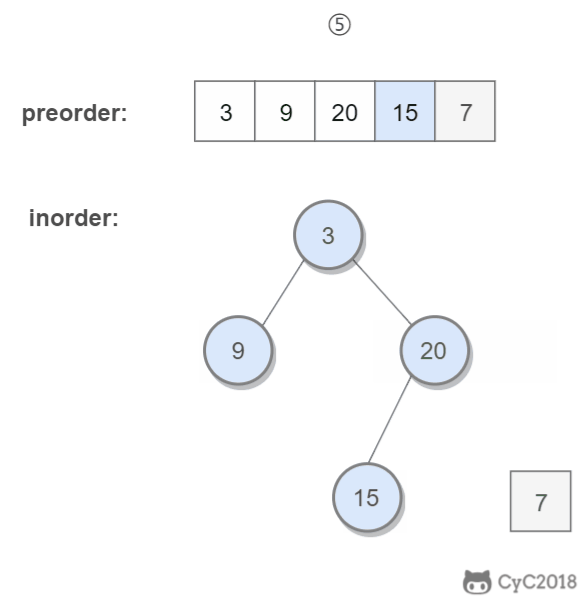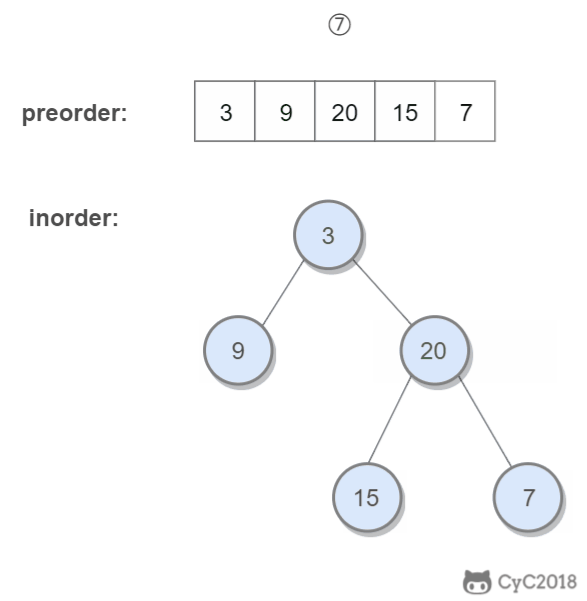
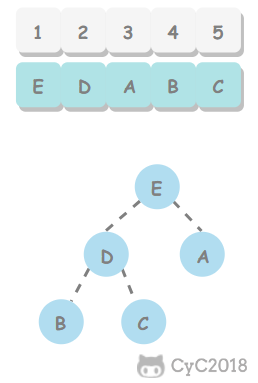
前序遍历的第一个值为根节点的值,使用这个值将中序遍历结果分成两部分,左部分为树的左子树中序遍历结果,右部分为树的右子树中序遍历的结果。
- 
+ 
```java
// 缓存中序遍历数组每个值对应的索引
@@ -300,11 +300,11 @@ public class TreeLinkNode {
① 如果一个节点的右子树不为空,那么该节点的下一个节点是右子树的最左节点;
- 
+ 
② 否则,向上找第一个左链接指向的树包含该节点的祖先节点。
- 
+ 
```java
public TreeLinkNode GetNext(TreeLinkNode pNode) {
@@ -337,7 +337,7 @@ public TreeLinkNode GetNext(TreeLinkNode pNode) {
in 栈用来处理入栈(push)操作,out 栈用来处理出栈(pop)操作。一个元素进入 in 栈之后,出栈的顺序被反转。当元素要出栈时,需要先进入 out 栈,此时元素出栈顺序再一次被反转,因此出栈顺序就和最开始入栈顺序是相同的,先进入的元素先退出,这就是队列的顺序。
-
+
```java
Stack in = new Stack();
diff --git a/docs/notes/剑指 Offer 题解 - 50~59.md b/docs/notes/剑指 Offer 题解 - 50~59.md
index ed3d610d..ab34a6d0 100644
--- a/docs/notes/剑指 Offer 题解 - 50~59.md
+++ b/docs/notes/剑指 Offer 题解 - 50~59.md
@@ -120,7 +120,7 @@ private void merge(int[] nums, int l, int m, int h) {
## 题目描述
-
+
## 解题思路
@@ -212,7 +212,7 @@ private void inOrder(TreeNode root, int k) {
从根结点到叶结点依次经过的结点(含根、叶结点)形成树的一条路径,最长路径的长度为树的深度。
-
+
## 解题思路
@@ -230,7 +230,7 @@ public int TreeDepth(TreeNode root) {
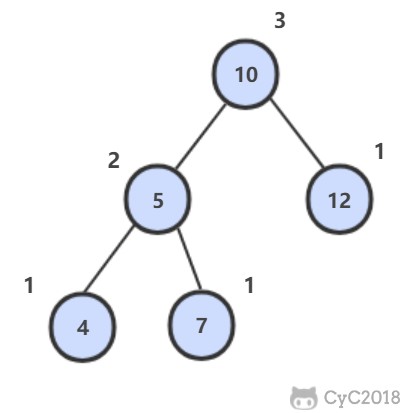
平衡二叉树左右子树高度差不超过 1。
-
+
## 解题思路
diff --git a/docs/notes/剑指 Offer 题解 - 60~68.md b/docs/notes/剑指 Offer 题解 - 60~68.md
index 1e9f9c31..053d4129 100644
--- a/docs/notes/剑指 Offer 题解 - 60~68.md
+++ b/docs/notes/剑指 Offer 题解 - 60~68.md
@@ -19,7 +19,7 @@
把 n 个骰子扔在地上,求点数和为 s 的概率。
-
+
## 解题思路
@@ -92,7 +92,7 @@ public List> dicesSum(int n) {
五张牌,其中大小鬼为癞子,牌面为 0。判断这五张牌是否能组成顺子。
-
+
## 解题思路
@@ -152,7 +152,7 @@ public int LastRemaining_Solution(int n, int m) {
可以有一次买入和一次卖出,买入必须在前。求最大收益。
-
+
## 解题思路
@@ -224,7 +224,7 @@ public int Add(int a, int b) {
给定一个数组 A[0, 1,..., n-1],请构建一个数组 B[0, 1,..., n-1],其中 B 中的元素 B[i]=A[0]\*A[1]\*...\*A[i-1]\*A[i+1]\*...\*A[n-1]。要求不能使用除法。
-
+
## 解题思路
@@ -289,7 +289,7 @@ public int StrToInt(String str) {
二叉查找树中,两个节点 p, q 的公共祖先 root 满足 root.val >= p.val && root.val <= q.val。
-
+
```java
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
@@ -309,7 +309,7 @@ public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
在左右子树中查找是否存在 p 或者 q,如果 p 和 q 分别在两个子树中,那么就说明根节点就是最低公共祖先。
-
+
```java
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
diff --git a/docs/notes/数据库系统原理.md b/docs/notes/数据库系统原理.md
index 949dddc1..32809000 100644
--- a/docs/notes/数据库系统原理.md
+++ b/docs/notes/数据库系统原理.md
@@ -47,7 +47,7 @@
事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。
-
+
## ACID
@@ -80,7 +80,7 @@
- 在并发的情况下,多个事务并行执行,事务不仅要满足原子性,还需要满足隔离性,才能满足一致性。
- 事务满足持久化是为了能应对数据库崩溃的情况。
-
+
## AUTOCOMMIT
@@ -94,25 +94,25 @@ MySQL 默认采用自动提交模式。也就是说,如果不显式使用`STAR
T1 和 T2 两个事务都对一个数据进行修改,T1 先修改,T2 随后修改,T2 的修改覆盖了 T1 的修改。
-
+
## 读脏数据
T1 修改一个数据,T2 随后读取这个数据。如果 T1 撤销了这次修改,那么 T2 读取的数据是脏数据。
-
+
## 不可重复读
T2 读取一个数据,T1 对该数据做了修改。如果 T2 再次读取这个数据,此时读取的结果和第一次读取的结果不同。
-
+
## 幻影读
T1 读取某个范围的数据,T2 在这个范围内插入新的数据,T1 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
- 
+ 
----
@@ -322,7 +322,7 @@ MVCC 在每行记录后面都保存着两个隐藏的列,用来存储两个版
MVCC 使用到的快照存储在 Undo 日志中,该日志通过回滚指针把一个数据行(Record)的所有快照连接起来。
- 
+ 
## 实现过程
@@ -536,7 +536,7 @@ Entity-Relationship,有三个组成部分:实体、属性、联系。
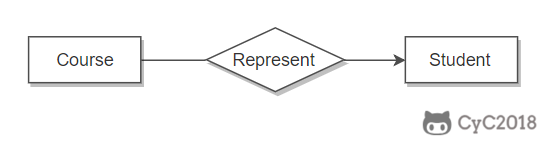
下图的 Course 和 Student 是一对多的关系。
- 
+ 
## 表示出现多次的关系
@@ -544,19 +544,19 @@ Entity-Relationship,有三个组成部分:实体、属性、联系。
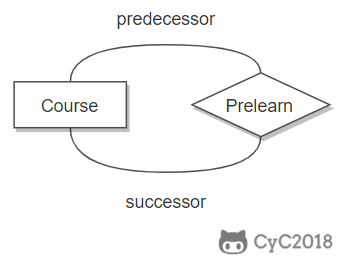
下图表示一个课程的先修关系,先修关系出现两个 Course 实体,第一个是先修课程,后一个是后修课程,因此需要用两条线来表示这种关系。
- 
+ 
## 联系的多向性
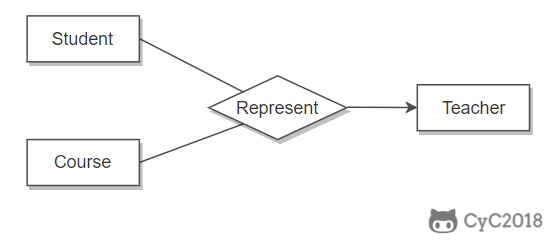
虽然老师可以开设多门课,并且可以教授多名学生,但是对于特定的学生和课程,只有一个老师教授,这就构成了一个三元联系。
- 
+ 
## 表示子类
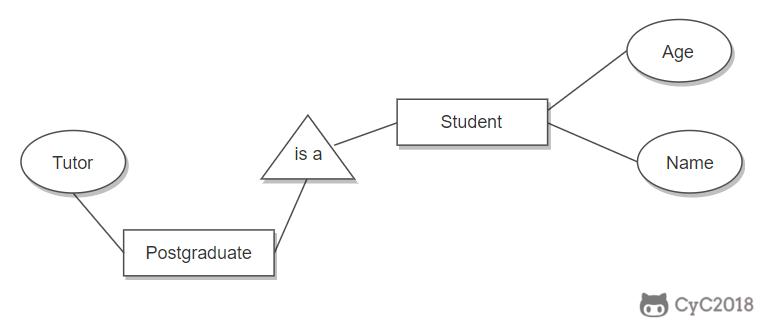
用一个三角形和两条线来连接类和子类,与子类有关的属性和联系都连到子类上,而与父类和子类都有关的连到父类上。
- 
+ 
# 参考资料
diff --git a/docs/notes/构建工具.md b/docs/notes/构建工具.md
index 4df876d8..15384384 100644
--- a/docs/notes/构建工具.md
+++ b/docs/notes/构建工具.md
@@ -35,7 +35,7 @@
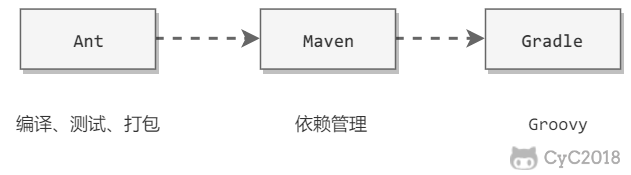
Ant 具有编译、测试和打包功能,其后出现的 Maven 在 Ant 的功能基础上又新增了依赖管理功能,而最新的 Gradle 又在 Maven 的功能基础上新增了对 Groovy 语言的支持。
- 
+ 
Gradle 和 Maven 的区别是,它使用 Groovy 这种特定领域语言(DSL)来管理构建脚本,而不再使用 XML 这种标记性语言。因为项目如果庞大的话,XML 很容易就变得臃肿。
diff --git a/docs/notes/正则表达式.md b/docs/notes/正则表达式.md
index c4d38ede..9d453df9 100644
--- a/docs/notes/正则表达式.md
+++ b/docs/notes/正则表达式.md
@@ -173,7 +173,7 @@ a.+c
^\s*\/\/.*$
```
- 
+ 
**匹配结果**
diff --git a/docs/notes/消息队列.md b/docs/notes/消息队列.md
index 485e25bb..7ed64fdf 100644
--- a/docs/notes/消息队列.md
+++ b/docs/notes/消息队列.md
@@ -19,20 +19,20 @@
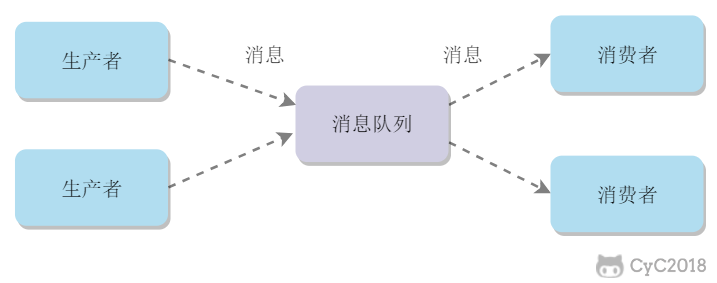
消息生产者向消息队列中发送了一个消息之后,只能被一个消费者消费一次。
- 
+ 
## 发布/订阅
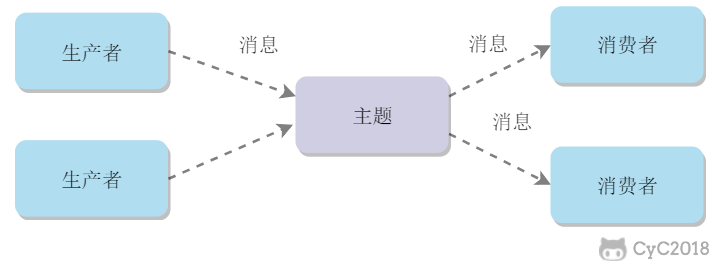
消息生产者向频道发送一个消息之后,多个消费者可以从该频道订阅到这条消息并消费。
- 
+ 
发布与订阅模式和观察者模式有以下不同:
- 观察者模式中,观察者和主题都知道对方的存在;而在发布与订阅模式中,生产者与消费者不知道对方的存在,它们之间通过频道进行通信。
- 观察者模式是同步的,当事件触发时,主题会调用观察者的方法,然后等待方法返回;而发布与订阅模式是异步的,生产者向频道发送一个消息之后,就不需要关心消费者何时去订阅这个消息,可以立即返回。
- 
+ 
# 二、使用场景
diff --git a/docs/notes/算法 - 其它.md b/docs/notes/算法 - 其它.md
index 7969ca1f..aad5fbdc 100644
--- a/docs/notes/算法 - 其它.md
+++ b/docs/notes/算法 - 其它.md
@@ -1,6 +1,6 @@
# 汉诺塔
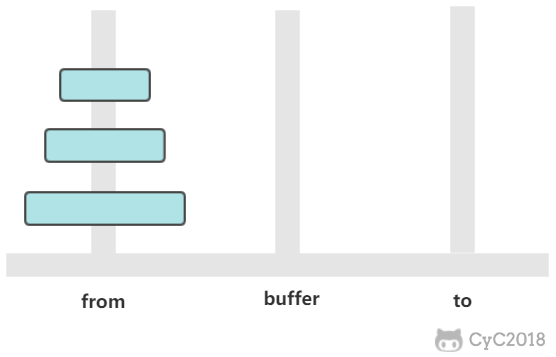
- 
+ 
有三个柱子,分别为 from、buffer、to。需要将 from 上的圆盘全部移动到 to 上,并且要保证小圆盘始终在大圆盘上。
@@ -8,15 +8,15 @@
① 将 n-1 个圆盘从 from -> buffer
- 
+ 
② 将 1 个圆盘从 from -> to
- 
+ 
③ 将 n-1 个圆盘从 buffer -> to
- 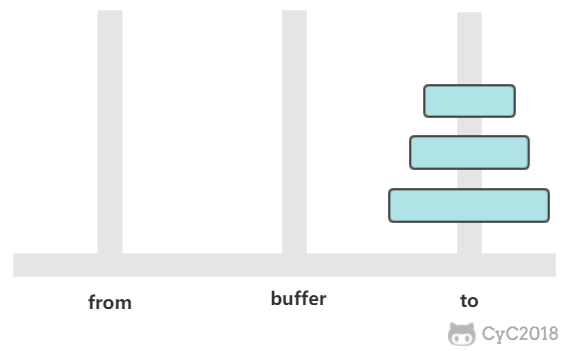
+ 
如果只有一个圆盘,那么只需要进行一次移动操作。
@@ -67,7 +67,7 @@ from H1 to H3
生成编码时,从根节点出发,向左遍历则添加二进制位 0,向右则添加二进制位 1,直到遍历到叶子节点,叶子节点代表的字符的编码就是这个路径编码。
- 
+ 
```java
public class Huffman {
diff --git a/docs/notes/算法 - 并查集.md b/docs/notes/算法 - 并查集.md
index e9995282..ca293d14 100644
--- a/docs/notes/算法 - 并查集.md
+++ b/docs/notes/算法 - 并查集.md
@@ -12,7 +12,7 @@
用于解决动态连通性问题,能动态连接两个点,并且判断两个点是否连通。
- 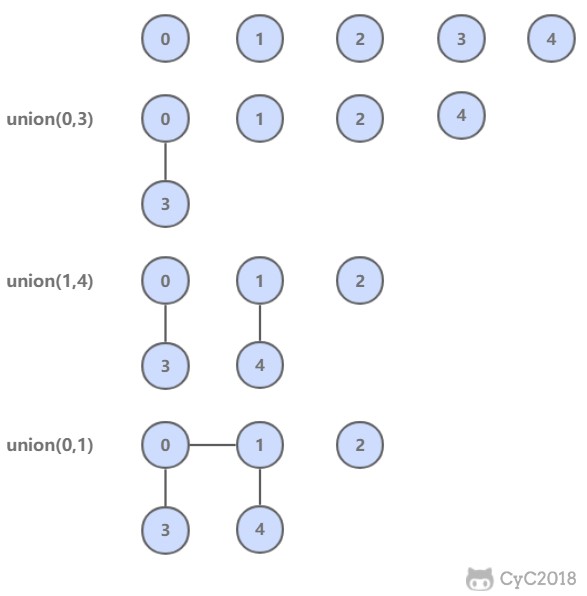
+ 
| 方法 | 描述 |
| :---: | :---: |
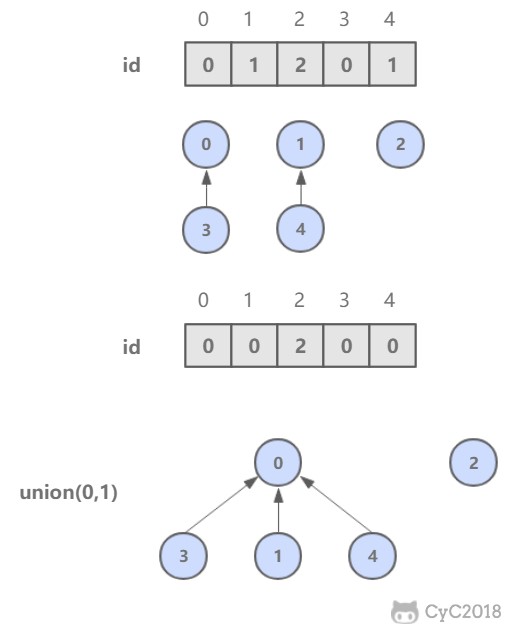
@@ -51,7 +51,7 @@ public abstract class UF {
但是 union 操作代价却很高,需要将其中一个连通分量中的所有节点 id 值都修改为另一个节点的 id 值。
- 
+ 
```java
public class QuickFindUF extends UF {
@@ -91,7 +91,7 @@ public class QuickFindUF extends UF {
但是 find 操作开销很大,因为同一个连通分量的节点 id 值不同,id 值只是用来指向另一个节点。因此需要一直向上查找操作,直到找到最上层的节点。
- 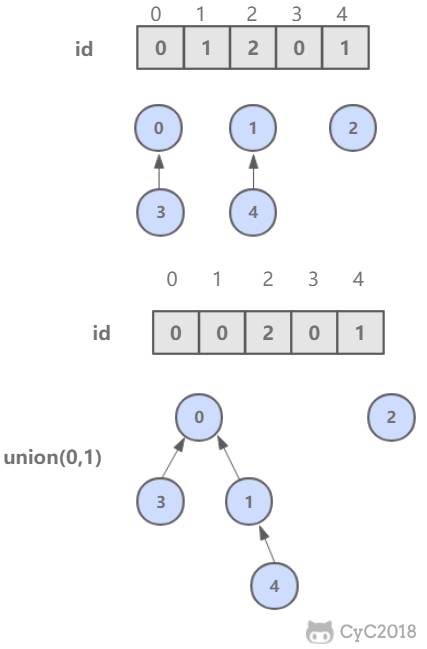
+ 
```java
public class QuickUnionUF extends UF {
@@ -124,7 +124,7 @@ public class QuickUnionUF extends UF {
这种方法可以快速进行 union 操作,但是 find 操作和树高成正比,最坏的情况下树的高度为节点的数目。
- 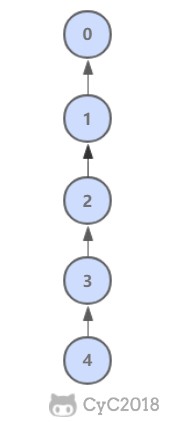
+ 
# 加权 Quick Union
@@ -132,7 +132,7 @@ public class QuickUnionUF extends UF {
理论研究证明,加权 quick-union 算法构造的树深度最多不超过 logN。
- 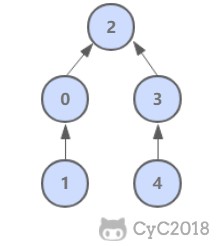
+ 
```java
public class WeightedQuickUnionUF extends UF {
diff --git a/docs/notes/算法 - 排序.md b/docs/notes/算法 - 排序.md
index b520d1f7..2d89334d 100644
--- a/docs/notes/算法 - 排序.md
+++ b/docs/notes/算法 - 排序.md
@@ -29,7 +29,7 @@ public abstract class Sort> {
选择排序需要 \~N2/2 次比较和 \~N 次交换,它的运行时间与输入无关,这个特点使得它对一个已经排序的数组也需要这么多的比较和交换操作。
- 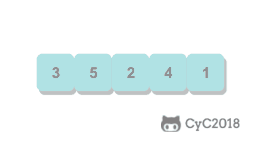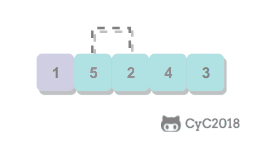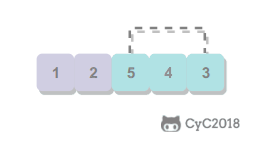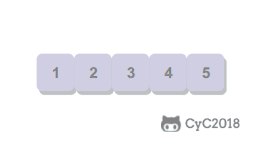
+ 
```java
public class Selection> extends Sort {
@@ -56,7 +56,7 @@ public class Selection> extends Sort {
在一轮循环中,如果没有发生交换,那么说明数组已经是有序的,此时可以直接退出。
- 
+ 
```java
public class Bubble> extends Sort {
@@ -90,7 +90,7 @@ public class Bubble> extends Sort {
- 最坏的情况下需要 \~N2/2 比较以及 \~N2/2 次交换,最坏的情况是数组是倒序的;
- 最好的情况下需要 N-1 次比较和 0 次交换,最好的情况就是数组已经有序了。
- 
+ 
```java
public class Insertion> extends Sort {
@@ -113,7 +113,7 @@ public class Insertion> extends Sort {
希尔排序使用插入排序对间隔 h 的序列进行排序。通过不断减小 h,最后令 h=1,就可以使得整个数组是有序的。
- 
+ 
```java
public class Shell> extends Sort {
@@ -147,7 +147,7 @@ public class Shell> extends Sort {
归并排序的思想是将数组分成两部分,分别进行排序,然后归并起来。
- 
+ 
## 1. 归并方法
@@ -243,7 +243,7 @@ public class Down2UpMergeSort> extends MergeSort {
- 归并排序将数组分为两个子数组分别排序,并将有序的子数组归并使得整个数组排序;
- 快速排序通过一个切分元素将数组分为两个子数组,左子数组小于等于切分元素,右子数组大于等于切分元素,将这两个子数组排序也就将整个数组排序了。
- 
+ 
```java
public class QuickSort> extends Sort {
@@ -274,7 +274,7 @@ public class QuickSort> extends Sort {
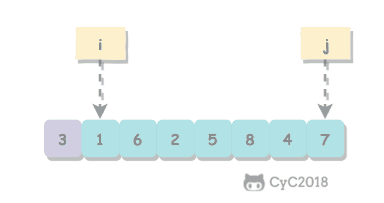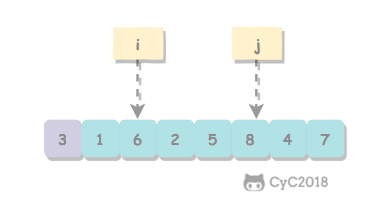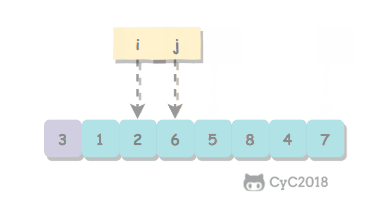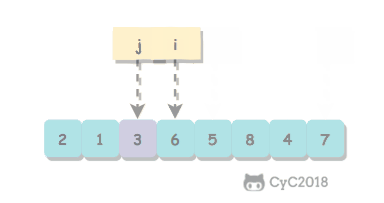
取 a[l] 作为切分元素,然后从数组的左端向右扫描直到找到第一个大于等于它的元素,再从数组的右端向左扫描找到第一个小于它的元素,交换这两个元素。不断进行这个过程,就可以保证左指针 i 的左侧元素都不大于切分元素,右指针 j 的右侧元素都不小于切分元素。当两个指针相遇时,将切分元素 a[l] 和 a[j] 交换位置。
- 
+ 
```java
private int partition(T[] nums, int l, int h) {
@@ -378,7 +378,7 @@ public T select(T[] nums, int k) {
堆可以用数组来表示,这是因为堆是完全二叉树,而完全二叉树很容易就存储在数组中。位置 k 的节点的父节点位置为 k/2,而它的两个子节点的位置分别为 2k 和 2k+1。这里不使用数组索引为 0 的位置,是为了更清晰地描述节点的位置关系。
- 
+ 
```java
public class Heap> {
@@ -414,7 +414,7 @@ public class Heap> {
在堆中,当一个节点比父节点大,那么需要交换这个两个节点。交换后还可能比它新的父节点大,因此需要不断地进行比较和交换操作,把这种操作称为上浮。
- 
+ 
```java
private void swim(int k) {
@@ -427,7 +427,7 @@ private void swim(int k) {
类似地,当一个节点比子节点来得小,也需要不断地向下进行比较和交换操作,把这种操作称为下沉。一个节点如果有两个子节点,应当与两个子节点中最大那个节点进行交换。
- 
+ 
```java
private void sink(int k) {
@@ -476,13 +476,13 @@ public T delMax() {
无序数组建立堆最直接的方法是从左到右遍历数组进行上浮操作。一个更高效的方法是从右至左进行下沉操作,如果一个节点的两个节点都已经是堆有序,那么进行下沉操作可以使得这个节点为根节点的堆有序。叶子节点不需要进行下沉操作,可以忽略叶子节点的元素,因此只需要遍历一半的元素即可。
- 
+ 
#### 5.2 交换堆顶元素与最后一个元素
交换之后需要进行下沉操作维持堆的有序状态。
- 
+ 
```java
public class HeapSort> extends Sort {
diff --git a/docs/notes/算法 - 符号表.md b/docs/notes/算法 - 符号表.md
index c2b23ca5..133ed8af 100644
--- a/docs/notes/算法 - 符号表.md
+++ b/docs/notes/算法 - 符号表.md
@@ -245,13 +245,13 @@ public class BinarySearchOrderedST, Value> implement
**二叉树** 是一个空链接,或者是一个有左右两个链接的节点,每个链接都指向一颗子二叉树。
- 
+ 
**二叉查找树** (BST)是一颗二叉树,并且每个节点的值都大于等于其左子树中的所有节点的值而小于等于右子树的所有节点的值。
BST 有一个重要性质,就是它的中序遍历结果递增排序。
- 
+ 
基本数据结构:
@@ -325,7 +325,7 @@ private Value get(Node x, Key key) {
当插入的键不存在于树中,需要创建一个新节点,并且更新上层节点的链接指向该节点,使得该节点正确地链接到树中。
- 
+ 
```java
@Override
@@ -354,11 +354,11 @@ private Node put(Node x, Key key, Value value) {
最好的情况下树是完全平衡的,每条空链接和根节点的距离都为 logN。
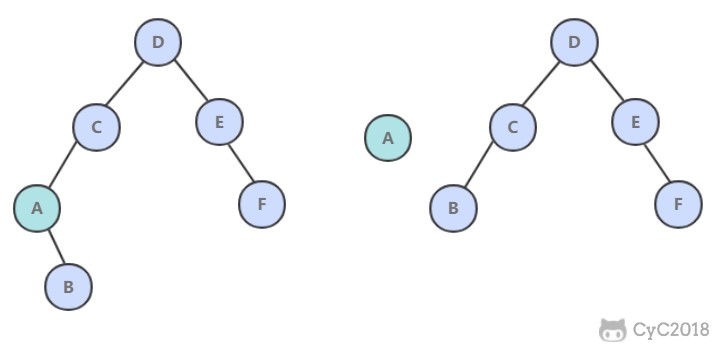
- 
+ 
在最坏的情况下,树的高度为 N。
- 
+ 
## 4. floor()
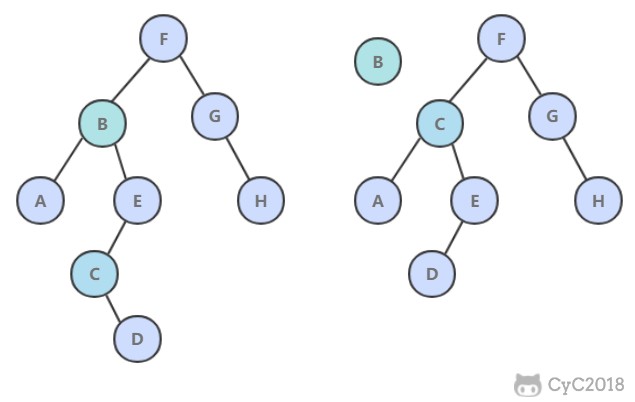
@@ -436,7 +436,7 @@ private Node min(Node x) {
令指向最小节点的链接指向最小节点的右子树。
- 
+ 
```java
public void deleteMin() {
@@ -457,7 +457,7 @@ public Node deleteMin(Node x) {
- 如果待删除的节点只有一个子树, 那么只需要让指向待删除节点的链接指向唯一的子树即可;
- 否则,让右子树的最小节点替换该节点。
- 
+ 
```java
public void delete(Key key) {
@@ -520,7 +520,7 @@ private List keys(Node x, Key l, Key h) {
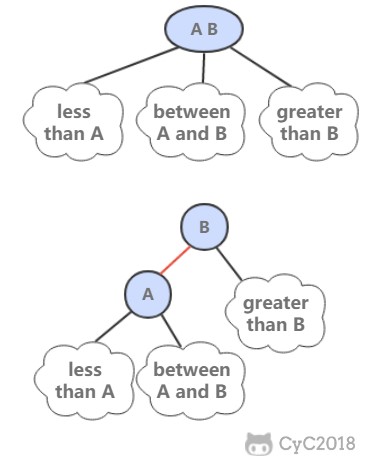
2-3 查找树引入了 2- 节点和 3- 节点,目的是为了让树平衡。一颗完美平衡的 2-3 查找树的所有空链接到根节点的距离应该是相同的。
- 
+ 
## 1. 插入操作
@@ -530,11 +530,11 @@ private List keys(Node x, Key l, Key h) {
- 如果插入到 2- 节点上,那么直接将新节点和原来的节点组成 3- 节点即可。
- 
+ 
- 如果是插入到 3- 节点上,就会产生一个临时 4- 节点时,需要将 4- 节点分裂成 3 个 2- 节点,并将中间的 2- 节点移到上层节点中。如果上移操作继续产生临时 4- 节点则一直进行分裂上移,直到不存在临时 4- 节点。
- 
+ 
## 2. 性质
@@ -546,7 +546,7 @@ private List keys(Node x, Key l, Key h) {
红黑树是 2-3 查找树,但它不需要分别定义 2- 节点和 3- 节点,而是在普通的二叉查找树之上,为节点添加颜色。指向一个节点的链接颜色如果为红色,那么这个节点和上层节点表示的是一个 3- 节点,而黑色则是普通链接。
- 
+ 
红黑树具有以下性质:
@@ -555,7 +555,7 @@ private List keys(Node x, Key l, Key h) {
画红黑树时可以将红链接画平。
- 
+ 
```java
public class RedBlackBST, Value> extends BST {
@@ -575,7 +575,7 @@ public class RedBlackBST, Value> extends BST 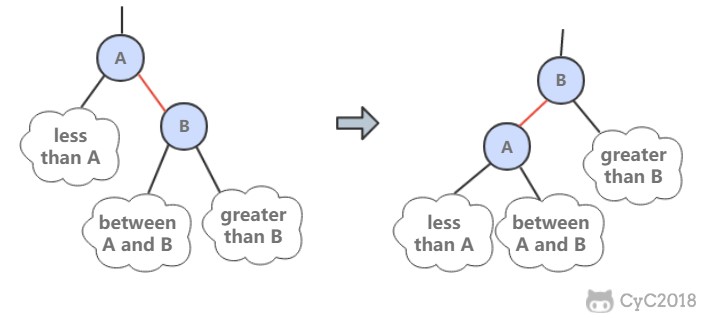
+ 
```java
public Node rotateLeft(Node h) {
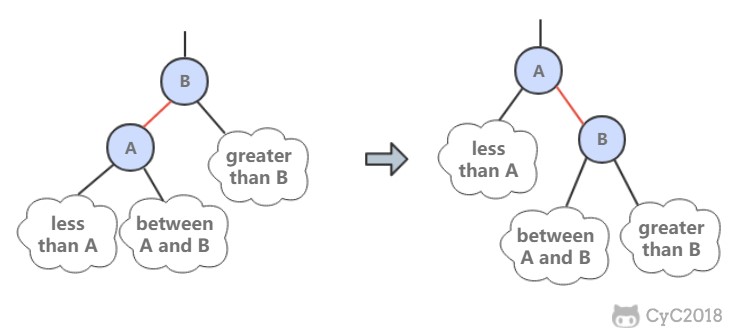
@@ -594,7 +594,7 @@ public Node rotateLeft(Node h) {
进行右旋转是为了转换两个连续的左红链接,这会在之后的插入过程中探讨。
- 
+ 
```java
public Node rotateRight(Node h) {
@@ -613,7 +613,7 @@ public Node rotateRight(Node h) {
一个 4- 节点在红黑树中表现为一个节点的左右子节点都是红色的。分裂 4- 节点除了需要将子节点的颜色由红变黑之外,同时需要将父节点的颜色由黑变红,从 2-3 树的角度看就是将中间节点移到上层节点。
- 
+ 
```java
void flipColors(Node h) {
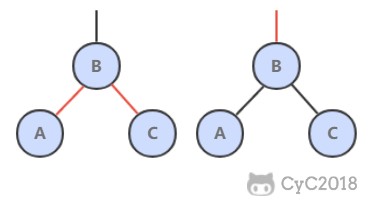
@@ -631,7 +631,7 @@ void flipColors(Node h) {
- 如果左子节点是红色的,而且左子节点的左子节点也是红色的,进行右旋转;
- 如果左右子节点均为红色的,进行颜色转换。
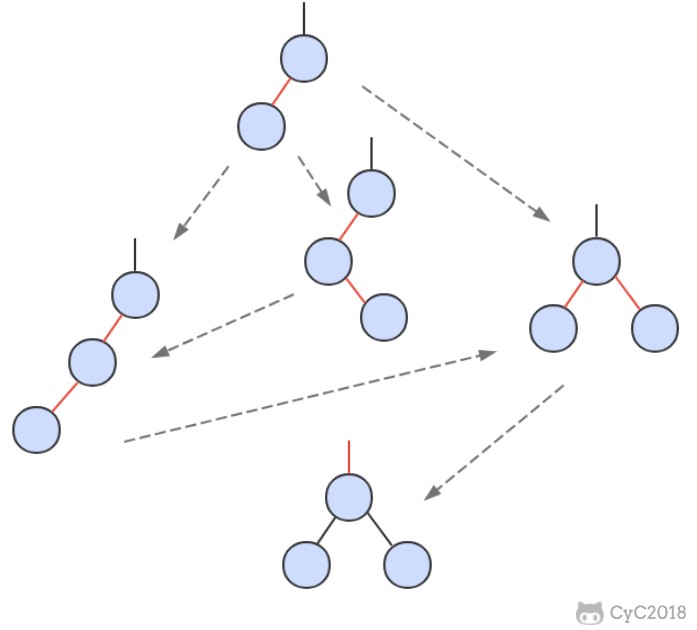
- 
+ 
```java
@Override
@@ -756,7 +756,7 @@ public class Transaction {
对于 N 个键,M 条链表 (N>M),如果哈希函数能够满足均匀性的条件,每条链表的大小趋向于 N/M,因此未命中的查找和插入操作所需要的比较次数为 \~N/M。
- 
+ 
## 3. 线性探测法
@@ -765,7 +765,7 @@ public class Transaction {
使用线性探测法,数组的大小 M 应当大于键的个数 N(M>N)。
- 
+ 
```java
public class LinearProbingHashST implements UnorderedST {
@@ -867,7 +867,7 @@ public void delete(Key key) {
线性探测法的成本取决于连续条目的长度,连续条目也叫聚簇。当聚簇很长时,在查找和插入时也需要进行很多次探测。例如下图中 2\~4 位置就是一个聚簇。
-
+
α = N/M,把 α 称为使用率。理论证明,当 α 小于 1/2 时探测的预计次数只在 1.5 到 2.5 之间。为了保证散列表的性能,应当调整数组的大小,使得 α 在 [1/4, 1/2] 之间。
diff --git a/docs/notes/缓存.md b/docs/notes/缓存.md
index f52d9c1a..347088d0 100644
--- a/docs/notes/缓存.md
+++ b/docs/notes/缓存.md
@@ -211,7 +211,7 @@ CDN 主要有以下优点:
- 通过部署多台服务器,从而提高系统整体的带宽性能;
- 多台服务器可以看成是一种冗余机制,从而具有高可用性。
-
+
# 五、缓存问题
@@ -285,11 +285,11 @@ Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了
将哈希空间 [0, 2n-1] 看成一个哈希环,每个服务器节点都配置到哈希环上。每个数据对象通过哈希取模得到哈希值之后,存放到哈希环中顺时针方向第一个大于等于该哈希值的节点上。
-
+
一致性哈希在增加或者删除节点时只会影响到哈希环中相邻的节点,例如下图中新增节点 X,只需要将它前一个节点 C 上的数据重新进行分布即可,对于节点 A、B、D 都没有影响。
-
+
## 虚拟节点
diff --git a/docs/notes/计算机操作系统 - 内存管理.md b/docs/notes/计算机操作系统 - 内存管理.md
index ae31fdaf..c4c5b713 100644
--- a/docs/notes/计算机操作系统 - 内存管理.md
+++ b/docs/notes/计算机操作系统 - 内存管理.md
@@ -22,7 +22,7 @@
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0\~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。
-
+
# 分页系统地址映射
@@ -32,7 +32,7 @@
下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。
-
+
# 页面置换算法
@@ -72,7 +72,7 @@
4,7,0,7,1,0,1,2,1,2,6
```
-
+
## 3. 最近未使用
> NRU, Not Recently Used
@@ -102,7 +102,7 @@ FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问
当页面被访问 (读或写) 时设置该页面的 R 位为 1。需要替换的时候,检查最老页面的 R 位。如果 R 位是 0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是 1,就将 R 位清 0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续从链表的头部开始搜索。
-
+
## 6. 时钟
@@ -110,7 +110,7 @@ FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问
第二次机会算法需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。
-
+
# 分段
@@ -118,11 +118,11 @@ FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问
下图为一个编译器在编译过程中建立的多个表,有 4 个表是动态增长的,如果使用分页系统的一维地址空间,动态增长的特点会导致覆盖问题的出现。
-
+
分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,并且可以动态增长。
-
+
# 段页式
diff --git a/docs/notes/计算机操作系统 - 概述.md b/docs/notes/计算机操作系统 - 概述.md
index e27a1f3c..2569d201 100644
--- a/docs/notes/计算机操作系统 - 概述.md
+++ b/docs/notes/计算机操作系统 - 概述.md
@@ -76,7 +76,7 @@
如果一个进程在用户态需要使用内核态的功能,就进行系统调用从而陷入内核,由操作系统代为完成。
-
+
Linux 的系统调用主要有以下这些:
@@ -105,7 +105,7 @@ Linux 的系统调用主要有以下这些:
因为需要频繁地在用户态和核心态之间进行切换,所以会有一定的性能损失。
-
+
# 中断分类
diff --git a/docs/notes/计算机操作系统 - 死锁.md b/docs/notes/计算机操作系统 - 死锁.md
index 53ad4abf..8dc385a4 100644
--- a/docs/notes/计算机操作系统 - 死锁.md
+++ b/docs/notes/计算机操作系统 - 死锁.md
@@ -20,7 +20,7 @@
# 必要条件
-
+
- 互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
- 占有和等待:已经得到了某个资源的进程可以再请求新的资源。
@@ -52,7 +52,7 @@
## 1. 每种类型一个资源的死锁检测
-
+
上图为资源分配图,其中方框表示资源,圆圈表示进程。资源指向进程表示该资源已经分配给该进程,进程指向资源表示进程请求获取该资源。
@@ -62,7 +62,7 @@
## 2. 每种类型多个资源的死锁检测
-
+
上图中,有三个进程四个资源,每个数据代表的含义如下:
@@ -111,7 +111,7 @@
## 1. 安全状态
-
+
图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
@@ -123,13 +123,13 @@
一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。
-
+
上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态。
## 3. 多个资源的银行家算法
-
+
上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0。
diff --git a/docs/notes/计算机操作系统 - 设备管理.md b/docs/notes/计算机操作系统 - 设备管理.md
index 9def7115..3a035ba9 100644
--- a/docs/notes/计算机操作系统 - 设备管理.md
+++ b/docs/notes/计算机操作系统 - 设备管理.md
@@ -16,7 +16,7 @@
- 制动手臂(Actuator arm):用于在磁道之间移动磁头;
- 主轴(Spindle):使整个盘面转动。
-
+
# 磁盘调度算法
@@ -44,7 +44,7 @@
虽然平均寻道时间比较低,但是不够公平。如果新到达的磁道请求总是比一个在等待的磁道请求近,那么在等待的磁道请求会一直等待下去,也就是出现饥饿现象。具体来说,两端的磁道请求更容易出现饥饿现象。
-
+
## 3. 电梯算法
@@ -56,7 +56,7 @@
因为考虑了移动方向,因此所有的磁盘请求都会被满足,解决了 SSTF 的饥饿问题。
-
+
diff --git a/docs/notes/计算机操作系统 - 进程管理.md b/docs/notes/计算机操作系统 - 进程管理.md
index 51a2bada..d2b4634b 100644
--- a/docs/notes/计算机操作系统 - 进程管理.md
+++ b/docs/notes/计算机操作系统 - 进程管理.md
@@ -36,7 +36,7 @@
下图显示了 4 个程序创建了 4 个进程,这 4 个进程可以并发地执行。
-
+
## 2. 线程
@@ -46,7 +46,7 @@
QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 HTTP 请求线程、事件响应线程、渲染线程等等,线程的并发执行使得在浏览器中点击一个新链接从而发起 HTTP 请求时,浏览器还可以响应用户的其它事件。
-
+
## 3. 区别
@@ -68,7 +68,7 @@ QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 H
# 进程状态的切换
-
+
- 就绪状态(ready):等待被调度
- 运行状态(running)
@@ -116,7 +116,7 @@ QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 H
- 因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。
- 而如果时间片过长,那么实时性就不能得到保证。
-
+
**2.2 优先级调度**
@@ -134,7 +134,7 @@ QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 H
可以将这种调度算法看成是时间片轮转调度算法和优先级调度算法的结合。
-
+
## 3. 实时系统
@@ -308,7 +308,7 @@ end;
## 1. 哲学家进餐问题
-
+
五个哲学家围着一张圆桌,每个哲学家面前放着食物。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
@@ -553,7 +553,7 @@ int pipe(int fd[2]);
- 只支持半双工通信(单向交替传输);
- 只能在父子进程或者兄弟进程中使用。
-
+
## 2. FIFO
@@ -567,7 +567,7 @@ int mkfifoat(int fd, const char *path, mode_t mode);
FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。
-
+
## 3. 消息队列
diff --git a/docs/notes/计算机操作系统 - 链接.md b/docs/notes/计算机操作系统 - 链接.md
index dfce4295..061f39a0 100644
--- a/docs/notes/计算机操作系统 - 链接.md
+++ b/docs/notes/计算机操作系统 - 链接.md
@@ -29,7 +29,7 @@ gcc -o hello hello.c
这个过程大致如下:
-
+
- 预处理阶段:处理以 # 开头的预处理命令;
- 编译阶段:翻译成汇编文件;
@@ -43,7 +43,7 @@ gcc -o hello hello.c
- 符号解析:每个符号对应于一个函数、一个全局变量或一个静态变量,符号解析的目的是将每个符号引用与一个符号定义关联起来。
- 重定位:链接器通过把每个符号定义与一个内存位置关联起来,然后修改所有对这些符号的引用,使得它们指向这个内存位置。
-
+
# 目标文件
@@ -63,7 +63,7 @@ gcc -o hello hello.c
- 在给定的文件系统中一个库只有一个文件,所有引用该库的可执行目标文件都共享这个文件,它不会被复制到引用它的可执行文件中;
- 在内存中,一个共享库的 .text 节(已编译程序的机器代码)的一个副本可以被不同的正在运行的进程共享。
-
+
diff --git a/docs/notes/计算机网络 - 传输层.md b/docs/notes/计算机网络 - 传输层.md
index f2f34117..d81ae2ec 100644
--- a/docs/notes/计算机网络 - 传输层.md
+++ b/docs/notes/计算机网络 - 传输层.md
@@ -23,13 +23,13 @@
# UDP 首部格式
-
+
首部字段只有 8 个字节,包括源端口、目的端口、长度、检验和。12 字节的伪首部是为了计算检验和临时添加的。
# TCP 首部格式
-
+
- **序号** :用于对字节流进行编号,例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。
@@ -47,7 +47,7 @@
# TCP 的三次握手
-
+
假设 A 为客户端,B 为服务器端。
@@ -69,7 +69,7 @@
# TCP 的四次挥手
-
+
以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为 ACK 在连接建立之后都为 1。
@@ -117,7 +117,7 @@ TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文
接收窗口只会对窗口内最后一个按序到达的字节进行确认,例如接收窗口已经收到的字节为 {31, 34, 35},其中 {31} 按序到达,而 {34, 35} 就不是,因此只对字节 31 进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。
-
+
# TCP 流量控制
@@ -129,7 +129,7 @@ TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文
如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接收,而拥塞控制是为了降低整个网络的拥塞程度。
-
+
TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
@@ -140,7 +140,7 @@ TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、
- 接收方有足够大的接收缓存,因此不会发生流量控制;
- 虽然 TCP 的窗口基于字节,但是这里设窗口的大小单位为报文段。
-
+
## 1. 慢开始与拥塞避免
@@ -160,7 +160,7 @@ TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、
慢开始和快恢复的快慢指的是 cwnd 的设定值,而不是 cwnd 的增长速率。慢开始 cwnd 设定为 1,而快恢复 cwnd 设定为 ssthresh。
-
+
diff --git a/docs/notes/计算机网络 - 应用层.md b/docs/notes/计算机网络 - 应用层.md
index 5a8d3486..2d9d4c6e 100644
--- a/docs/notes/计算机网络 - 应用层.md
+++ b/docs/notes/计算机网络 - 应用层.md
@@ -22,7 +22,7 @@ DNS 是一个分布式数据库,提供了主机名和 IP 地址之间相互转
域名具有层次结构,从上到下依次为:根域名、顶级域名、二级域名。
-
+
DNS 可以使用 UDP 或者 TCP 进行传输,使用的端口号都为 53。大多数情况下 DNS 使用 UDP 进行传输,这就要求域名解析器和域名服务器都必须自己处理超时和重传从而保证可靠性。在两种情况下会使用 TCP 进行传输:
@@ -40,11 +40,11 @@ FTP 使用 TCP 进行连接,它需要两个连接来传送一个文件:
- 主动模式:服务器端主动建立数据连接,其中服务器端的端口号为 20,客户端的端口号随机,但是必须大于 1024,因为 0\~1023 是熟知端口号。
-
+
- 被动模式:客户端主动建立数据连接,其中客户端的端口号由客户端自己指定,服务器端的端口号随机。
-
+
主动模式要求客户端开放端口号给服务器端,需要去配置客户端的防火墙。被动模式只需要服务器端开放端口号即可,无需客户端配置防火墙。但是被动模式会导致服务器端的安全性减弱,因为开放了过多的端口号。
@@ -61,7 +61,7 @@ DHCP 工作过程如下:
3. 如果客户端选择了某个 DHCP 服务器提供的信息,那么就发送 Request 报文给该 DHCP 服务器。
4. DHCP 服务器发送 Ack 报文,表示客户端此时可以使用提供给它的信息。
-
+
# 远程登录协议
@@ -75,13 +75,13 @@ TELNET 可以适应许多计算机和操作系统的差异,例如不同操作
邮件协议包含发送协议和读取协议,发送协议常用 SMTP,读取协议常用 POP3 和 IMAP。
-
+
## 1. SMTP
SMTP 只能发送 ASCII 码,而互联网邮件扩充 MIME 可以发送二进制文件。MIME 并没有改动或者取代 SMTP,而是增加邮件主体的结构,定义了非 ASCII 码的编码规则。
-
+
## 2. POP3
diff --git a/docs/notes/计算机网络 - 概述.md b/docs/notes/计算机网络 - 概述.md
index bdfe4f4a..d6e2e19e 100644
--- a/docs/notes/计算机网络 - 概述.md
+++ b/docs/notes/计算机网络 - 概述.md
@@ -22,27 +22,27 @@
网络把主机连接起来,而互连网(internet)是把多种不同的网络连接起来,因此互连网是网络的网络。而互联网(Internet)是全球范围的互连网。
-
+
# ISP
互联网服务提供商 ISP 可以从互联网管理机构获得许多 IP 地址,同时拥有通信线路以及路由器等联网设备,个人或机构向 ISP 缴纳一定的费用就可以接入互联网。
-
+
目前的互联网是一种多层次 ISP 结构,ISP 根据覆盖面积的大小分为第一层 ISP、区域 ISP 和接入 ISP。互联网交换点 IXP 允许两个 ISP 直接相连而不用经过第三个 ISP。
-
+
# 主机之间的通信方式
- 客户-服务器(C/S):客户是服务的请求方,服务器是服务的提供方。
-
+
- 对等(P2P):不区分客户和服务器。
-
+
# 电路交换与分组交换
@@ -60,7 +60,7 @@
总时延 = 排队时延 + 处理时延 + 传输时延 + 传播时延
-
+
## 1. 排队时延
@@ -76,7 +76,7 @@
-
+
其中 l 表示数据帧的长度,v 表示传输速率。
@@ -87,13 +87,13 @@
-
+
其中 l 表示信道长度,v 表示电磁波在信道上的传播速度。
# 计算机网络体系结构
-
+
## 1. 五层协议
@@ -123,7 +123,7 @@
TCP/IP 体系结构不严格遵循 OSI 分层概念,应用层可能会直接使用 IP 层或者网络接口层。
-
+
## 4. 数据在各层之间的传递过程
diff --git a/docs/notes/计算机网络 - 物理层.md b/docs/notes/计算机网络 - 物理层.md
index a748b50b..3d98ca94 100644
--- a/docs/notes/计算机网络 - 物理层.md
+++ b/docs/notes/计算机网络 - 物理层.md
@@ -16,7 +16,7 @@
模拟信号是连续的信号,数字信号是离散的信号。带通调制把数字信号转换为模拟信号。
-
+
diff --git a/docs/notes/计算机网络 - 网络层.md b/docs/notes/计算机网络 - 网络层.md
index 69d106d5..563ea8c3 100644
--- a/docs/notes/计算机网络 - 网络层.md
+++ b/docs/notes/计算机网络 - 网络层.md
@@ -26,7 +26,7 @@
使用 IP 协议,可以把异构的物理网络连接起来,使得在网络层看起来好像是一个统一的网络。
-
+
与 IP 协议配套使用的还有三个协议:
@@ -36,7 +36,7 @@
# IP 数据报格式
-
+
- **版本** : 有 4(IPv4)和 6(IPv6)两个值;
@@ -56,7 +56,7 @@
- **片偏移** : 和标识符一起,用于发生分片的情况。片偏移的单位为 8 字节。
-
+
# IP 地址编址方式
@@ -72,7 +72,7 @@ IP 地址的编址方式经历了三个历史阶段:
IP 地址 ::= {< 网络号 >, < 主机号 >}
-
+
## 2. 子网划分
@@ -102,27 +102,27 @@ CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
-
+
ARP 实现由 IP 地址得到 MAC 地址。
-
+
每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到 MAC 地址的映射表。
如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
-
+
# 网际控制报文协议 ICMP
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP 数据报中,但是不属于高层协议。
-
+
ICMP 报文分为差错报告报文和询问报文。
-
+
## 1. Ping
@@ -155,7 +155,7 @@ VPN 使用公用的互联网作为本机构各专用网之间的通信载体。
下图中,场所 A 和 B 的通信经过互联网,如果场所 A 的主机 X 要和另一个场所 B 的主机 Y 通信,IP 数据报的源地址是 10.1.0.1,目的地址是 10.2.0.3。数据报先发送到与互联网相连的路由器 R1,R1 对内部数据进行加密,然后重新加上数据报的首部,源地址是路由器 R1 的全球地址 125.1.2.3,目的地址是路由器 R2 的全球地址 194.4.5.6。路由器 R2 收到数据报后将数据部分进行解密,恢复原来的数据报,此时目的地址为 10.2.0.3,就交付给 Y。
-
+
# 网络地址转换 NAT
@@ -163,7 +163,7 @@ VPN 使用公用的互联网作为本机构各专用网之间的通信载体。
在以前,NAT 将本地 IP 和全球 IP 一一对应,这种方式下拥有 n 个全球 IP 地址的专用网内最多只可以同时有 n 台主机接入互联网。为了更有效地利用全球 IP 地址,现在常用的 NAT 转换表把传输层的端口号也用上了,使得多个专用网内部的主机共用一个全球 IP 地址。使用端口号的 NAT 也叫做网络地址与端口转换 NAPT。
-
+
# 路由器的结构
@@ -171,7 +171,7 @@ VPN 使用公用的互联网作为本机构各专用网之间的通信载体。
分组转发结构由三个部分组成:交换结构、一组输入端口和一组输出端口。
-
+
# 路由器分组转发流程
@@ -182,7 +182,7 @@ VPN 使用公用的互联网作为本机构各专用网之间的通信载体。
- 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
- 报告转发分组出错。
-
+
# 路由选择协议
@@ -239,7 +239,7 @@ BGP 只能寻找一条比较好的路由,而不是最佳路由。
每个 AS 都必须配置 BGP 发言人,通过在两个相邻 BGP 发言人之间建立 TCP 连接来交换路由信息。
-
+
diff --git a/docs/notes/计算机网络 - 链路层.md b/docs/notes/计算机网络 - 链路层.md
index 7d7d88ae..c08ef797 100644
--- a/docs/notes/计算机网络 - 链路层.md
+++ b/docs/notes/计算机网络 - 链路层.md
@@ -28,7 +28,7 @@
将网络层传下来的分组添加首部和尾部,用于标记帧的开始和结束。
-
+
## 2. 透明传输
@@ -36,7 +36,7 @@
帧使用首部和尾部进行定界,如果帧的数据部分含有和首部尾部相同的内容,那么帧的开始和结束位置就会被错误的判定。需要在数据部分出现首部尾部相同的内容前面插入转义字符。如果数据部分出现转义字符,那么就在转义字符前面再加个转义字符。在接收端进行处理之后可以还原出原始数据。这个过程透明传输的内容是转义字符,用户察觉不到转义字符的存在。
-
+
## 3. 差错检测
@@ -64,13 +64,13 @@
频分复用的所有主机在相同的时间占用不同的频率带宽资源。
-
+
## 2. 时分复用
时分复用的所有主机在不同的时间占用相同的频率带宽资源。
-
+
使用频分复用和时分复用进行通信,在通信的过程中主机会一直占用一部分信道资源。但是由于计算机数据的突发性质,通信过程没必要一直占用信道资源而不让出给其它用户使用,因此这两种方式对信道的利用率都不高。
@@ -78,7 +78,7 @@
是对时分复用的一种改进,不固定每个用户在时分复用帧中的位置,只要有数据就集中起来组成统计时分复用帧然后发送。
-
+
## 4. 波分复用
@@ -90,7 +90,7 @@
-
+
为了讨论方便,取 m=8,设码片  为 00011011。在拥有该码片的用户发送比特 1 时就发送该码片,发送比特 0 时就发送该码片的反码 11100100。
@@ -100,9 +100,9 @@
-
为 00011011。在拥有该码片的用户发送比特 1 时就发送该码片,发送比特 0 时就发送该码片的反码 11100100。
@@ -100,9 +100,9 @@
-
+
-
+
其中  为 的反码。
@@ -110,7 +110,7 @@
码分复用需要发送的数据量为原先的 m 倍。
-
为 的反码。
@@ -110,7 +110,7 @@
码分复用需要发送的数据量为原先的 m 倍。
-
+
# CSMA/CD 协议
@@ -125,13 +125,13 @@ CSMA/CD 表示载波监听多点接入 / 碰撞检测。
当发生碰撞时,站点要停止发送,等待一段时间再发送。这个时间采用 **截断二进制指数退避算法** 来确定。从离散的整数集合 {0, 1, .., (2k-1)} 中随机取出一个数,记作 r,然后取 r 倍的争用期作为重传等待时间。
-
+
# PPP 协议
互联网用户通常需要连接到某个 ISP 之后才能接入到互联网,PPP 协议是用户计算机和 ISP 进行通信时所使用的数据链路层协议。
-
+
PPP 的帧格式:
@@ -140,7 +140,7 @@ PPP 的帧格式:
- FCS 字段是使用 CRC 的检验序列
- 信息部分的长度不超过 1500
-
+
# MAC 地址
@@ -156,7 +156,7 @@ MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标
可以按照网络拓扑结构对局域网进行分类:
-
+
# 以太网
@@ -172,7 +172,7 @@ MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标
- **数据** :长度在 46-1500 之间,如果太小则需要填充;
- **FCS** :帧检验序列,使用的是 CRC 检验方法;
-
+
# 交换机
@@ -182,7 +182,7 @@ MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标
下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧,主机 B 回应该帧向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 2 的映射。
-
+
# 虚拟局域网
@@ -192,7 +192,7 @@ MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标
使用 VLAN 干线连接来建立虚拟局域网,每台交换机上的一个特殊接口被设置为干线接口,以互连 VLAN 交换机。IEEE 定义了一种扩展的以太网帧格式 802.1Q,它在标准以太网帧上加进了 4 字节首部 VLAN 标签,用于表示该帧属于哪一个虚拟局域网。
-
+
diff --git a/docs/notes/设计模式 - 单例.md b/docs/notes/设计模式 - 单例.md
index 136b0f0e..2d60600c 100644
--- a/docs/notes/设计模式 - 单例.md
+++ b/docs/notes/设计模式 - 单例.md
@@ -10,7 +10,7 @@
私有构造函数保证了不能通过构造函数来创建对象实例,只能通过公有静态函数返回唯一的私有静态变量。
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 中介者.md b/docs/notes/设计模式 - 中介者.md
index 94b8c65d..333a21be 100644
--- a/docs/notes/设计模式 - 中介者.md
+++ b/docs/notes/设计模式 - 中介者.md
@@ -11,17 +11,17 @@
- Mediator:中介者,定义一个接口用于与各同事(Colleague)对象通信。
- Colleague:同事,相关对象
-
+
### Implementation
Alarm(闹钟)、CoffeePot(咖啡壶)、Calendar(日历)、Sprinkler(喷头)是一组相关的对象,在某个对象的事件产生时需要去操作其它对象,形成了下面这种依赖结构:
-
+
使用中介者模式可以将复杂的依赖结构变成星形结构:
-
+
```java
public abstract class Colleague {
diff --git a/docs/notes/设计模式 - 享元.md b/docs/notes/设计模式 - 享元.md
index 3e4c0d5d..7bc21088 100644
--- a/docs/notes/设计模式 - 享元.md
+++ b/docs/notes/设计模式 - 享元.md
@@ -12,7 +12,7 @@
- IntrinsicState:内部状态,享元对象共享内部状态
- ExtrinsicState:外部状态,每个享元对象的外部状态不同
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 代理.md b/docs/notes/设计模式 - 代理.md
index 215681a8..9ff95ceb 100644
--- a/docs/notes/设计模式 - 代理.md
+++ b/docs/notes/设计模式 - 代理.md
@@ -13,7 +13,7 @@
- 保护代理(Protection Proxy):按权限控制对象的访问,它负责检查调用者是否具有实现一个请求所必须的访问权限。
- 智能代理(Smart Reference):取代了简单的指针,它在访问对象时执行一些附加操作:记录对象的引用次数;当第一次引用一个对象时,将它装入内存;在访问一个实际对象前,检查是否已经锁定了它,以确保其它对象不能改变它。
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 原型模式.md b/docs/notes/设计模式 - 原型模式.md
index b07d1efe..f1bb2ad1 100644
--- a/docs/notes/设计模式 - 原型模式.md
+++ b/docs/notes/设计模式 - 原型模式.md
@@ -6,7 +6,7 @@
### Class Diagram
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 命令.md b/docs/notes/设计模式 - 命令.md
index 7ad1d013..08b7db20 100644
--- a/docs/notes/设计模式 - 命令.md
+++ b/docs/notes/设计模式 - 命令.md
@@ -16,13 +16,13 @@
- Invoker:通过它来调用命令
- Client:可以设置命令与命令的接收者
-
+
### Implementation
设计一个遥控器,可以控制电灯开关。
-
+
```java
public interface Command {
diff --git a/docs/notes/设计模式 - 备忘录.md b/docs/notes/设计模式 - 备忘录.md
index 190b5550..d88cac72 100644
--- a/docs/notes/设计模式 - 备忘录.md
+++ b/docs/notes/设计模式 - 备忘录.md
@@ -10,7 +10,7 @@
- Caretaker:负责保存好备忘录
- Memento:备忘录,存储原始对象的的状态。备忘录实际上有两个接口,一个是提供给 Caretaker 的窄接口:它只能将备忘录传递给其它对象;一个是提供给 Originator 的宽接口,允许它访问到先前状态所需的所有数据。理想情况是只允许 Originator 访问本备忘录的内部状态。
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 外观.md b/docs/notes/设计模式 - 外观.md
index d89db0da..fda230b7 100644
--- a/docs/notes/设计模式 - 外观.md
+++ b/docs/notes/设计模式 - 外观.md
@@ -6,7 +6,7 @@
### Class Diagram
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 工厂方法.md b/docs/notes/设计模式 - 工厂方法.md
index 152e975a..3b33d97d 100644
--- a/docs/notes/设计模式 - 工厂方法.md
+++ b/docs/notes/设计模式 - 工厂方法.md
@@ -10,7 +10,7 @@
下图中,Factory 有一个 doSomething() 方法,这个方法需要用到一个产品对象,这个产品对象由 factoryMethod() 方法创建。该方法是抽象的,需要由子类去实现。
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 抽象工厂.md b/docs/notes/设计模式 - 抽象工厂.md
index 7e113588..e6b0af9d 100644
--- a/docs/notes/设计模式 - 抽象工厂.md
+++ b/docs/notes/设计模式 - 抽象工厂.md
@@ -14,7 +14,7 @@
从高层次来看,抽象工厂使用了组合,即 Cilent 组合了 AbstractFactory,而工厂方法模式使用了继承。
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 桥接.md b/docs/notes/设计模式 - 桥接.md
index dc49b3fd..268f8cf7 100644
--- a/docs/notes/设计模式 - 桥接.md
+++ b/docs/notes/设计模式 - 桥接.md
@@ -11,7 +11,7 @@
- Abstraction:定义抽象类的接口
- Implementor:定义实现类接口
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 模板方法.md b/docs/notes/设计模式 - 模板方法.md
index ba13406b..f2604abd 100644
--- a/docs/notes/设计模式 - 模板方法.md
+++ b/docs/notes/设计模式 - 模板方法.md
@@ -8,13 +8,13 @@
### Class Diagram
-
+
### Implementation
冲咖啡和冲茶都有类似的流程,但是某些步骤会有点不一样,要求复用那些相同步骤的代码。
-
+
```java
public abstract class CaffeineBeverage {
diff --git a/docs/notes/设计模式 - 状态.md b/docs/notes/设计模式 - 状态.md
index dd3c7e79..8ae80937 100644
--- a/docs/notes/设计模式 - 状态.md
+++ b/docs/notes/设计模式 - 状态.md
@@ -6,13 +6,13 @@
### Class Diagram
-
+
### Implementation
糖果销售机有多种状态,每种状态下销售机有不同的行为,状态可以发生转移,使得销售机的行为也发生改变。
-
+
```java
public interface State {
diff --git a/docs/notes/设计模式 - 生成器.md b/docs/notes/设计模式 - 生成器.md
index bee164a3..c7576782 100644
--- a/docs/notes/设计模式 - 生成器.md
+++ b/docs/notes/设计模式 - 生成器.md
@@ -6,7 +6,7 @@
### Class Diagram
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 空对象.md b/docs/notes/设计模式 - 空对象.md
index 2416e9ce..0b34c2ad 100644
--- a/docs/notes/设计模式 - 空对象.md
+++ b/docs/notes/设计模式 - 空对象.md
@@ -10,7 +10,7 @@
### Class Diagram
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 策略.md b/docs/notes/设计模式 - 策略.md
index f3ec6627..8f5b492d 100644
--- a/docs/notes/设计模式 - 策略.md
+++ b/docs/notes/设计模式 - 策略.md
@@ -11,7 +11,7 @@
- Strategy 接口定义了一个算法族,它们都实现了 behavior() 方法。
- Context 是使用到该算法族的类,其中的 doSomething() 方法会调用 behavior(),setStrategy(Strategy) 方法可以动态地改变 strategy 对象,也就是说能动态地改变 Context 所使用的算法。
-
+
### 与状态模式的比较
diff --git a/docs/notes/设计模式 - 简单工厂.md b/docs/notes/设计模式 - 简单工厂.md
index e03ad311..7192b738 100644
--- a/docs/notes/设计模式 - 简单工厂.md
+++ b/docs/notes/设计模式 - 简单工厂.md
@@ -10,7 +10,7 @@
这样做能把客户类和具体子类的实现解耦,客户类不再需要知道有哪些子类以及应当实例化哪个子类。客户类往往有多个,如果不使用简单工厂,那么所有的客户类都要知道所有子类的细节。而且一旦子类发生改变,例如增加子类,那么所有的客户类都要进行修改。
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 组合.md b/docs/notes/设计模式 - 组合.md
index f87de5a1..18b4b3de 100644
--- a/docs/notes/设计模式 - 组合.md
+++ b/docs/notes/设计模式 - 组合.md
@@ -10,7 +10,7 @@
组合对象拥有一个或者多个组件对象,因此组合对象的操作可以委托给组件对象去处理,而组件对象可以是另一个组合对象或者叶子对象。
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 装饰.md b/docs/notes/设计模式 - 装饰.md
index 039a3590..1e15a921 100644
--- a/docs/notes/设计模式 - 装饰.md
+++ b/docs/notes/设计模式 - 装饰.md
@@ -8,7 +8,7 @@
装饰者(Decorator)和具体组件(ConcreteComponent)都继承自组件(Component),具体组件的方法实现不需要依赖于其它对象,而装饰者组合了一个组件,这样它可以装饰其它装饰者或者具体组件。所谓装饰,就是把这个装饰者套在被装饰者之上,从而动态扩展被装饰者的功能。装饰者的方法有一部分是自己的,这属于它的功能,然后调用被装饰者的方法实现,从而也保留了被装饰者的功能。可以看到,具体组件应当是装饰层次的最低层,因为只有具体组件的方法实现不需要依赖于其它对象。
-
+
### Implementation
@@ -16,7 +16,7 @@
下图表示在 DarkRoast 饮料上新增新添加 Mocha 配料,之后又添加了 Whip 配料。DarkRoast 被 Mocha 包裹,Mocha 又被 Whip 包裹。它们都继承自相同父类,都有 cost() 方法,外层类的 cost() 方法调用了内层类的 cost() 方法。
-
+
```java
public interface Beverage {
diff --git a/docs/notes/设计模式 - 观察者.md b/docs/notes/设计模式 - 观察者.md
index 1b505d74..06d45132 100644
--- a/docs/notes/设计模式 - 观察者.md
+++ b/docs/notes/设计模式 - 观察者.md
@@ -6,7 +6,7 @@
主题(Subject)是被观察的对象,而其所有依赖者(Observer)称为观察者。
-
+
### Class Diagram
@@ -14,13 +14,13 @@
观察者(Observer)的注册功能需要调用主题的 registerObserver() 方法。
-
+
### Implementation
天气数据布告板会在天气信息发生改变时更新其内容,布告板有多个,并且在将来会继续增加。
-
+
```java
public interface Subject {
diff --git a/docs/notes/设计模式 - 解释器.md b/docs/notes/设计模式 - 解释器.md
index 3a34d055..98f7974e 100644
--- a/docs/notes/设计模式 - 解释器.md
+++ b/docs/notes/设计模式 - 解释器.md
@@ -9,7 +9,7 @@
- TerminalExpression:终结符表达式,每个终结符都需要一个 TerminalExpression。
- Context:上下文,包含解释器之外的一些全局信息。
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 访问者.md b/docs/notes/设计模式 - 访问者.md
index 810fde86..17b9af2b 100644
--- a/docs/notes/设计模式 - 访问者.md
+++ b/docs/notes/设计模式 - 访问者.md
@@ -10,7 +10,7 @@
- ConcreteVisitor:具体访问者,存储遍历过程中的累计结果
- ObjectStructure:对象结构,可以是组合结构,或者是一个集合。
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 责任链.md b/docs/notes/设计模式 - 责任链.md
index 10b13515..8b1ac10e 100644
--- a/docs/notes/设计模式 - 责任链.md
+++ b/docs/notes/设计模式 - 责任链.md
@@ -8,7 +8,7 @@
- Handler:定义处理请求的接口,并且实现后继链(successor)
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 迭代器.md b/docs/notes/设计模式 - 迭代器.md
index c4beb94d..0596ace9 100644
--- a/docs/notes/设计模式 - 迭代器.md
+++ b/docs/notes/设计模式 - 迭代器.md
@@ -10,7 +10,7 @@
- Iterator 主要定义了 hasNext() 和 next() 方法;
- Client 组合了 Aggregate,为了迭代遍历 Aggregate,也需要组合 Iterator。
-
+
### Implementation
diff --git a/docs/notes/设计模式 - 适配器.md b/docs/notes/设计模式 - 适配器.md
index 102ff5f0..dd1ebf2d 100644
--- a/docs/notes/设计模式 - 适配器.md
+++ b/docs/notes/设计模式 - 适配器.md
@@ -4,11 +4,11 @@
把一个类接口转换成另一个用户需要的接口。
-
+
### Class Diagram
-
+
### Implementation
diff --git a/docs/notes/设计模式.md b/docs/notes/设计模式.md
index 2d69e88f..88f65599 100644
--- a/docs/notes/设计模式.md
+++ b/docs/notes/设计模式.md
@@ -52,7 +52,7 @@
私有构造函数保证了不能通过构造函数来创建对象实例,只能通过公有静态函数返回唯一的私有静态变量。
-
+
### Implementation
@@ -253,7 +253,7 @@ secondName
这样做能把客户类和具体子类的实现解耦,客户类不再需要知道有哪些子类以及应当实例化哪个子类。客户类往往有多个,如果不使用简单工厂,那么所有的客户类都要知道所有子类的细节。而且一旦子类发生改变,例如增加子类,那么所有的客户类都要进行修改。
-
+
### Implementation
@@ -336,7 +336,7 @@ public class Client {
下图中,Factory 有一个 doSomething() 方法,这个方法需要用到一个产品对象,这个产品对象由 factoryMethod() 方法创建。该方法是抽象的,需要由子类去实现。
-
+
### Implementation
@@ -400,7 +400,7 @@ public class ConcreteFactory2 extends Factory {
从高层次来看,抽象工厂使用了组合,即 Cilent 组合了 AbstractFactory,而工厂方法模式使用了继承。
-
+
### Implementation
@@ -490,7 +490,7 @@ public class Client {
### Class Diagram
-
+
### Implementation
@@ -580,7 +580,7 @@ abcdefghijklmnopqrstuvwxyz
### Class Diagram
-
+
### Implementation
@@ -641,7 +641,7 @@ abc
- Handler:定义处理请求的接口,并且实现后继链(successor)
-
+
### Implementation
@@ -779,13 +779,13 @@ request2 is handle by ConcreteHandler2
- Invoker:通过它来调用命令
- Client:可以设置命令与命令的接收者
-
+
### Implementation
设计一个遥控器,可以控制电灯开关。
-
+
```java
public interface Command {
@@ -900,7 +900,7 @@ public class Client {
- TerminalExpression:终结符表达式,每个终结符都需要一个 TerminalExpression。
- Context:上下文,包含解释器之外的一些全局信息。
-
+
### Implementation
@@ -1025,7 +1025,7 @@ false
- Iterator 主要定义了 hasNext() 和 next() 方法。
- Client 组合了 Aggregate,为了迭代遍历 Aggregate,也需要组合 Iterator。
-
+
### Implementation
@@ -1114,17 +1114,17 @@ public class Client {
- Mediator:中介者,定义一个接口用于与各同事(Colleague)对象通信。
- Colleague:同事,相关对象
-
+
### Implementation
Alarm(闹钟)、CoffeePot(咖啡壶)、Calendar(日历)、Sprinkler(喷头)是一组相关的对象,在某个对象的事件产生时需要去操作其它对象,形成了下面这种依赖结构:
-
+
使用中介者模式可以将复杂的依赖结构变成星形结构:
-
+
```java
public abstract class Colleague {
@@ -1284,7 +1284,7 @@ doSprinkler()
- Caretaker:负责保存好备忘录
- Menento:备忘录,存储原始对象的的状态。备忘录实际上有两个接口,一个是提供给 Caretaker 的窄接口:它只能将备忘录传递给其它对象;一个是提供给 Originator 的宽接口,允许它访问到先前状态所需的所有数据。理想情况是只允许 Originator 访问本备忘录的内部状态。
-
+
### Implementation
@@ -1457,7 +1457,7 @@ public class Client {
主题(Subject)是被观察的对象,而其所有依赖者(Observer)称为观察者。
-
+
### Class Diagram
@@ -1465,13 +1465,13 @@ public class Client {
观察者(Observer)的注册功能需要调用主题的 registerObserver() 方法。
-
+
### Implementation
天气数据布告板会在天气信息发生改变时更新其内容,布告板有多个,并且在将来会继续增加。
-
+
```java
public interface Subject {
@@ -1592,13 +1592,13 @@ StatisticsDisplay.update: 1.0 1.0 1.0
### Class Diagram
-
+
### Implementation
糖果销售机有多种状态,每种状态下销售机有不同的行为,状态可以发生转移,使得销售机的行为也发生改变。
-
+
```java
public interface State {
@@ -1899,7 +1899,7 @@ No gumball dispensed
- Strategy 接口定义了一个算法族,它们都实现了 behavior() 方法。
- Context 是使用到该算法族的类,其中的 doSomething() 方法会调用 behavior(),setStrategy(Strategy) 方法可以动态地改变 strategy 对象,也就是说能动态地改变 Context 所使用的算法。
-
+
### 与状态模式的比较
@@ -1986,13 +1986,13 @@ quack!
### Class Diagram
-
+
### Implementation
冲咖啡和冲茶都有类似的流程,但是某些步骤会有点不一样,要求复用那些相同步骤的代码。
-
+
```java
public abstract class CaffeineBeverage {
@@ -2089,7 +2089,7 @@ Tea.addCondiments
- ConcreteVisitor:具体访问者,存储遍历过程中的累计结果
- ObjectStructure:对象结构,可以是组合结构,或者是一个集合。
-
+
### Implementation
@@ -2294,7 +2294,7 @@ Number of items: 6
### Class Diagram
-
+
### Implementation
@@ -2346,11 +2346,11 @@ public class Client {
把一个类接口转换成另一个用户需要的接口。
-
+
### Class Diagram
-
+
### Implementation
@@ -2422,7 +2422,7 @@ public class Client {
- Abstraction:定义抽象类的接口
- Implementor:定义实现类接口
-
+
### Implementation
@@ -2580,7 +2580,7 @@ public class Client {
组合对象拥有一个或者多个组件对象,因此组合对象的操作可以委托给组件对象去处理,而组件对象可以是另一个组合对象或者叶子对象。
-
+
### Implementation
@@ -2712,7 +2712,7 @@ Composite:root
装饰者(Decorator)和具体组件(ConcreteComponent)都继承自组件(Component),具体组件的方法实现不需要依赖于其它对象,而装饰者组合了一个组件,这样它可以装饰其它装饰者或者具体组件。所谓装饰,就是把这个装饰者套在被装饰者之上,从而动态扩展被装饰者的功能。装饰者的方法有一部分是自己的,这属于它的功能,然后调用被装饰者的方法实现,从而也保留了被装饰者的功能。可以看到,具体组件应当是装饰层次的最低层,因为只有具体组件的方法实现不需要依赖于其它对象。
-
+
### Implementation
@@ -2720,7 +2720,7 @@ Composite:root
下图表示在 DarkRoast 饮料上新增新添加 Mocha 配料,之后又添加了 Whip 配料。DarkRoast 被 Mocha 包裹,Mocha 又被 Whip 包裹。它们都继承自相同父类,都有 cost() 方法,外层类的 cost() 方法调用了内层类的 cost() 方法。
-
+
```java
public interface Beverage {
@@ -2818,7 +2818,7 @@ public class Client {
### Class Diagram
-
+
### Implementation
@@ -2877,7 +2877,7 @@ public class Client {
- IntrinsicState:内部状态,享元对象共享内部状态
- ExtrinsicState:外部状态,每个享元对象的外部状态不同
-
+
### Implementation
@@ -2966,7 +2966,7 @@ Java 利用缓存来加速大量小对象的访问时间。
- 保护代理(Protection Proxy):按权限控制对象的访问,它负责检查调用者是否具有实现一个请求所必须的访问权限。
- 智能代理(Smart Reference):取代了简单的指针,它在访问对象时执行一些附加操作:记录对象的引用次数;当第一次引用一个对象时,将它装入内存;在访问一个实际对象前,检查是否已经锁定了它,以确保其它对象不能改变它。
-
+
### Implementation
diff --git a/docs/notes/集群.md b/docs/notes/集群.md
index e92c828c..f10aee7f 100644
--- a/docs/notes/集群.md
+++ b/docs/notes/集群.md
@@ -33,12 +33,12 @@
下图中,一共有 6 个客户端产生了 6 个请求,这 6 个请求按 (1, 2, 3, 4, 5, 6) 的顺序发送。(1, 3, 5) 的请求会被发送到服务器 1,(2, 4, 6) 的请求会被发送到服务器 2。
-
+
该算法比较适合每个服务器的性能差不多的场景,如果有性能存在差异的情况下,那么性能较差的服务器可能无法承担过大的负载(下图的 Server 2)。
-
+
### 2. 加权轮询(Weighted Round Robbin)
@@ -46,7 +46,7 @@
例如下图中,服务器 1 被赋予的权值为 5,服务器 2 被赋予的权值为 1,那么 (1, 2, 3, 4, 5) 请求会被发送到服务器 1,(6) 请求会被发送到服务器 2。
-
+
### 3. 最少连接(least Connections)
@@ -54,13 +54,13 @@
例如下图中,(1, 3, 5) 请求会被发送到服务器 1,但是 (1, 3) 很快就断开连接,此时只有 (5) 请求连接服务器 1;(2, 4, 6) 请求被发送到服务器 2,只有 (2) 的连接断开,此时 (6, 4) 请求连接服务器 2。该系统继续运行时,服务器 2 会承担过大的负载。
-
+
最少连接算法就是将请求发送给当前最少连接数的服务器上。
例如下图中,服务器 1 当前连接数最小,那么新到来的请求 6 就会被发送到服务器 1 上。
-
+
### 4. 加权最少连接(Weighted Least Connection)
@@ -72,7 +72,7 @@
和轮询算法类似,该算法比较适合服务器性能差不多的场景。
-
+
### 6. 源地址哈希法 (IP Hash)
@@ -80,7 +80,7 @@
可以保证同一 IP 的客户端的请求会转发到同一台服务器上,用来实现会话粘滞(Sticky Session)
-
+
## 转发实现
@@ -95,7 +95,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
该负载均衡转发的缺点比较明显,实际场景中很少使用它。
-
+
### 2. DNS 域名解析
@@ -111,7 +111,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
大型网站基本使用了 DNS 做为第一级负载均衡手段,然后在内部使用其它方式做第二级负载均衡。也就是说,域名解析的结果为内部的负载均衡服务器 IP 地址。
-
+
### 3. 反向代理服务器
@@ -168,7 +168,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
- 当服务器宕机时,将丢失该服务器上的所有 Session。
-
+
## Session Replication
@@ -179,7 +179,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
- 占用过多内存;
- 同步过程占用网络带宽以及服务器处理器时间。
-
+
## Session Server
@@ -193,7 +193,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
- 需要去实现存取 Session 的代码。
-
+
参考:
diff --git a/docs/notes/面向对象思想.md b/docs/notes/面向对象思想.md
index fff09bca..f7314451 100644
--- a/docs/notes/面向对象思想.md
+++ b/docs/notes/面向对象思想.md
@@ -141,7 +141,7 @@ Percussion is playing...
用来描述继承关系,在 Java 中使用 extends 关键字。
-
+
```text
@startuml
@@ -162,7 +162,7 @@ Vihical <|-- Trunck
用来实现一个接口,在 Java 中使用 implements 关键字。
-
+
```text
@startuml
@@ -183,7 +183,7 @@ MoveBehavior <|.. Run
表示整体由部分组成,但是整体和部分不是强依赖的,整体不存在了部分还是会存在。
-
+
```text
@startuml
@@ -206,7 +206,7 @@ Computer o-- Screen
和聚合不同,组合中整体和部分是强依赖的,整体不存在了部分也不存在了。比如公司和部门,公司没了部门就不存在了。但是公司和员工就属于聚合关系了,因为公司没了员工还在。
-
+
```text
@startuml
@@ -227,7 +227,7 @@ Company *-- DepartmentB
表示不同类对象之间有关联,这是一种静态关系,与运行过程的状态无关,在最开始就可以确定。因此也可以用 1 对 1、多对 1、多对多这种关联关系来表示。比如学生和学校就是一种关联关系,一个学校可以有很多学生,但是一个学生只属于一个学校,因此这是一种多对一的关系,在运行开始之前就可以确定。
-
+
```text
@startuml
@@ -250,7 +250,7 @@ School "1" - "n" Student
- A 类是 B 类方法当中的一个参数;
- A 类向 B 类发送消息,从而影响 B 类发生变化。
-
+
```text
@startuml
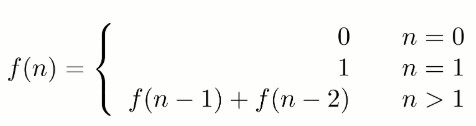

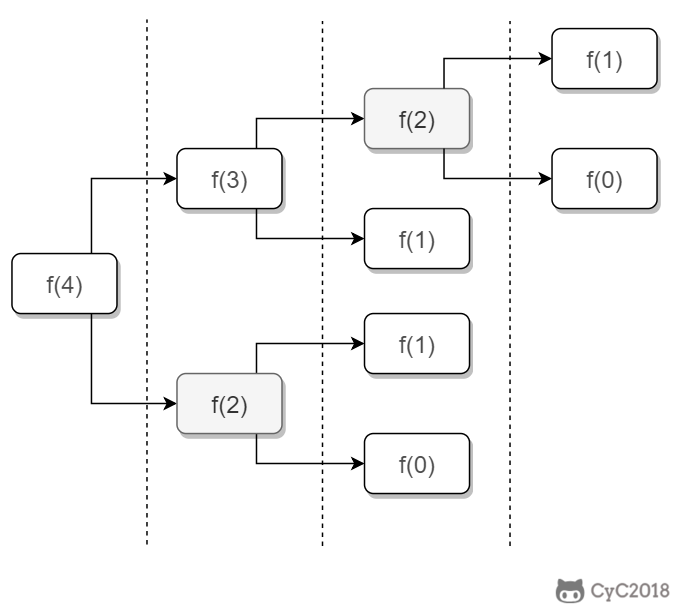



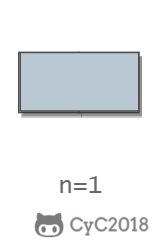

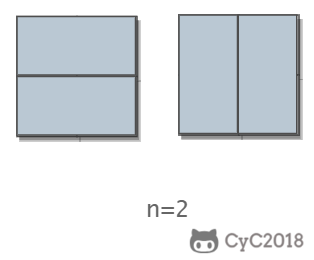

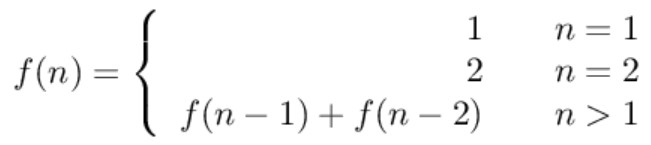

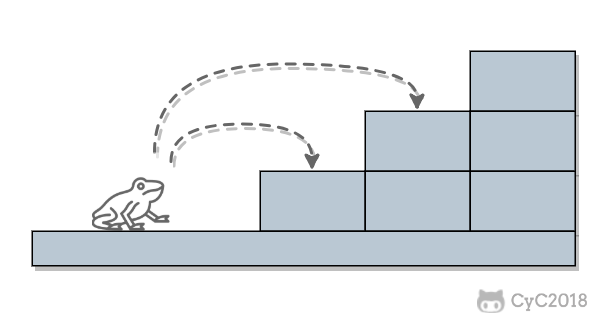



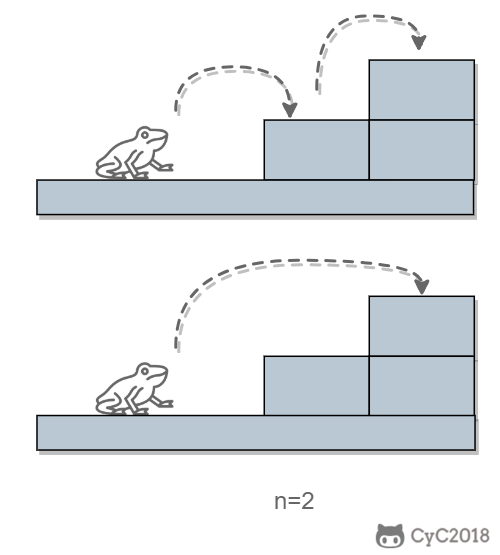

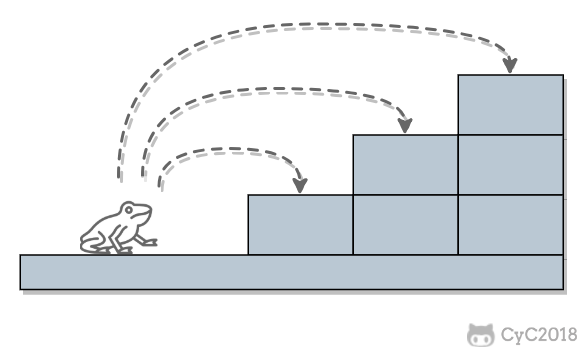

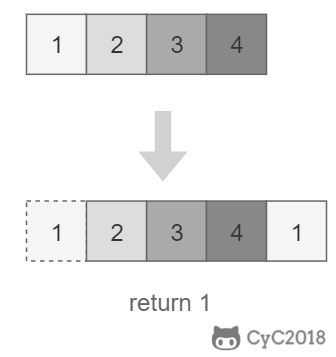

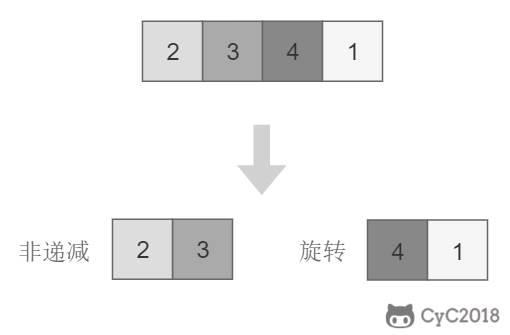

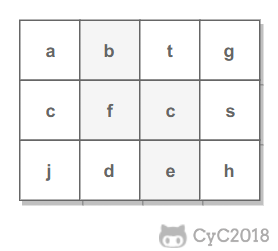

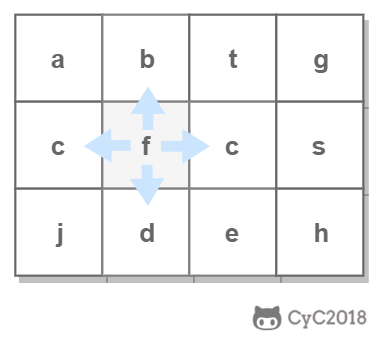

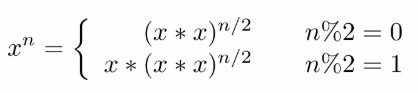



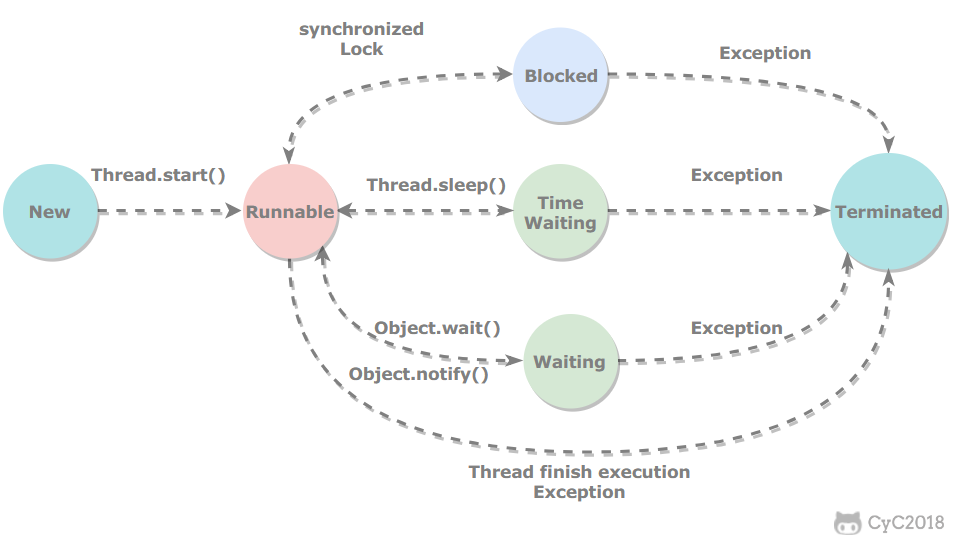

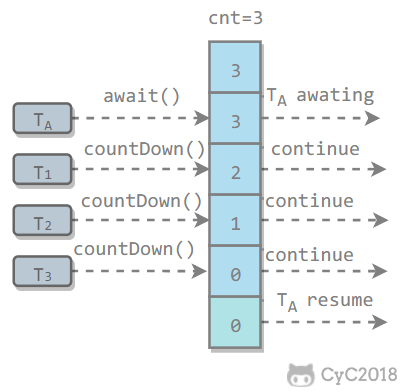

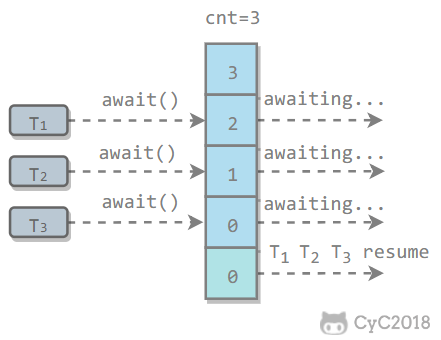



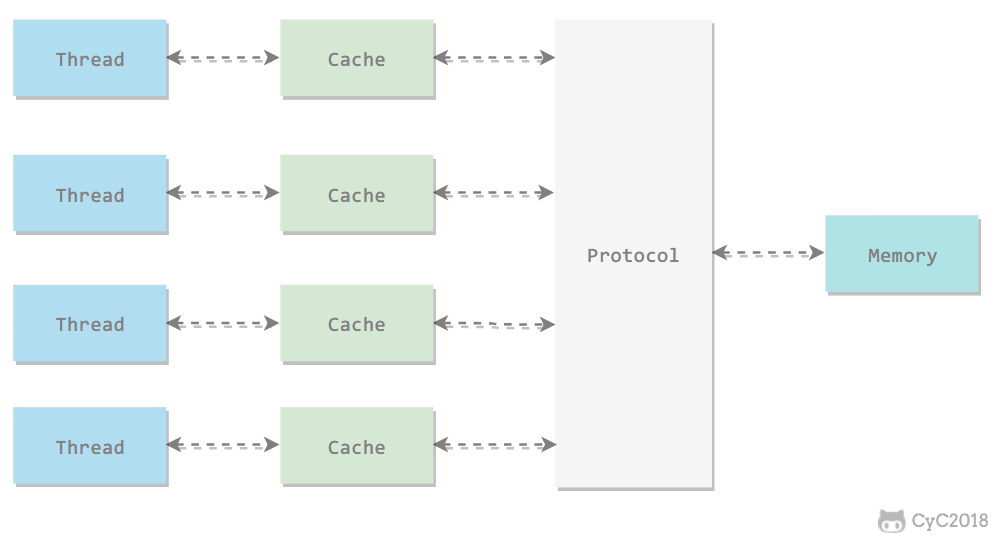

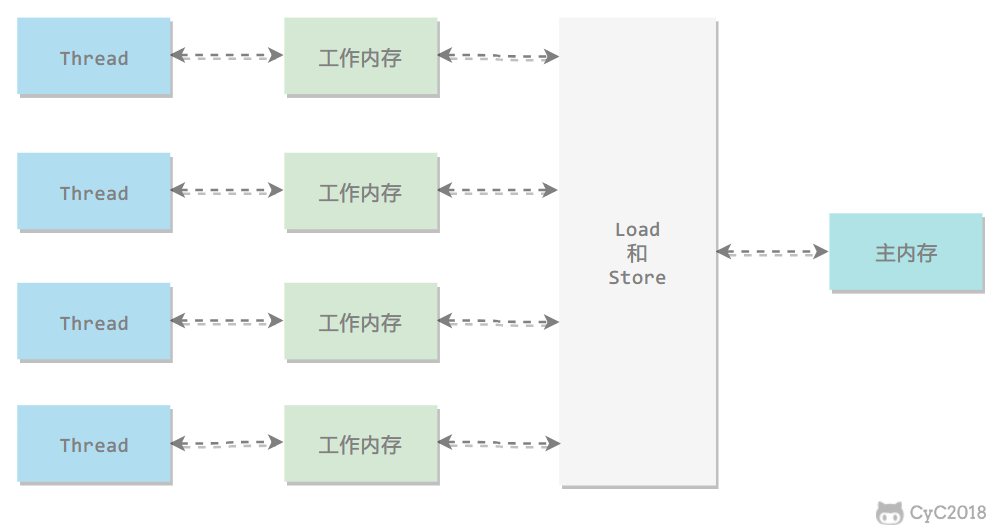

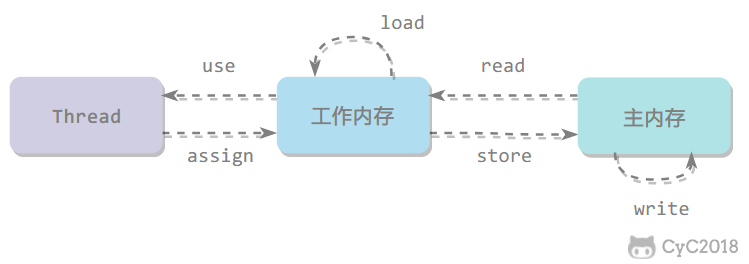

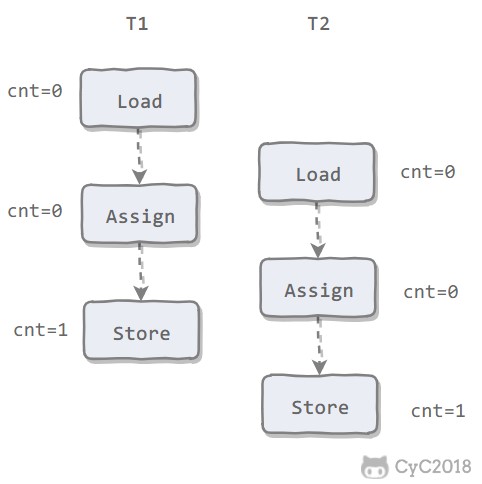

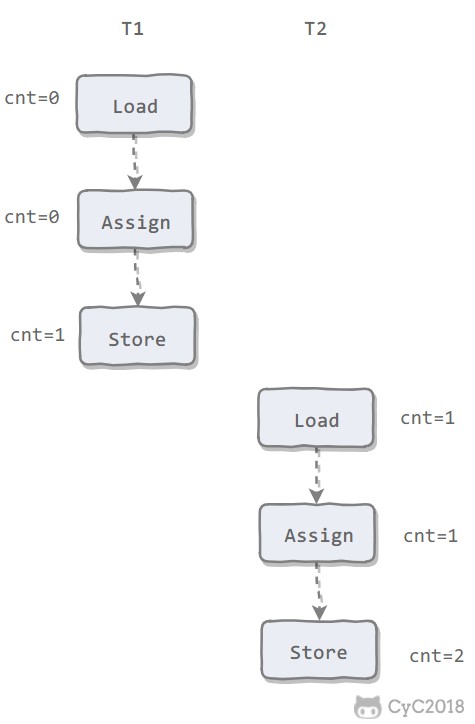



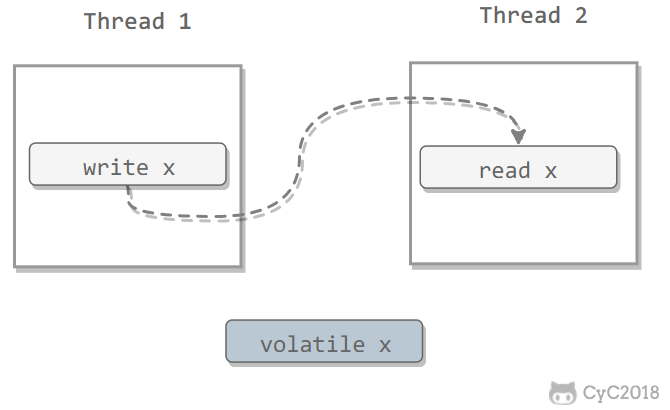

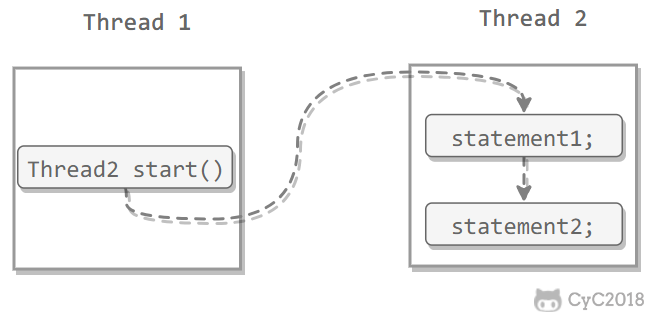

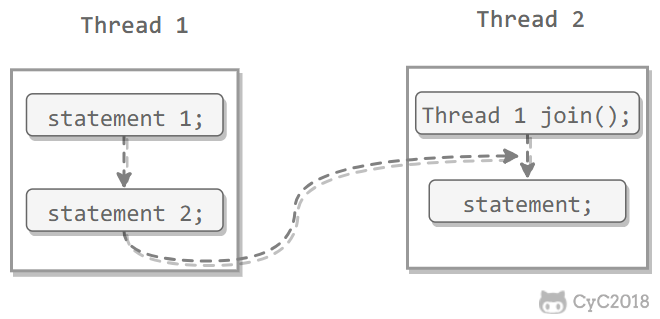



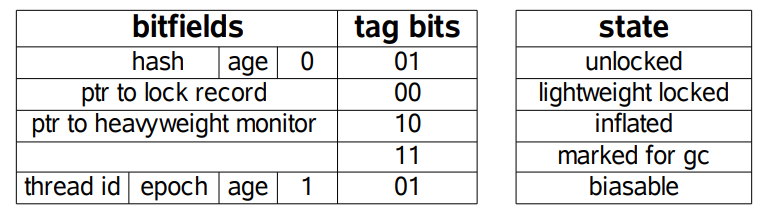

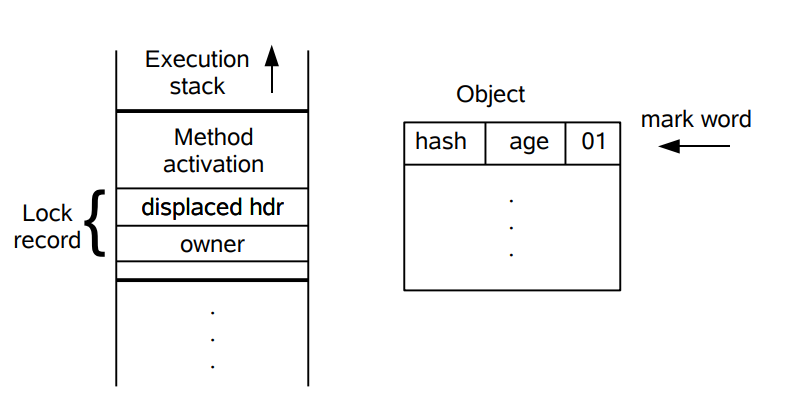

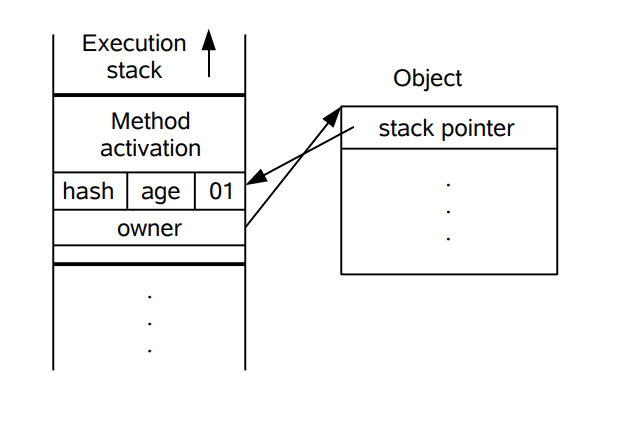

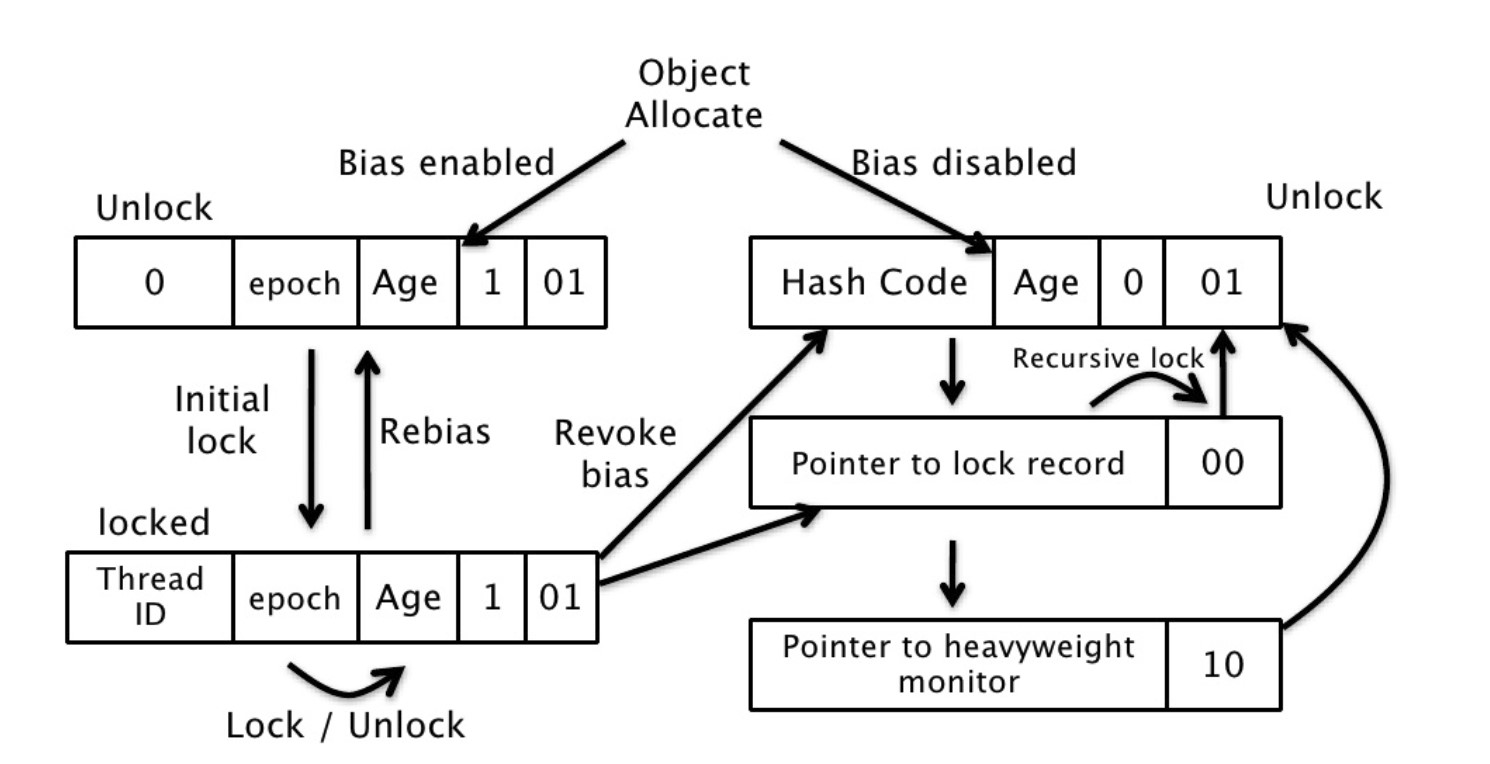

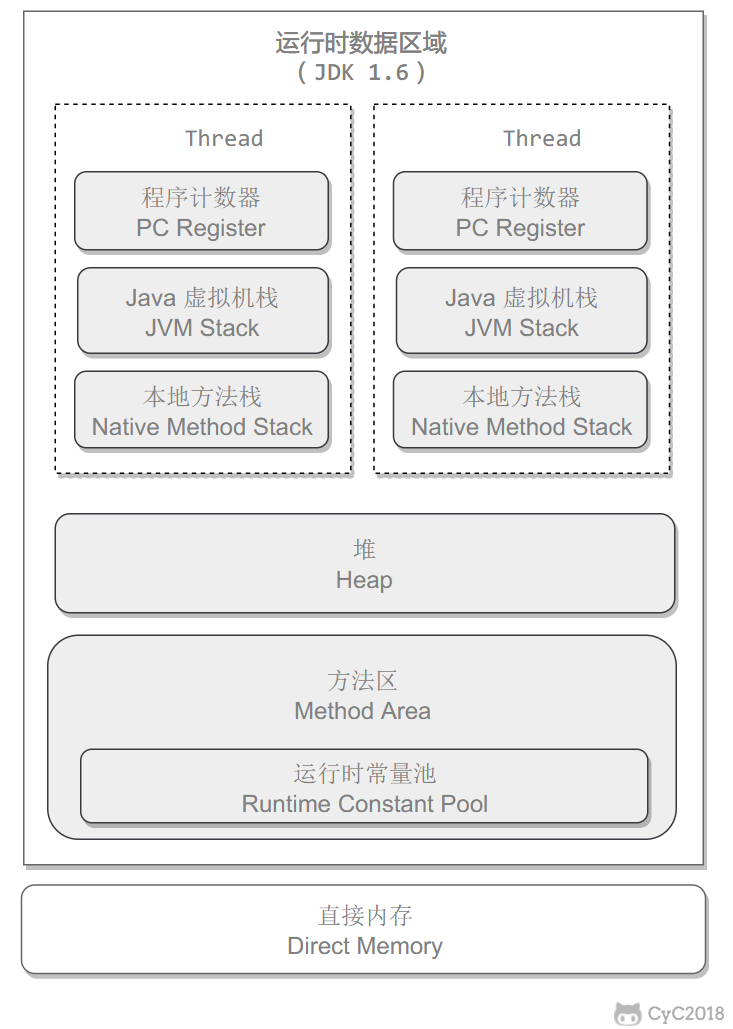

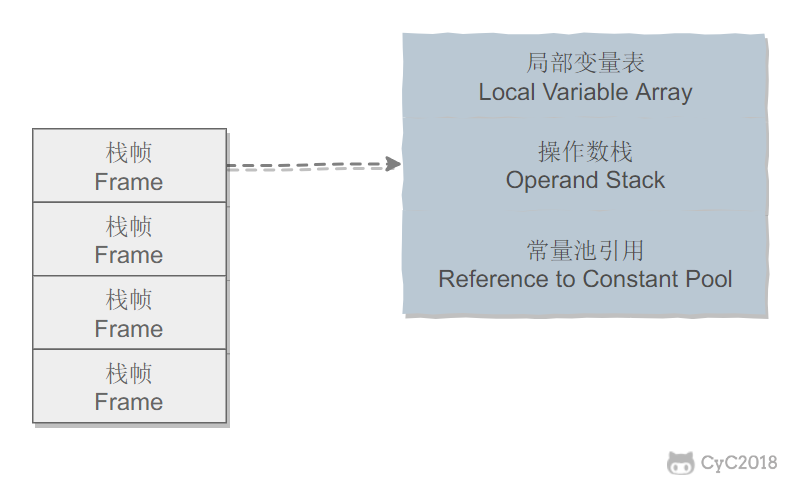

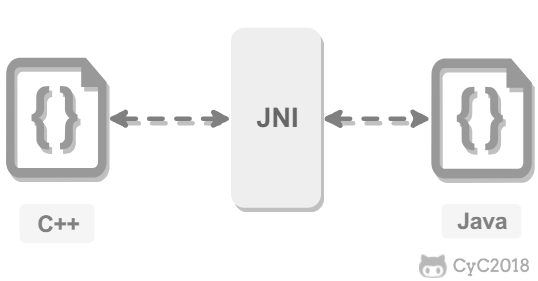

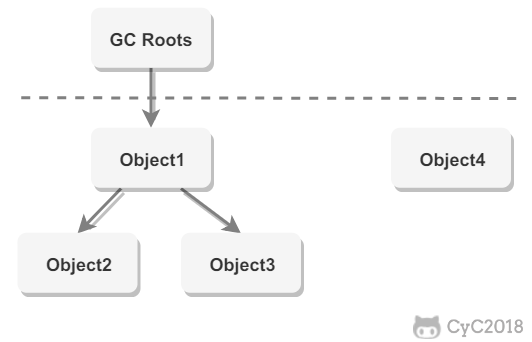

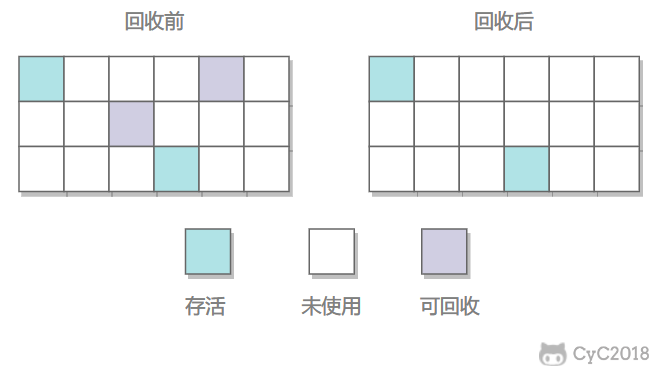



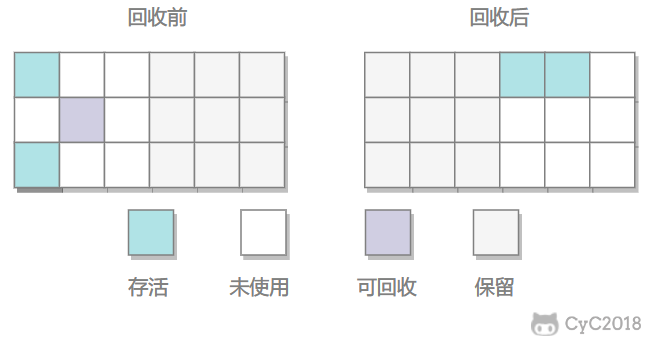

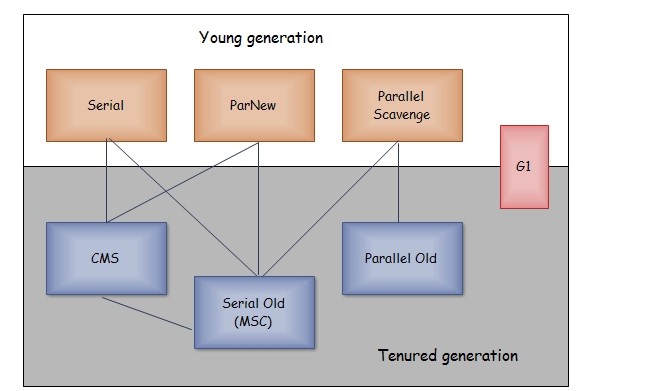




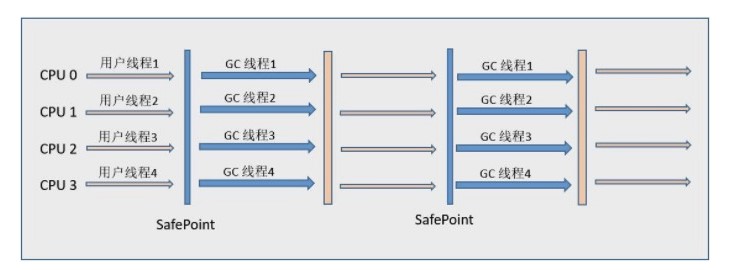

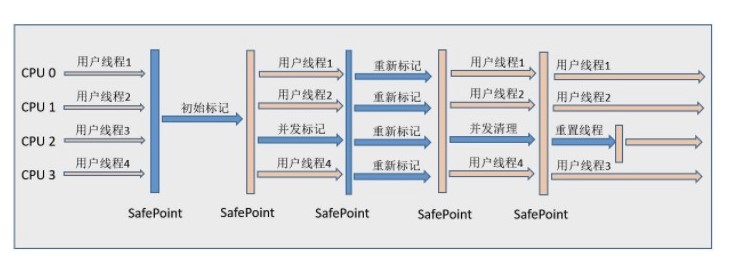

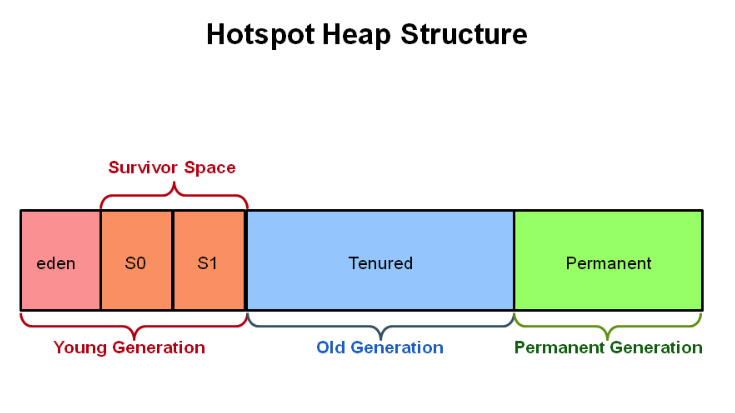



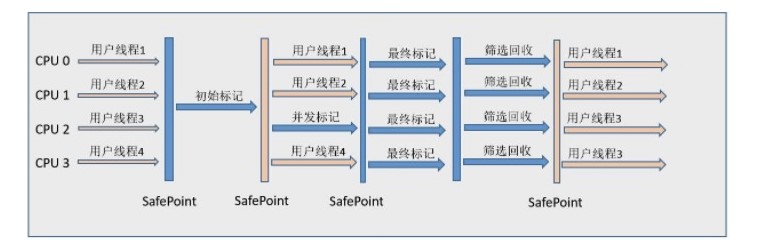



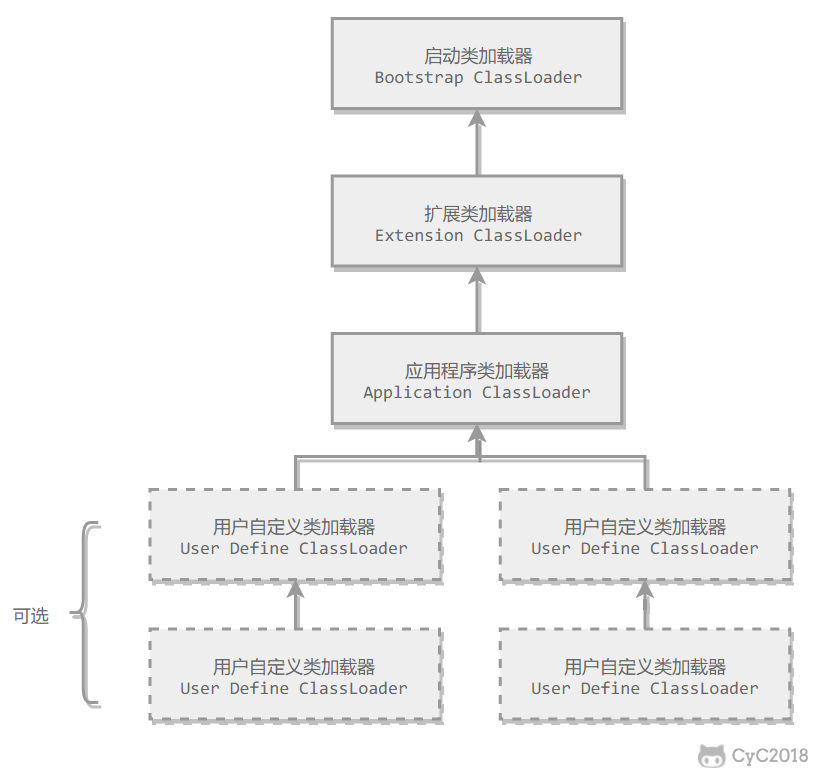

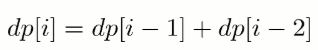

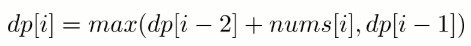


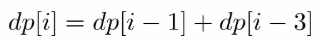


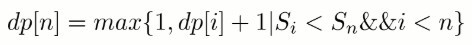

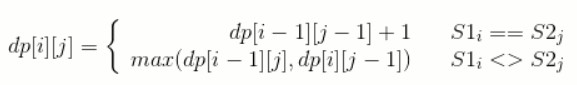


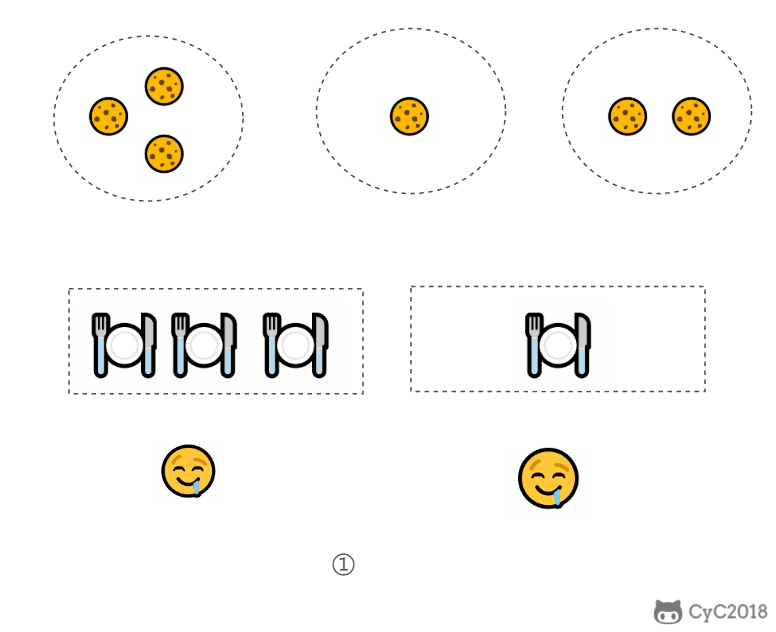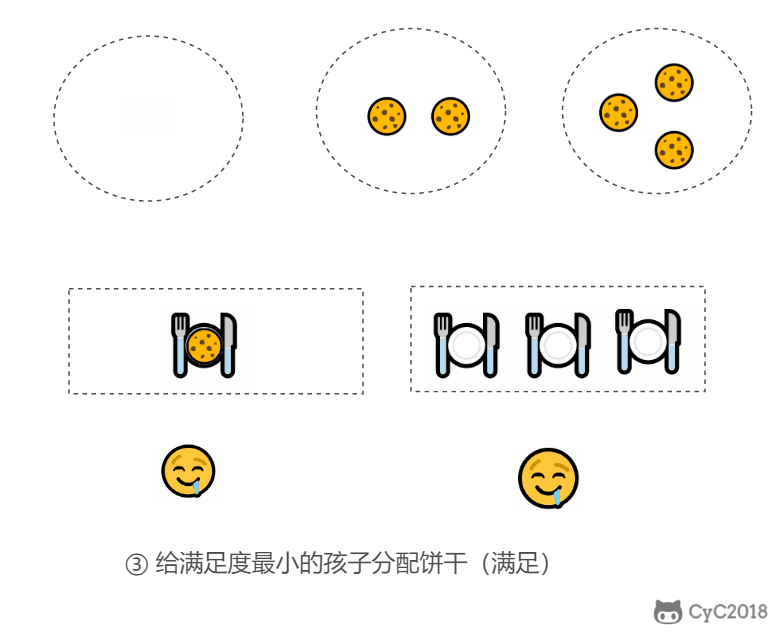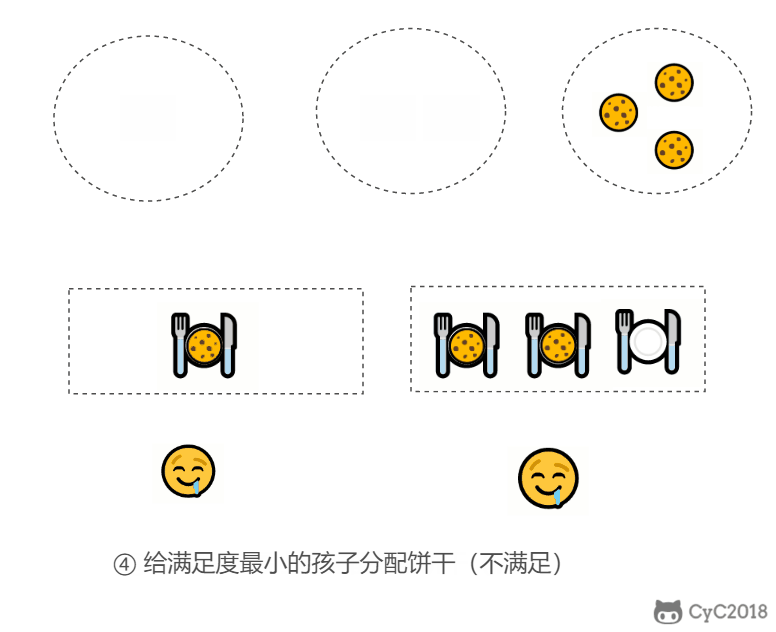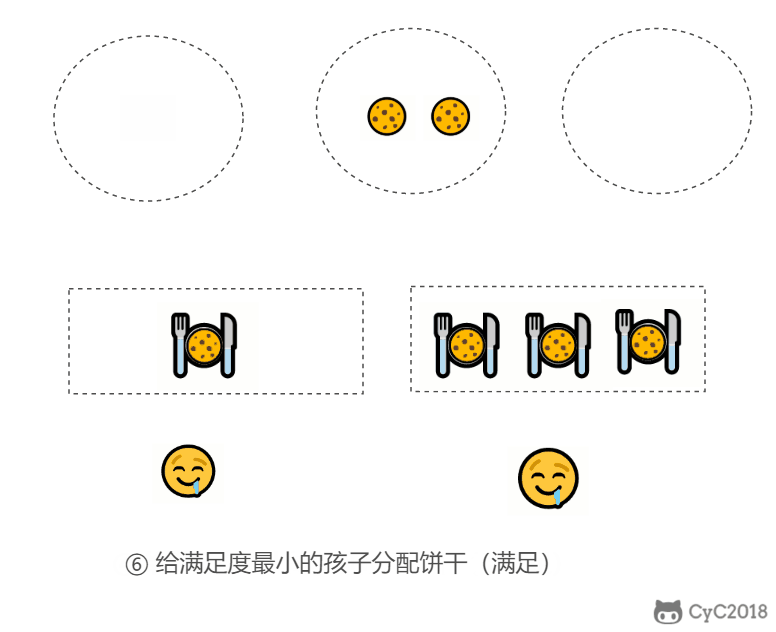

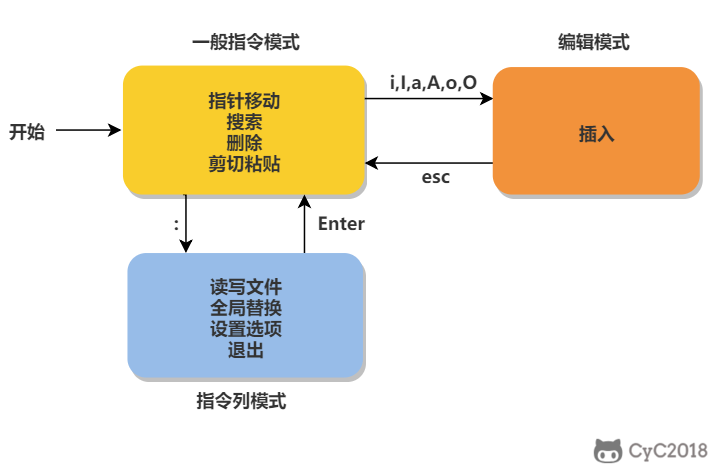









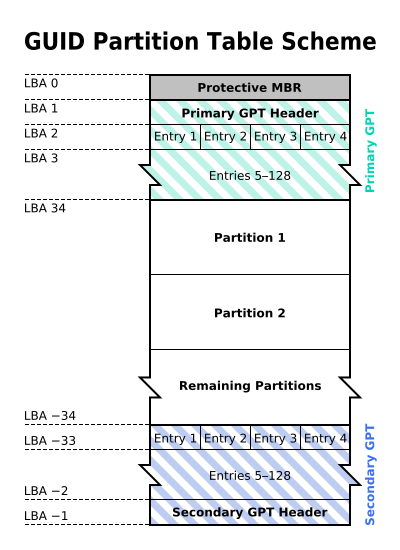



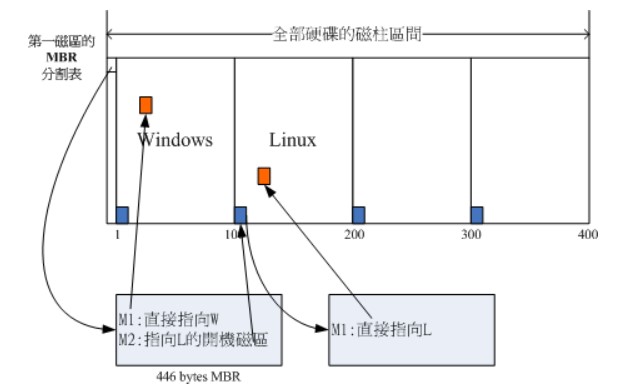

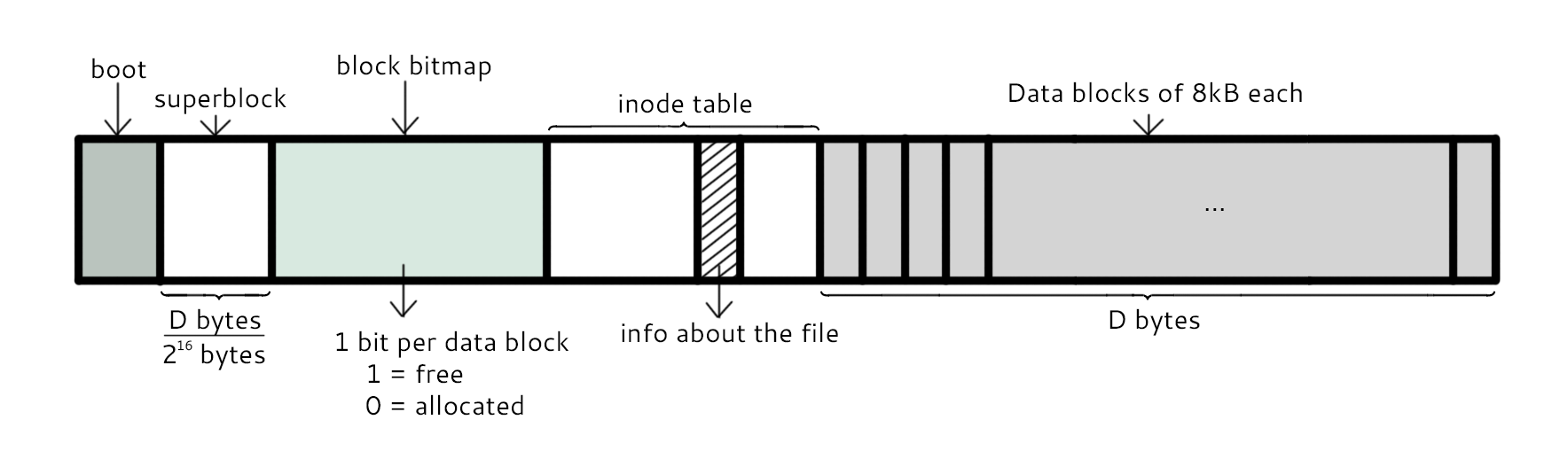

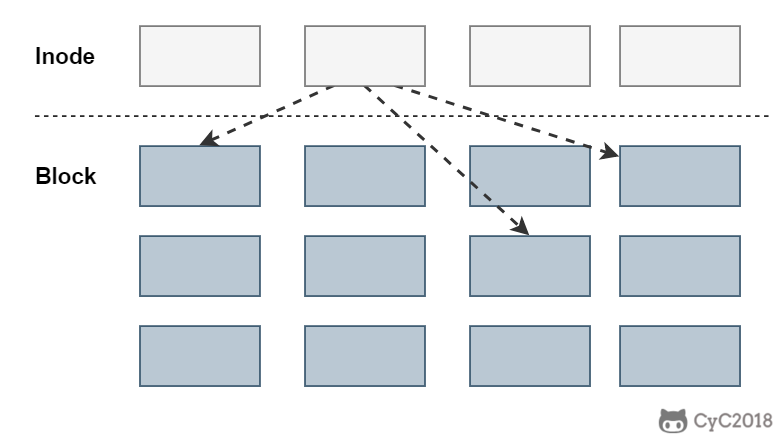

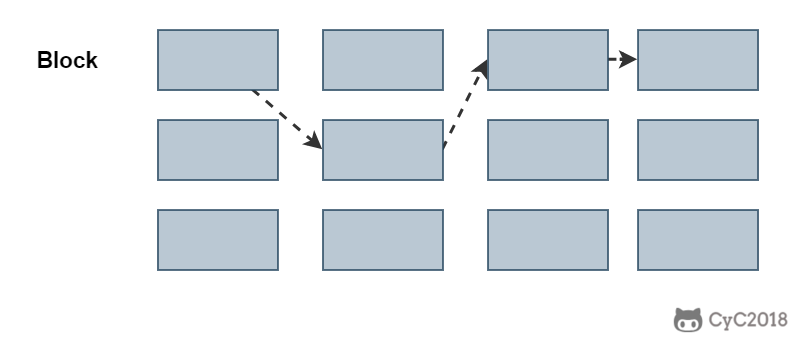

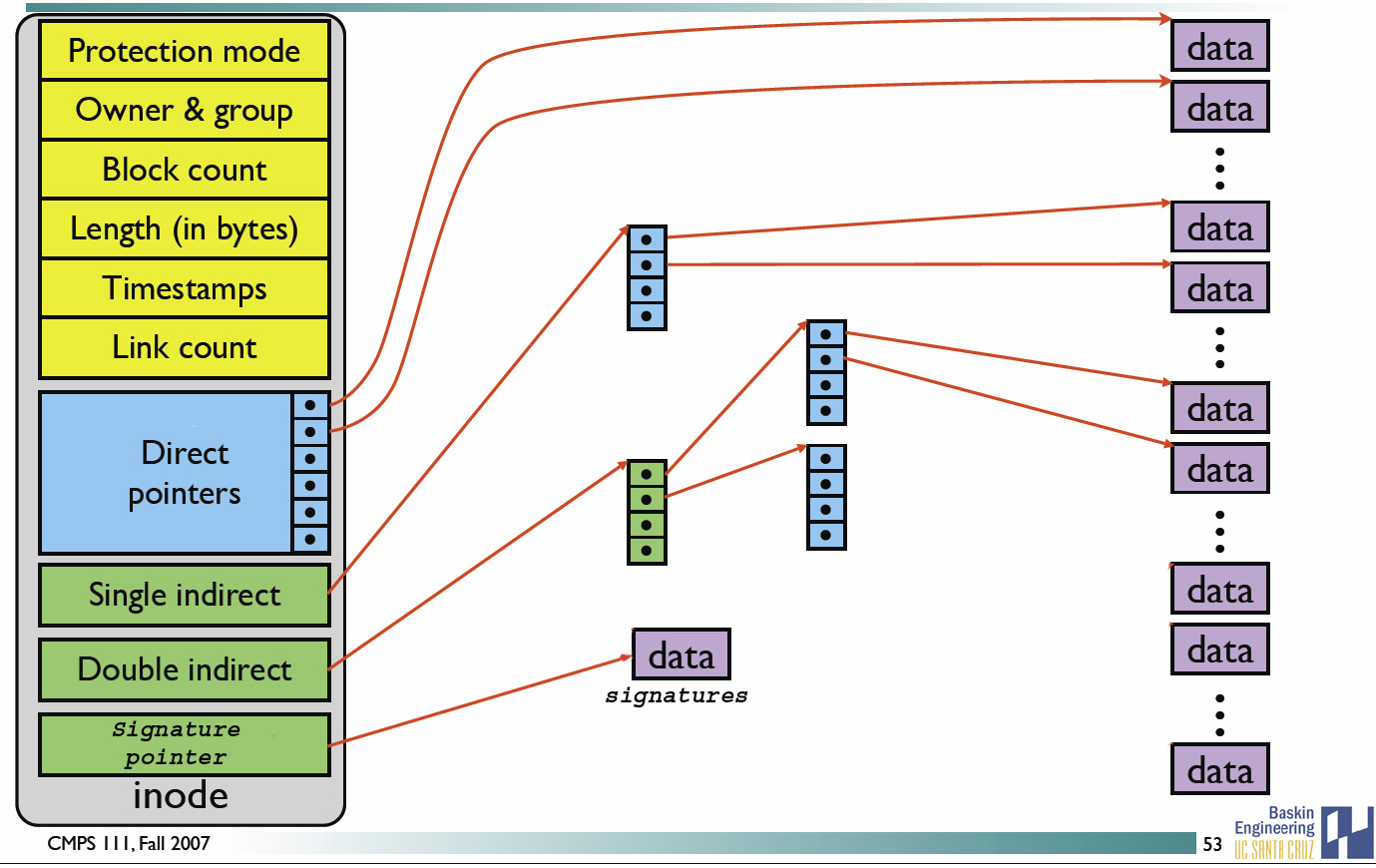

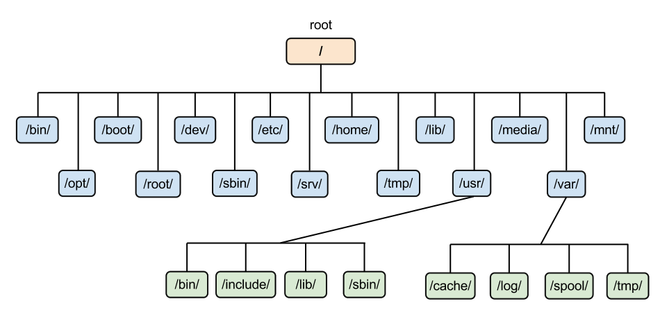

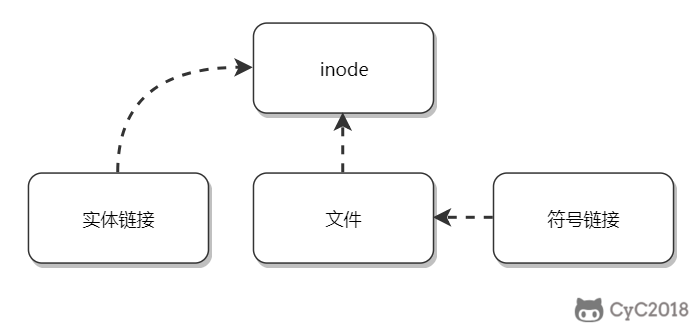

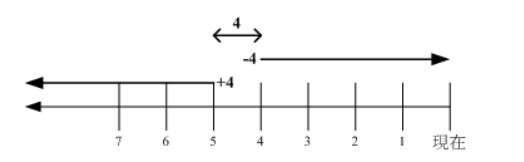

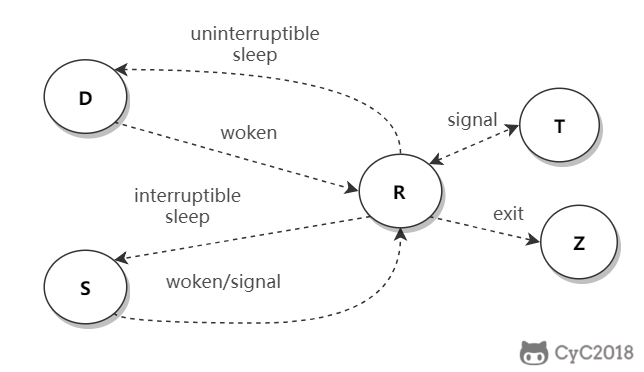

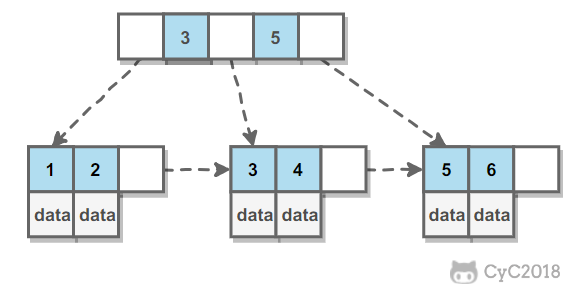

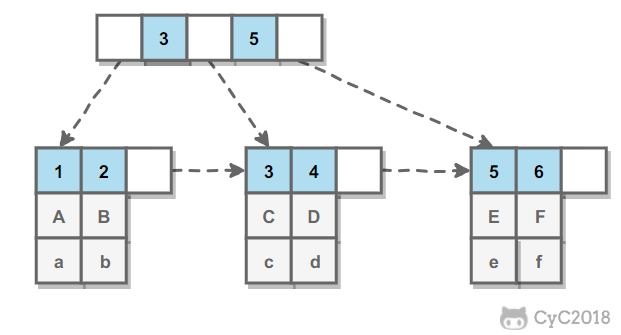

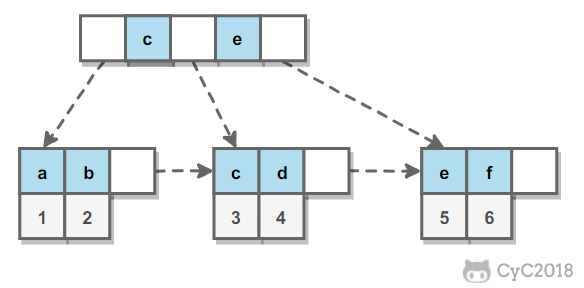









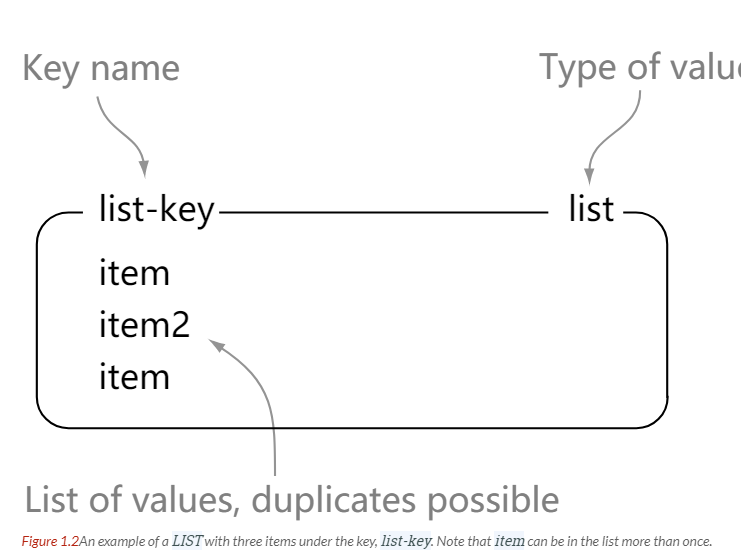



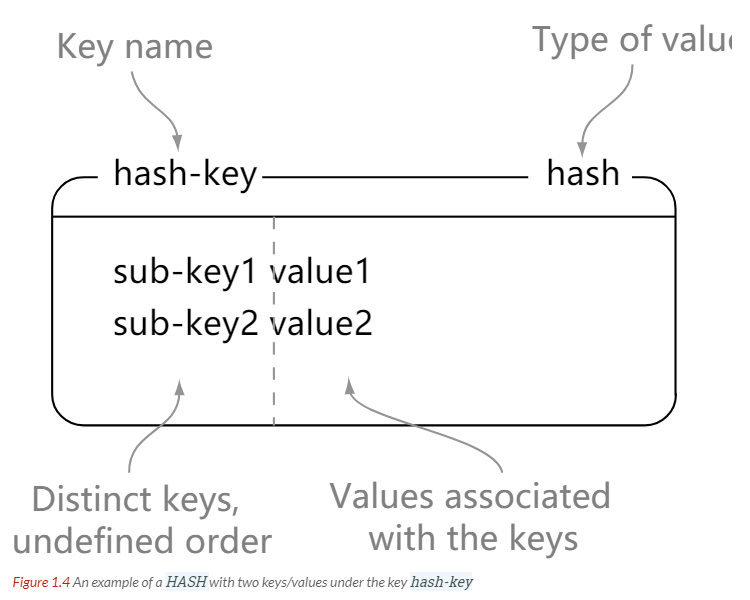

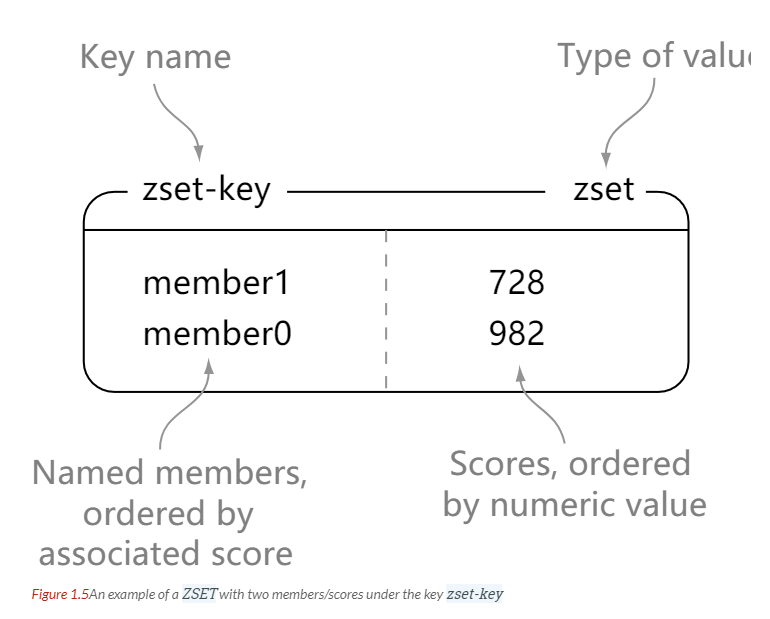



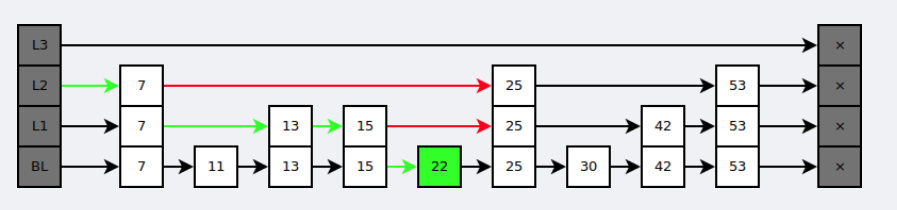

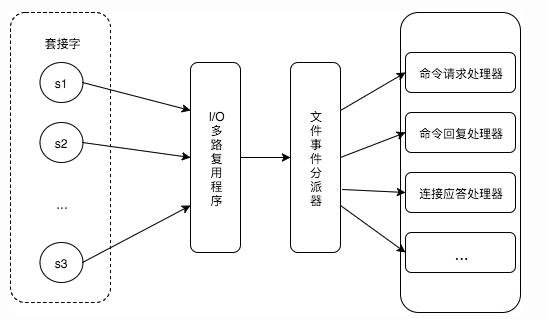

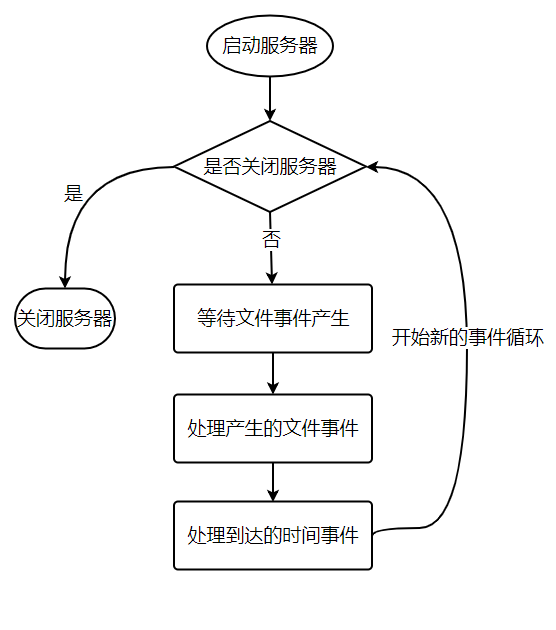

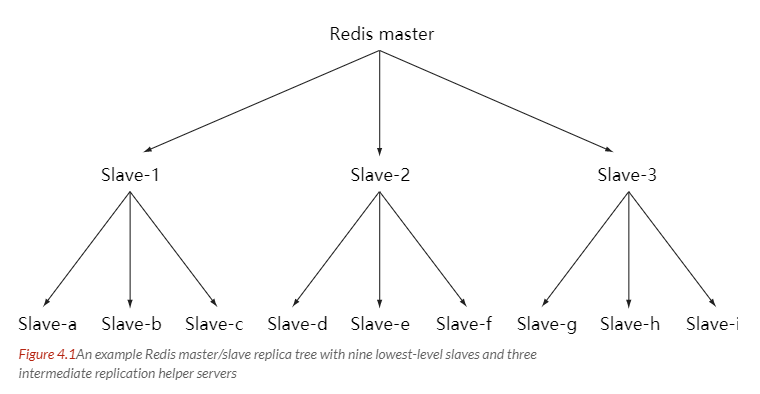







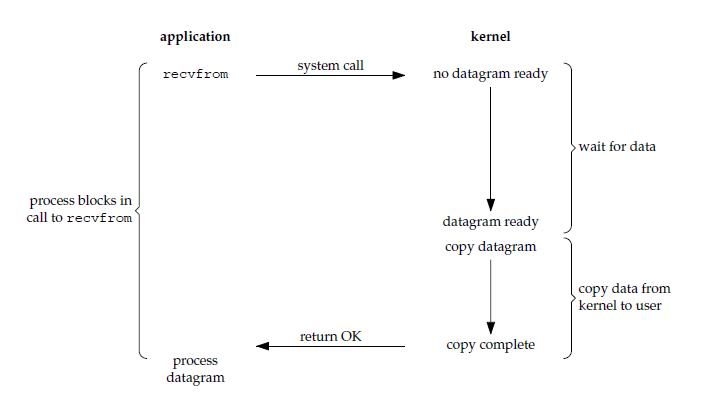

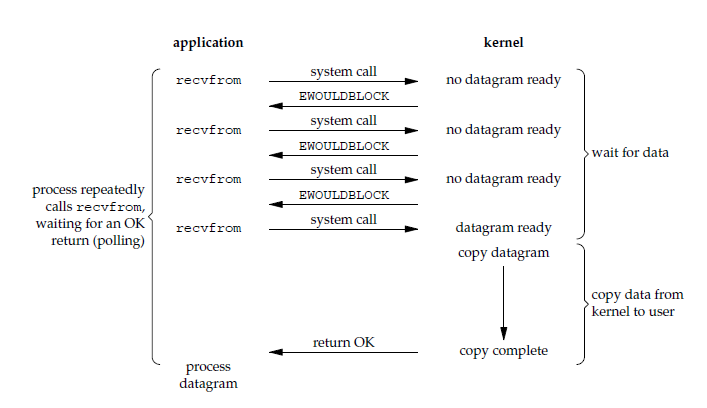

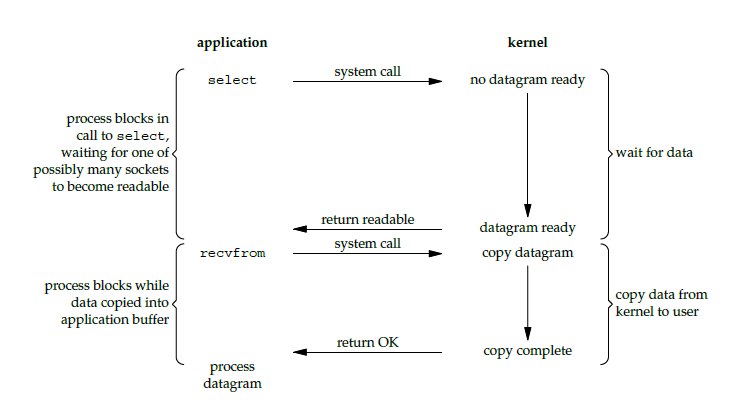

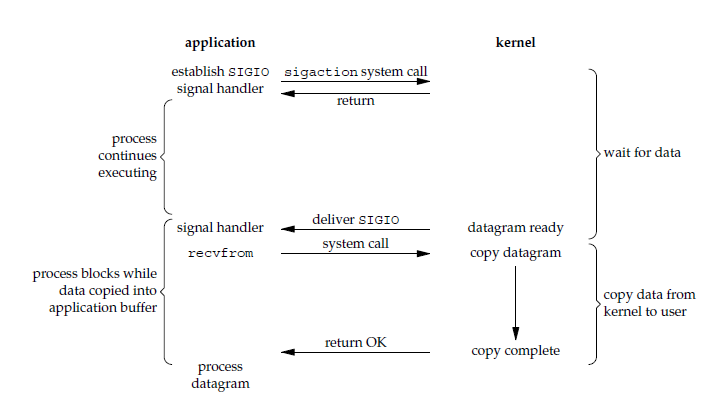

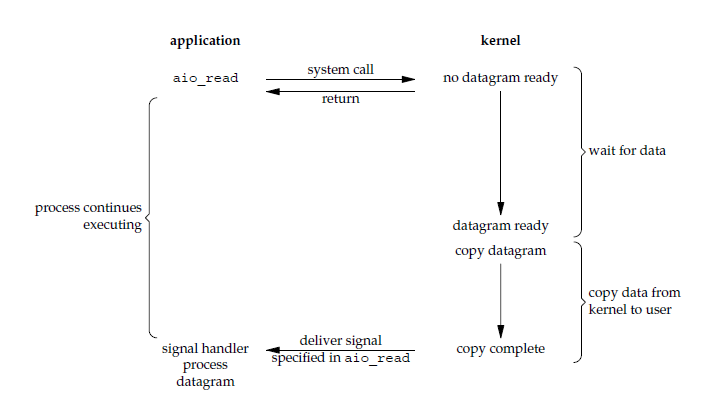

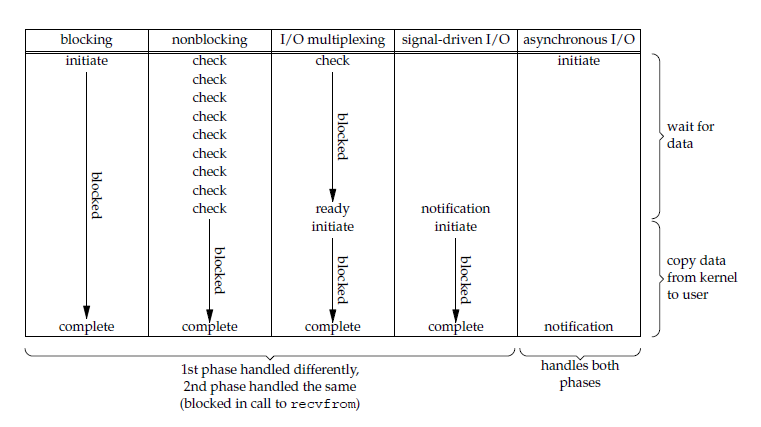

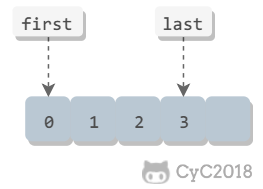

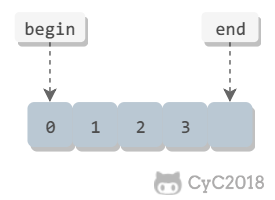

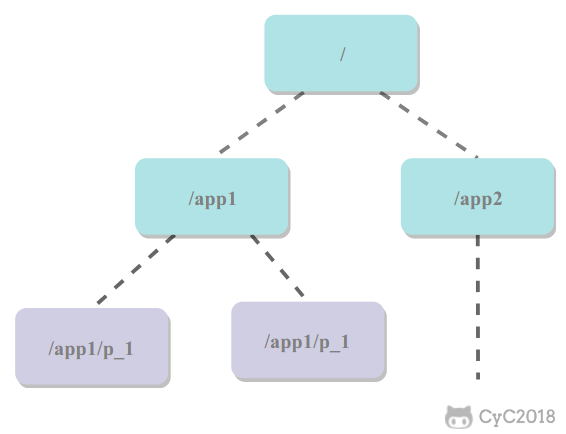

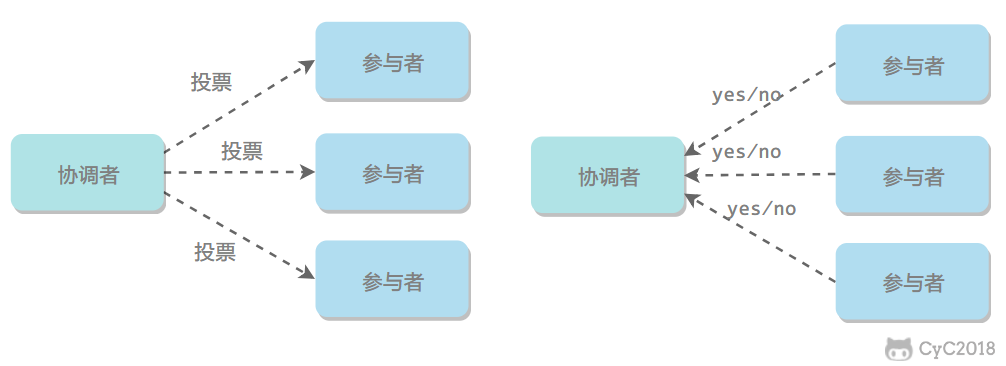

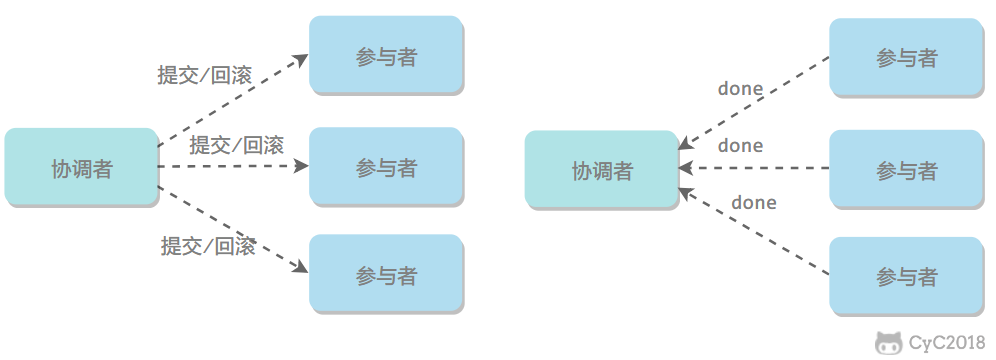



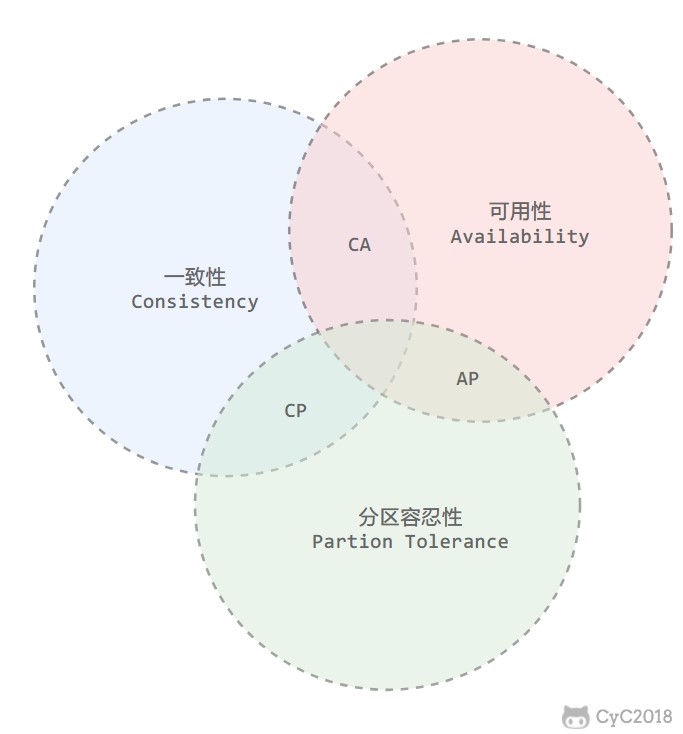

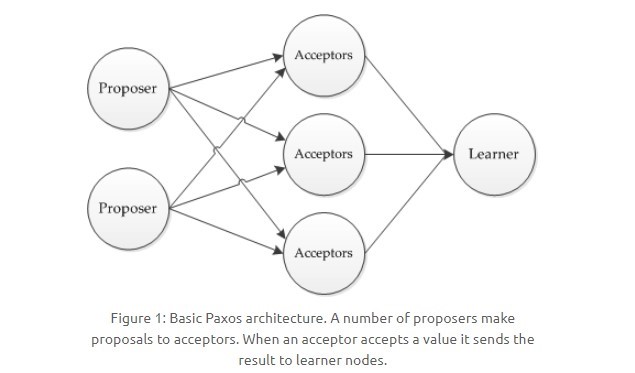



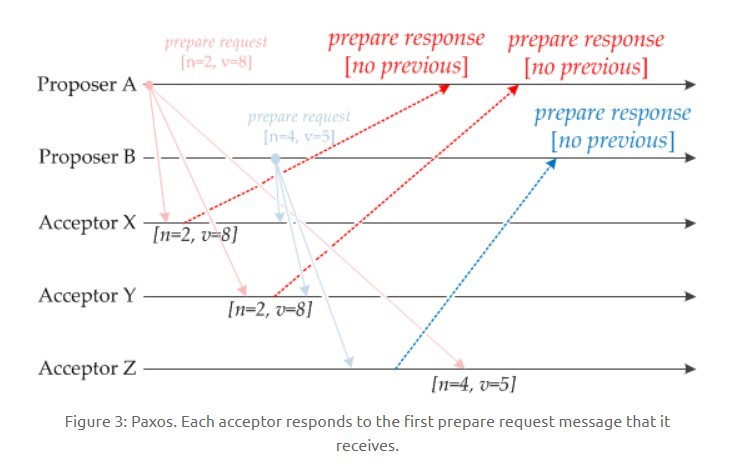

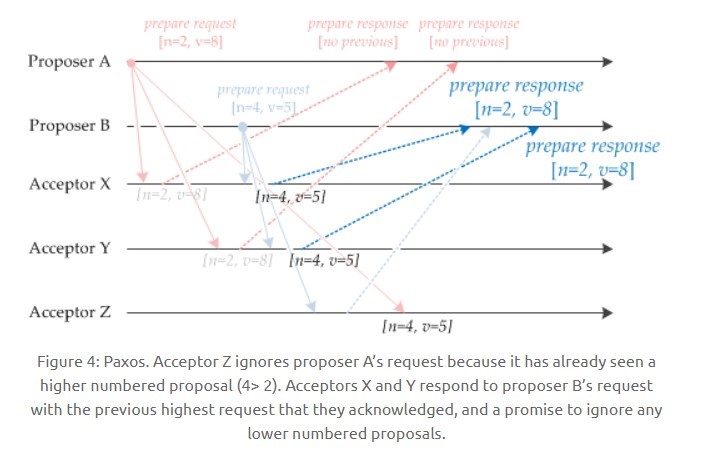





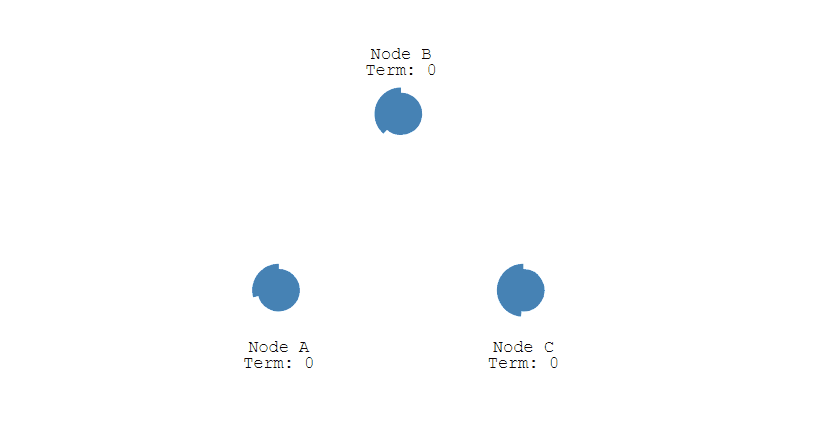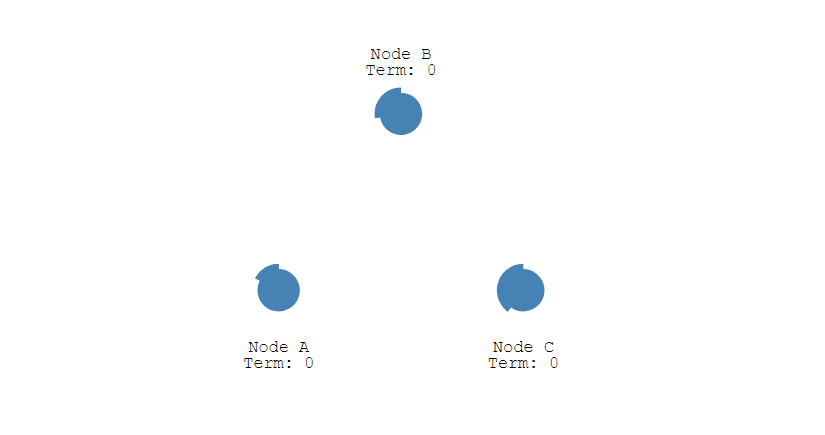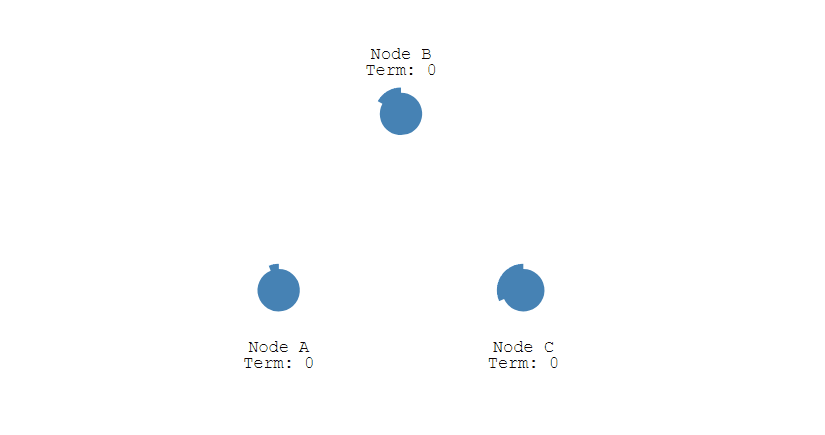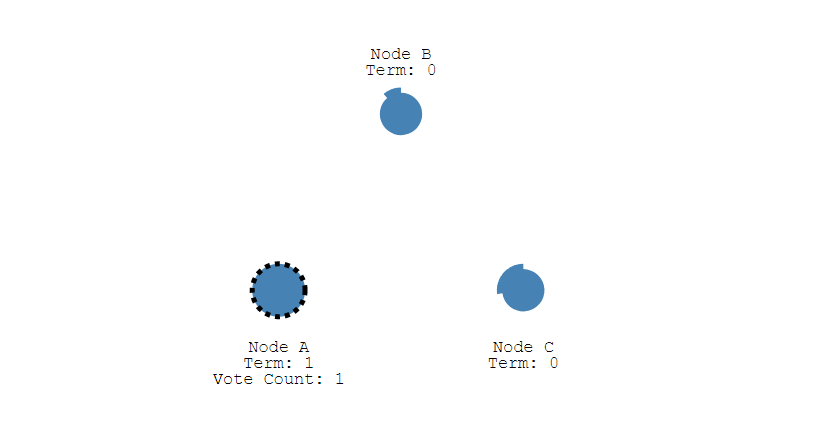

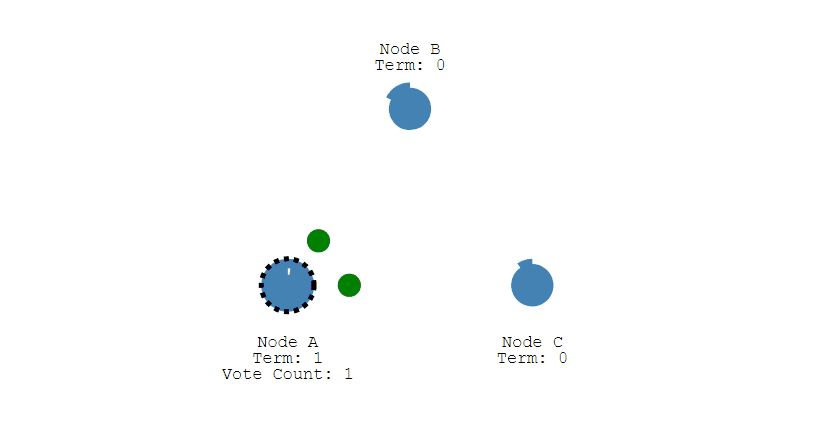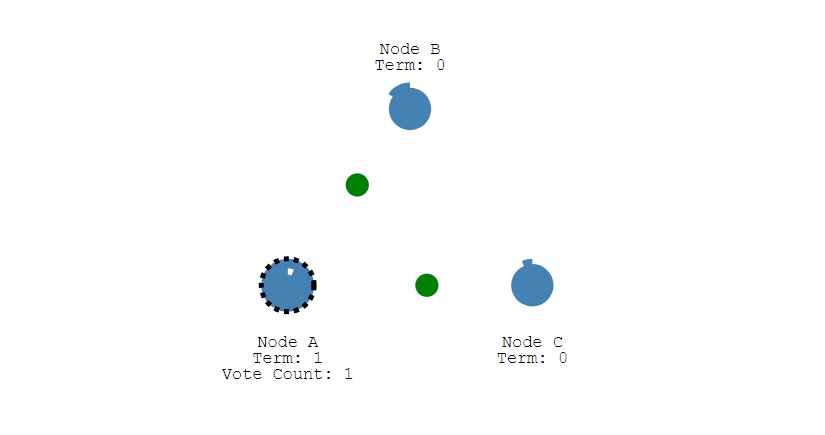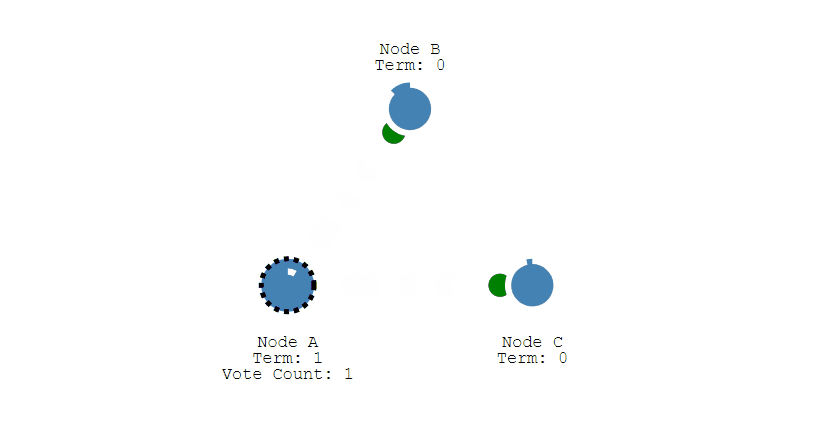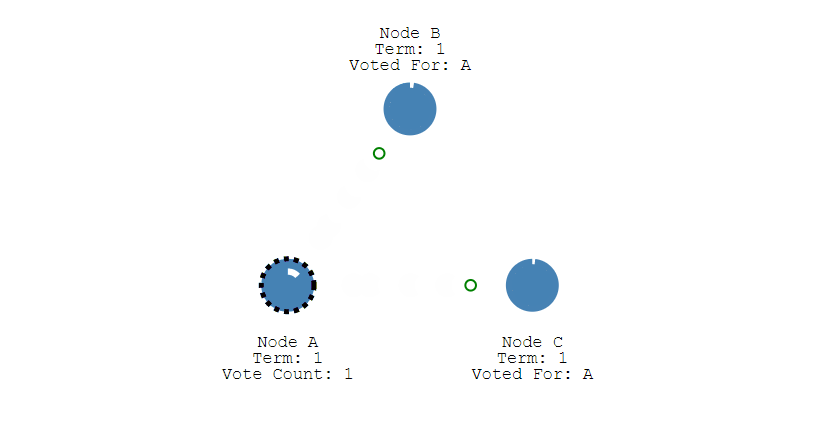

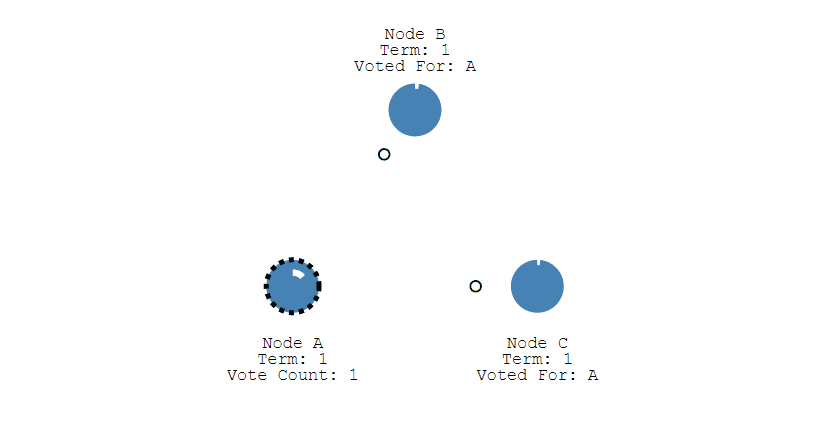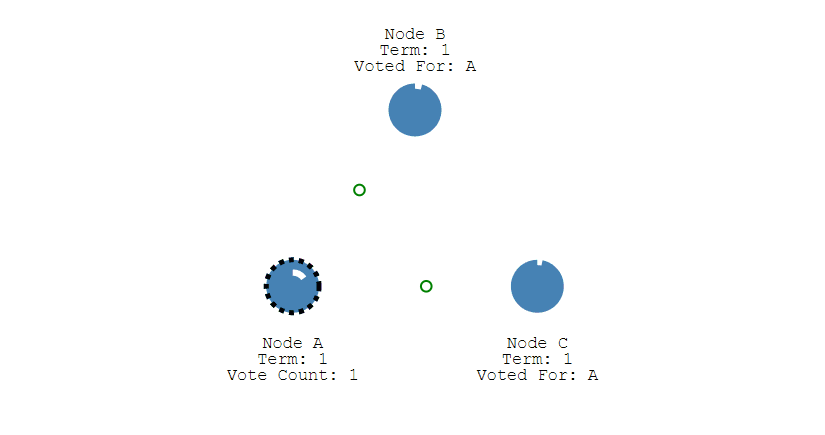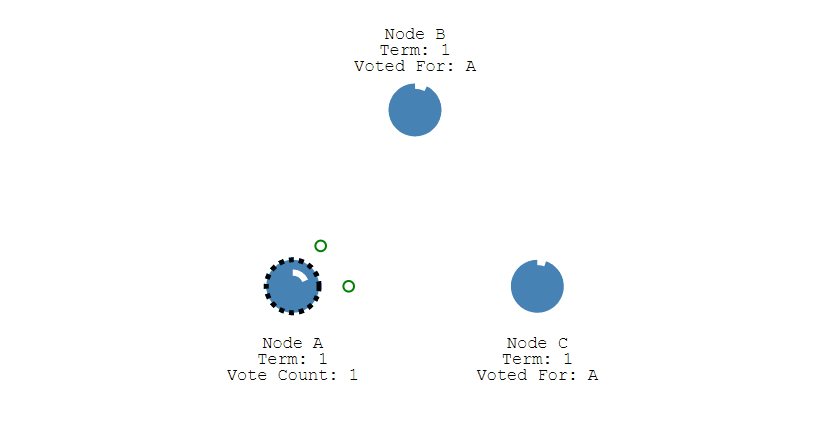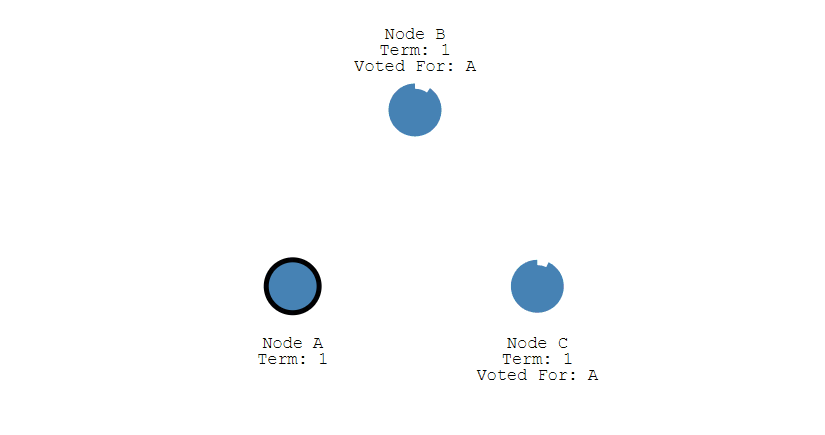

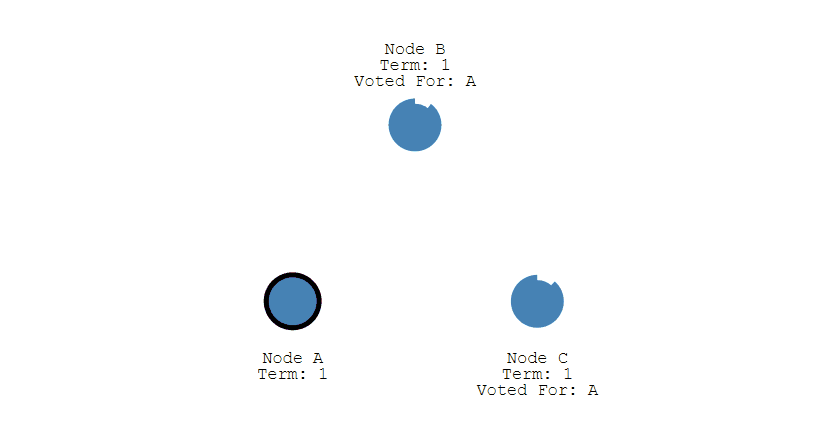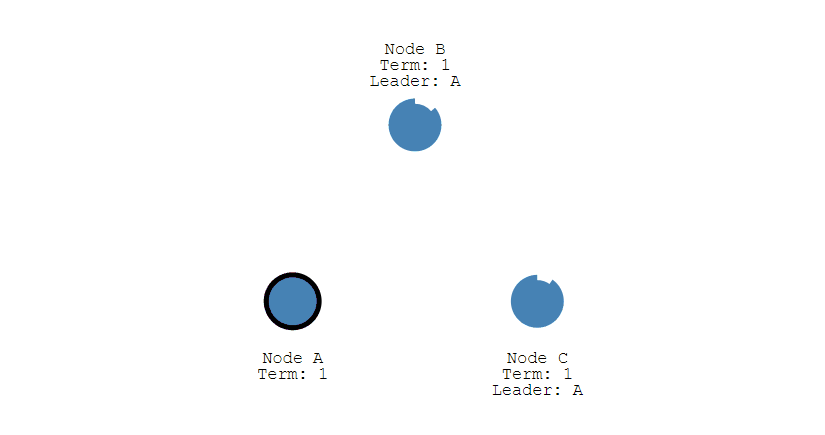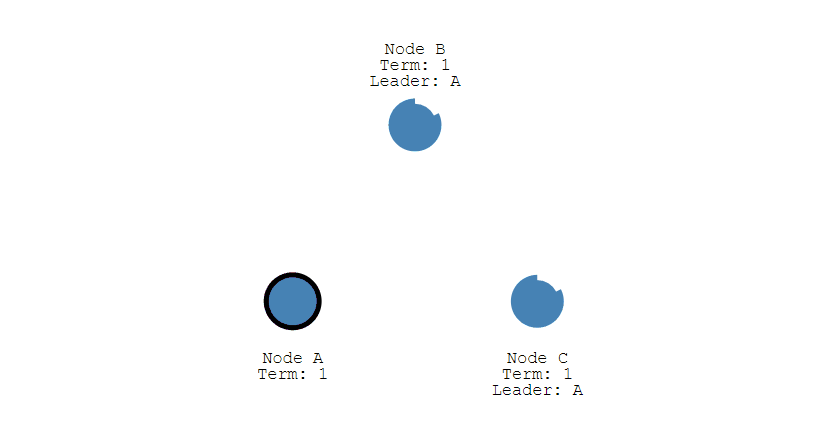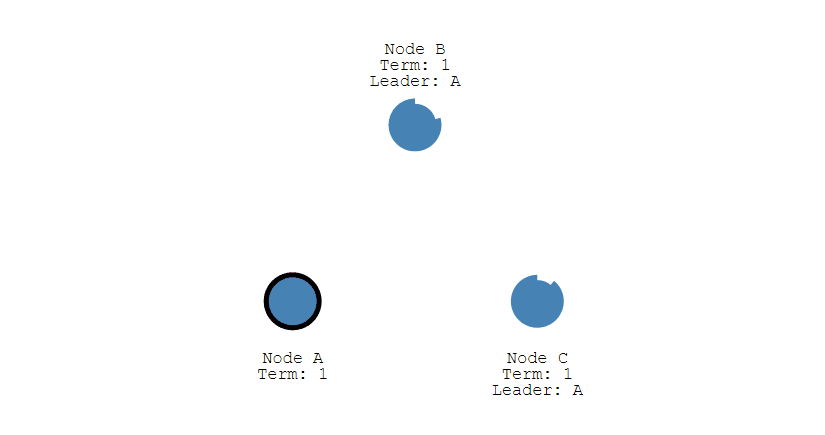

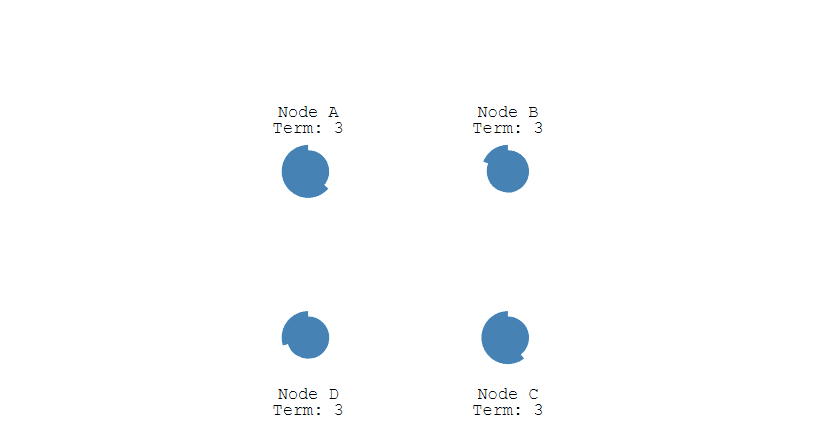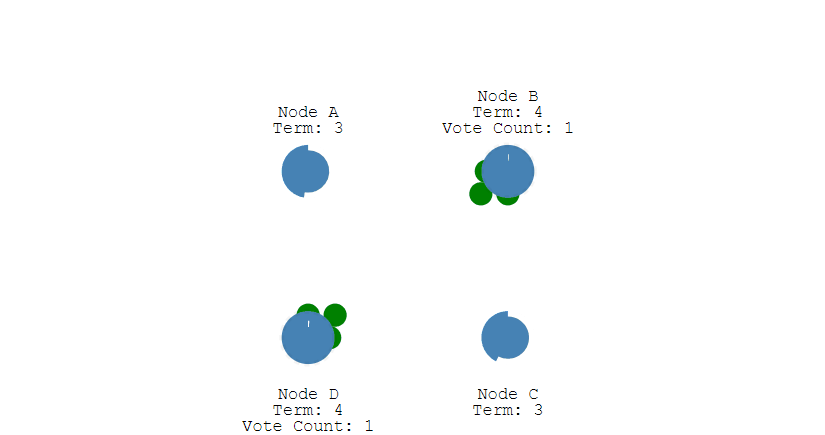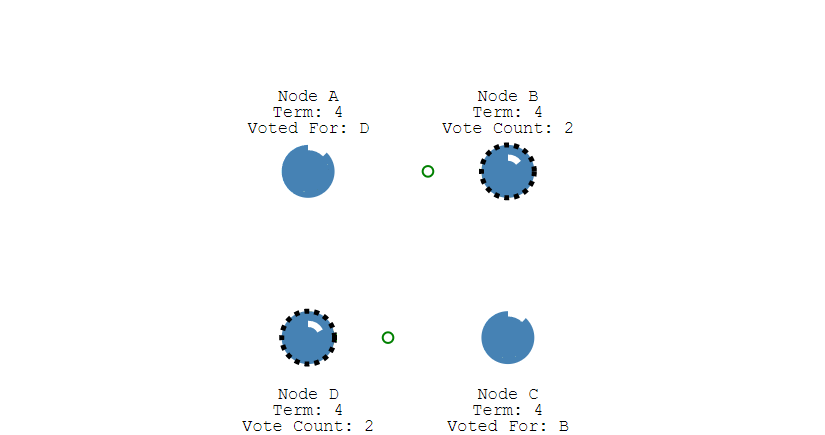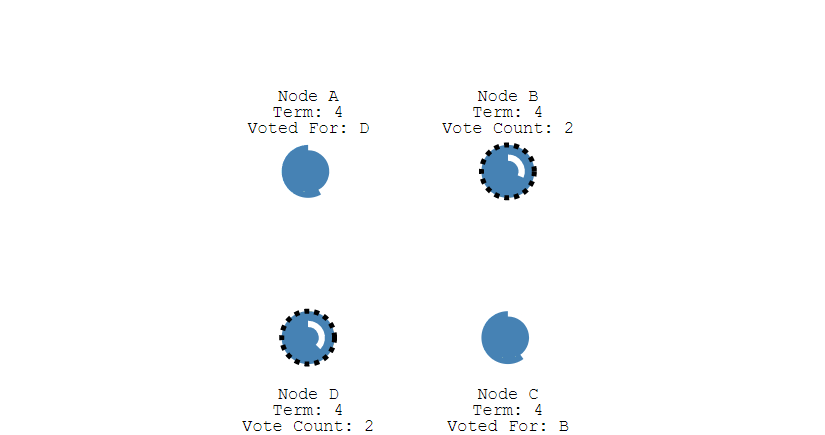

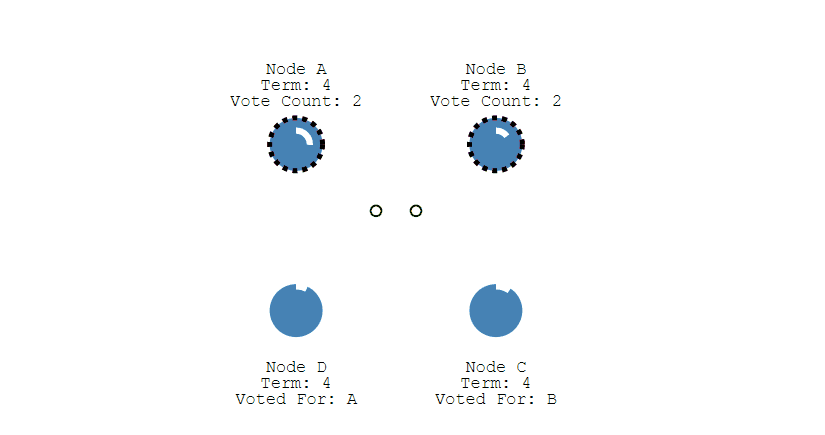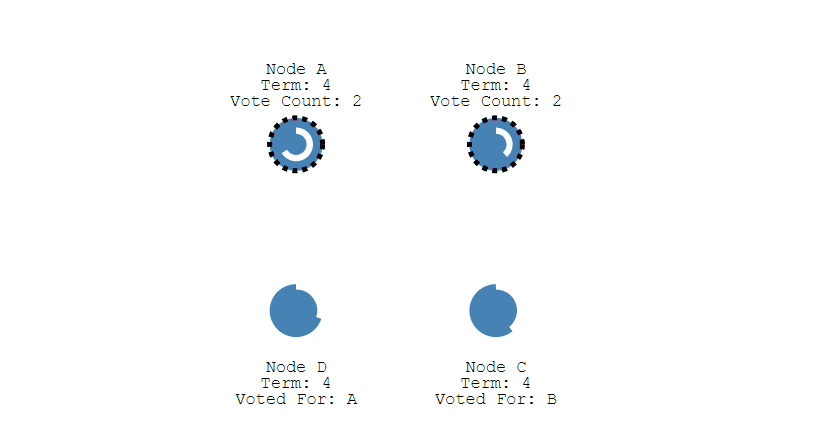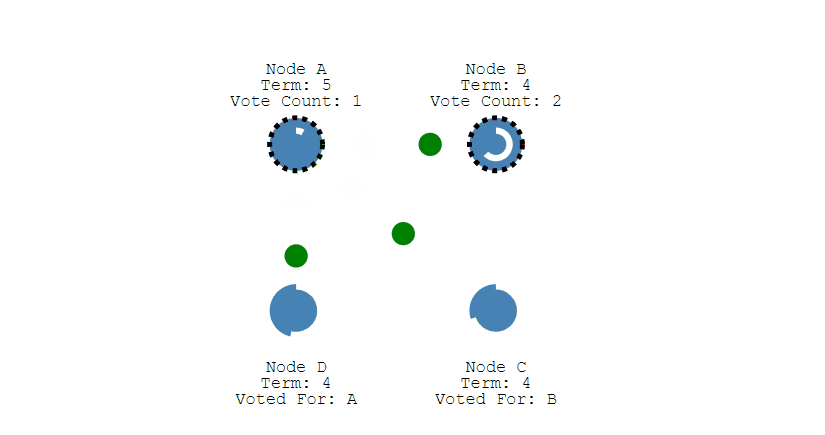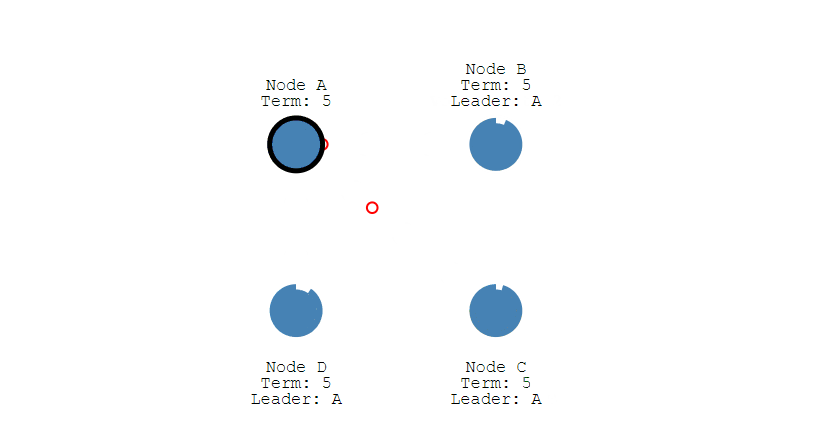

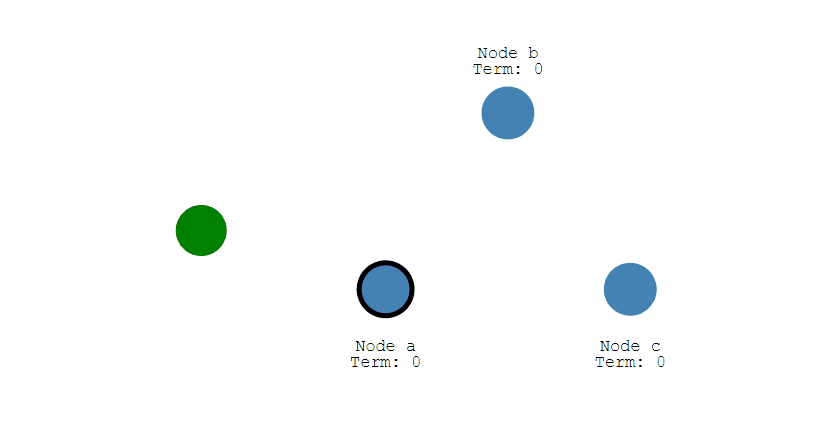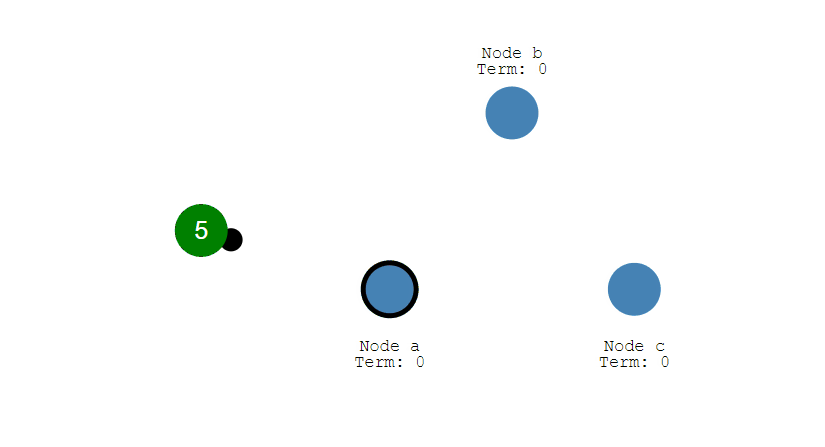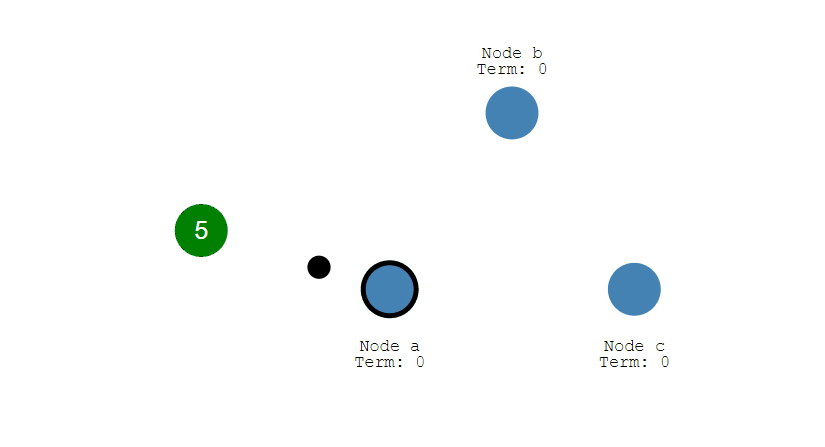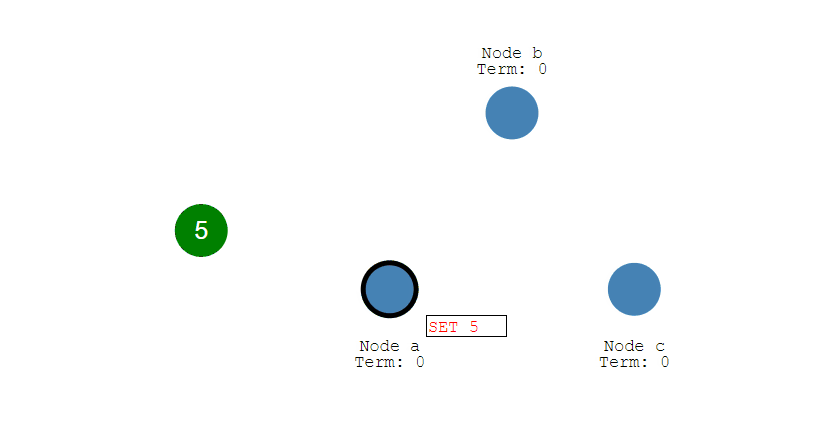


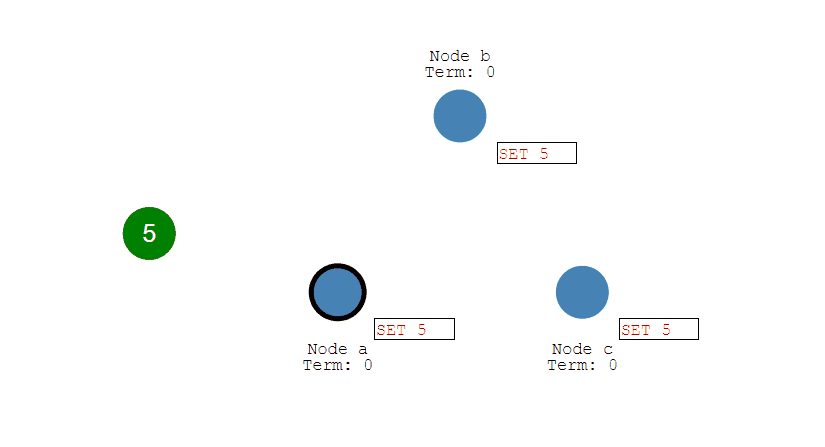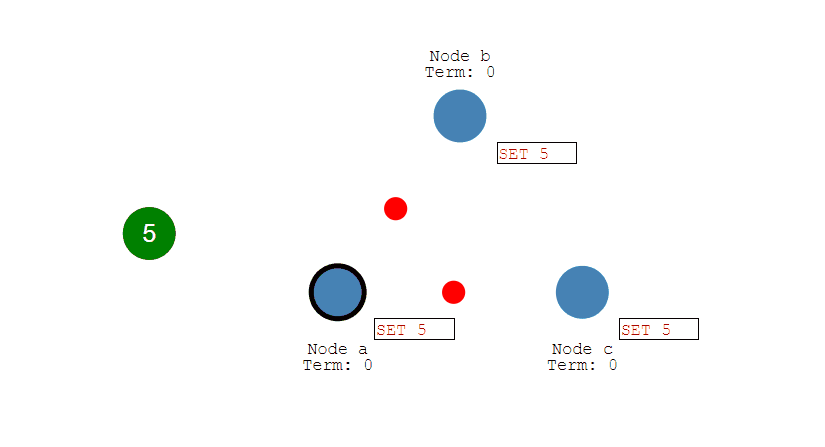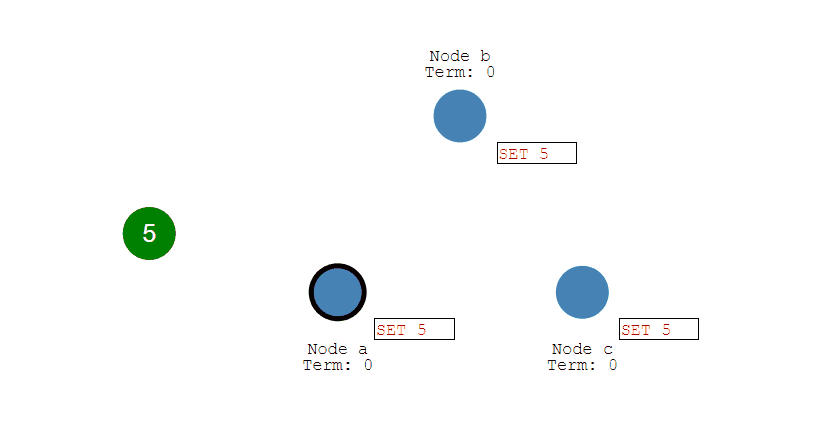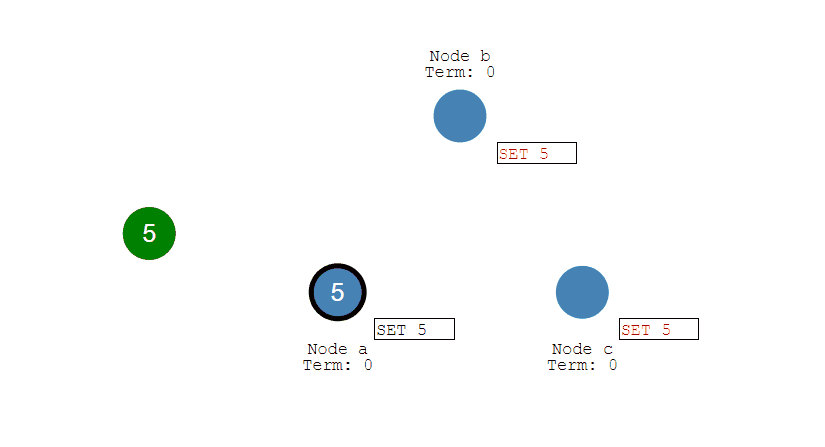



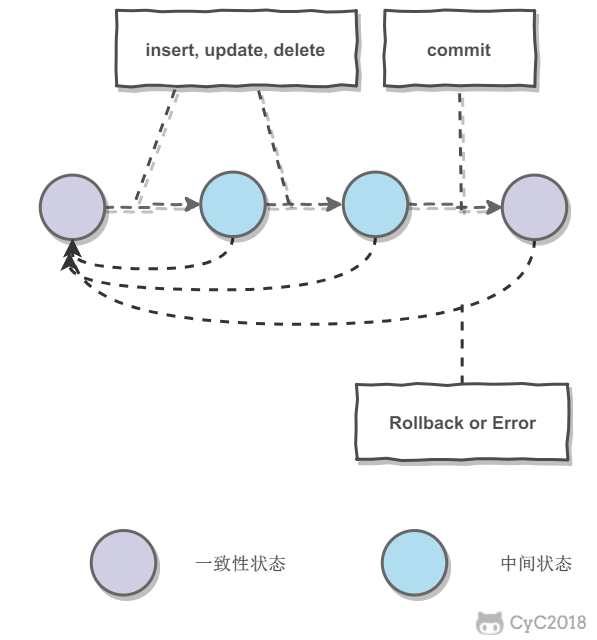



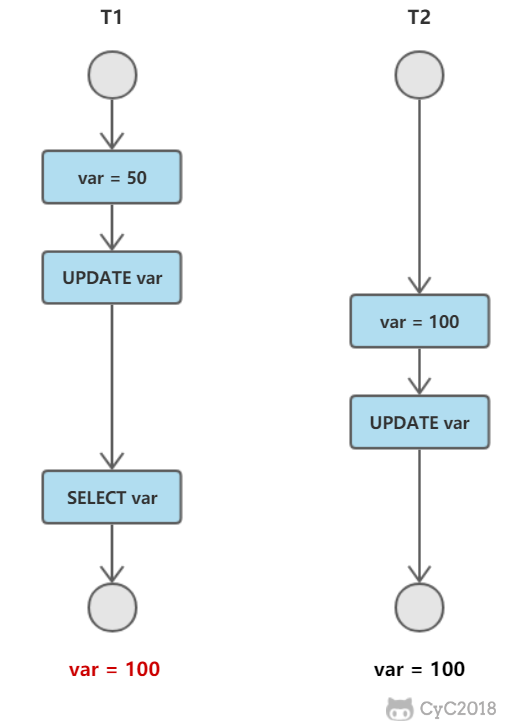

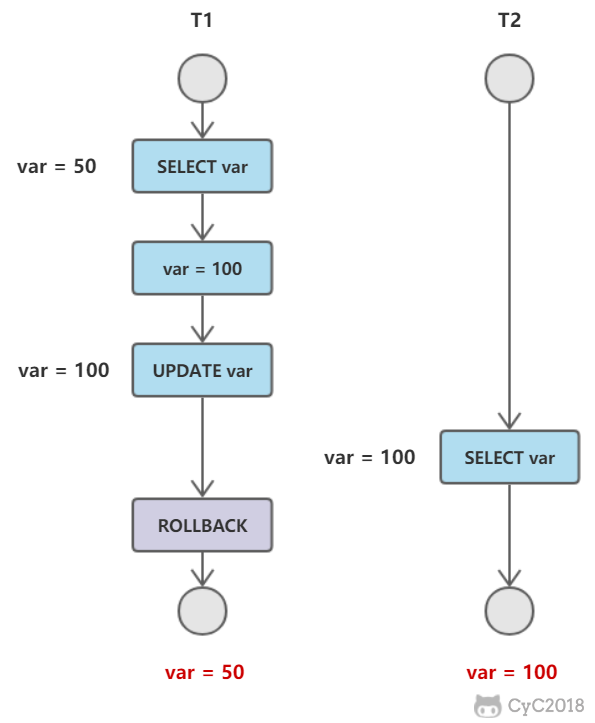

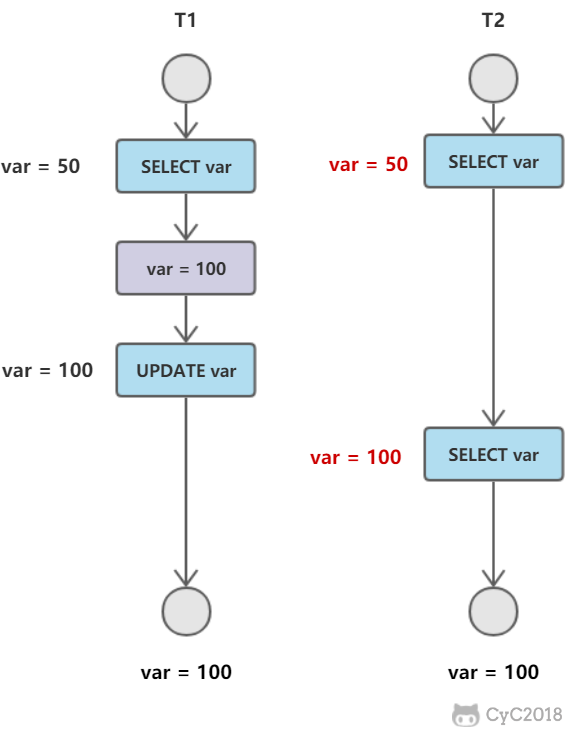

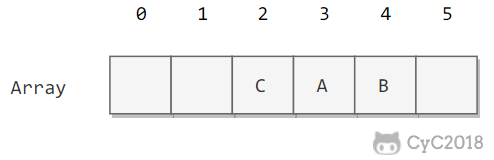

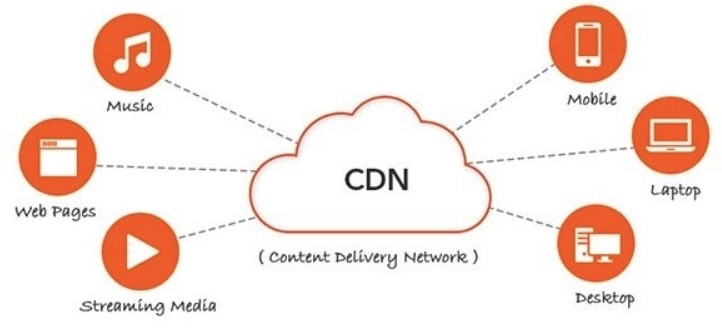

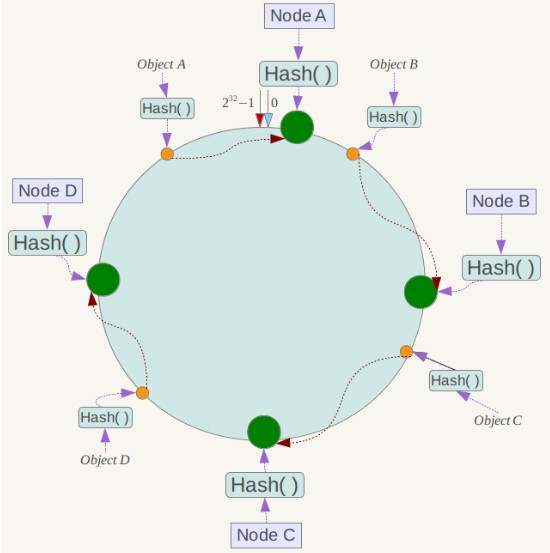

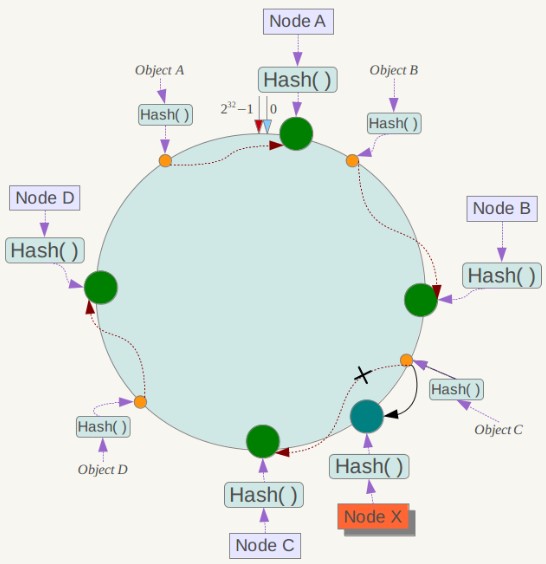



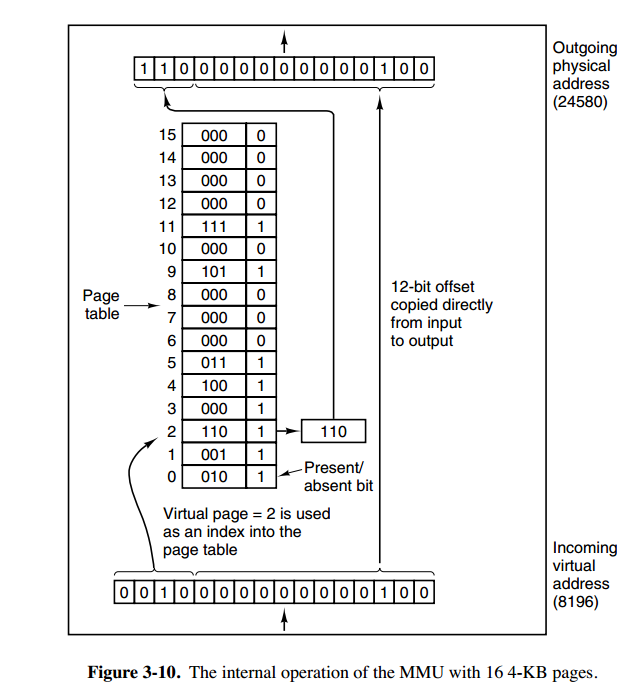

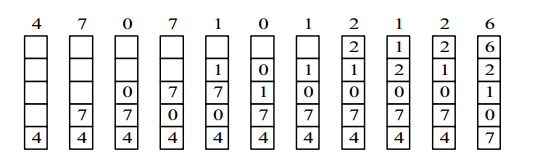

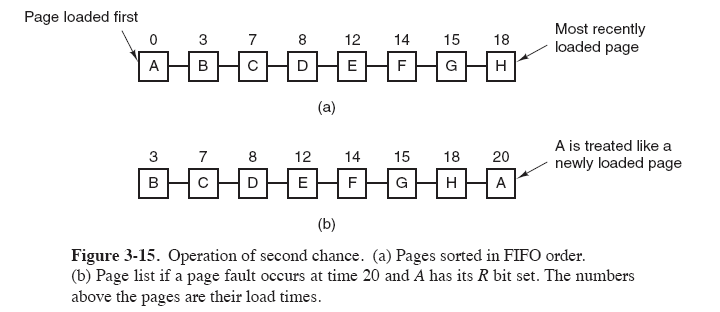

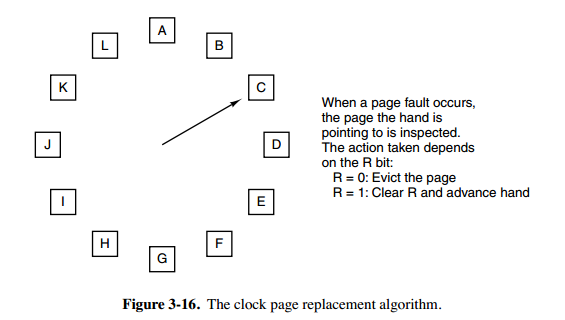

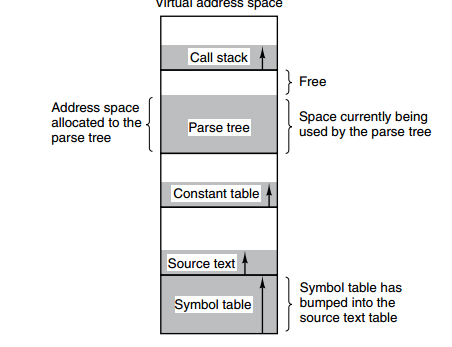

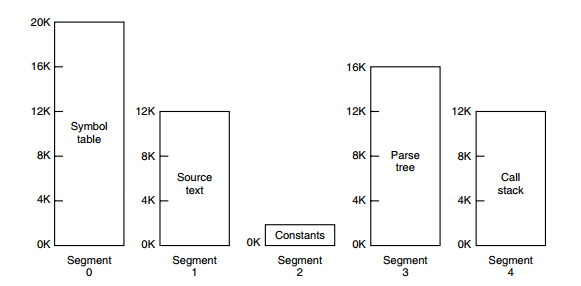

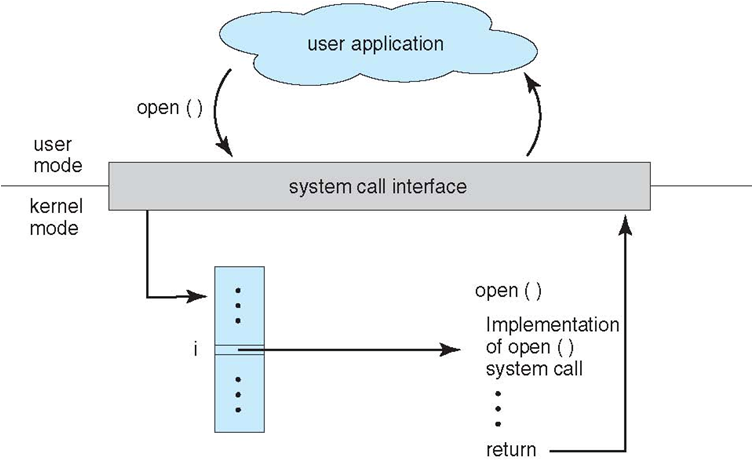










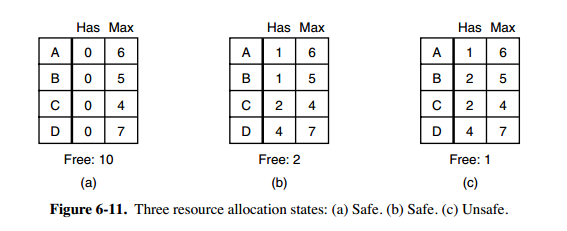

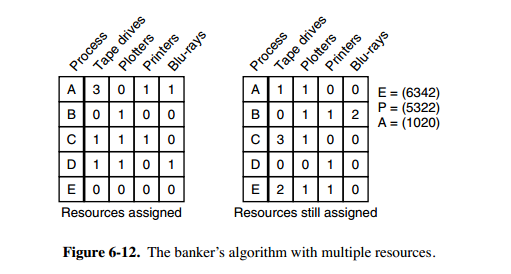

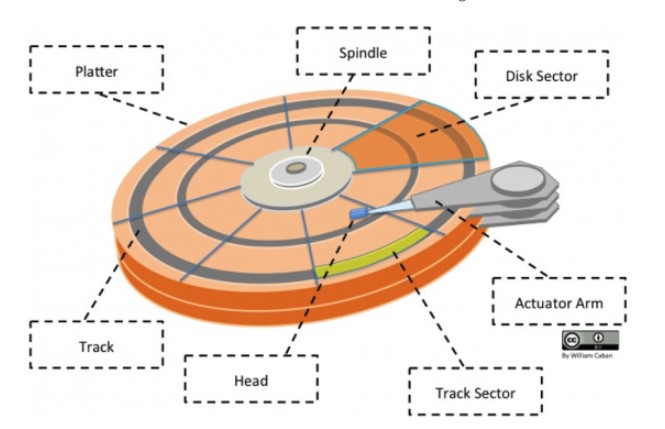

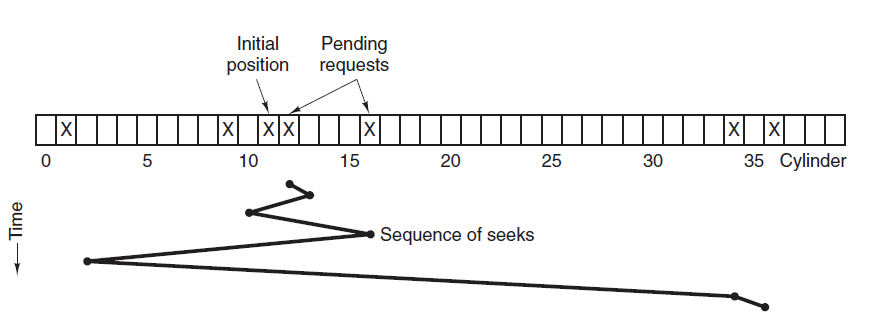

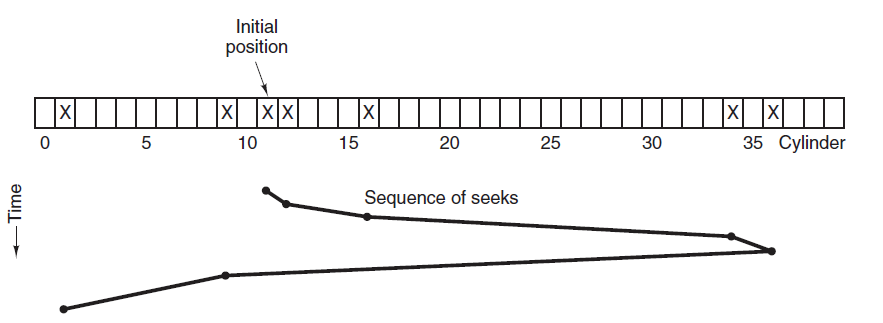

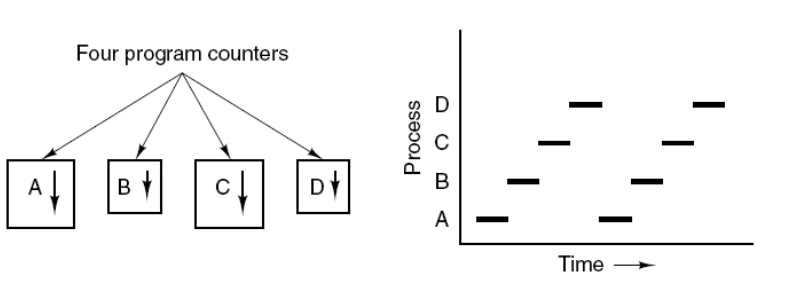

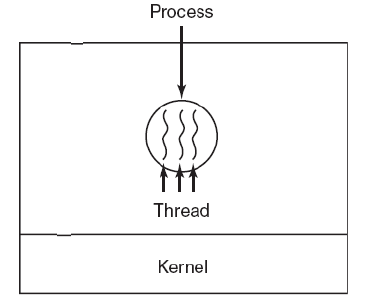

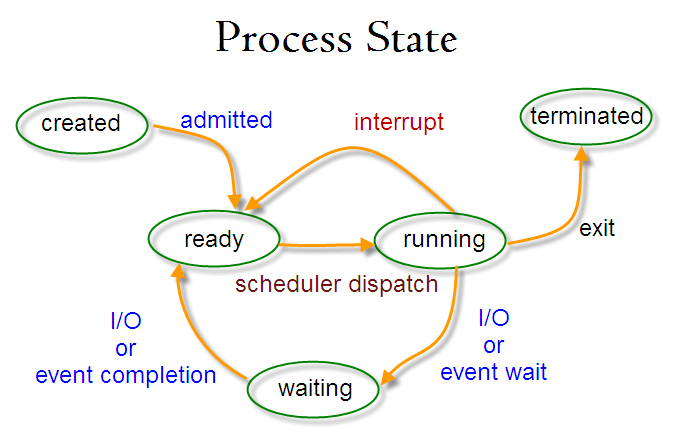


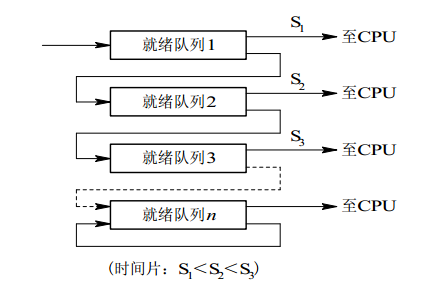

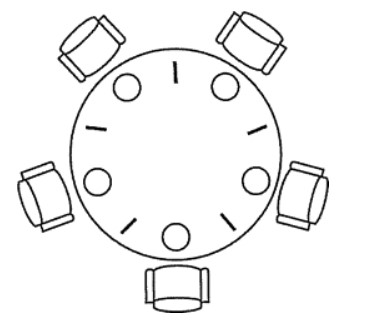

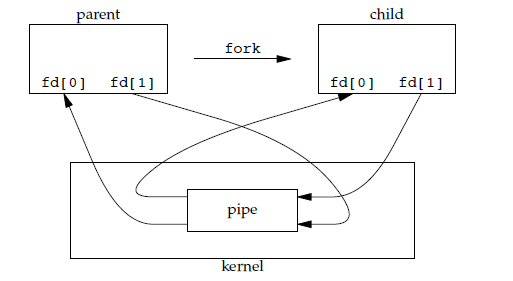

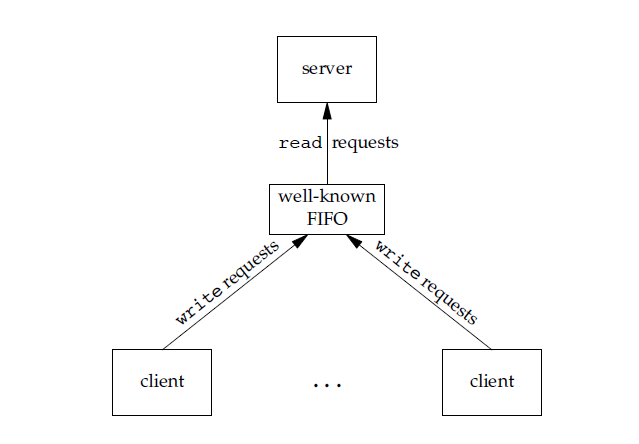



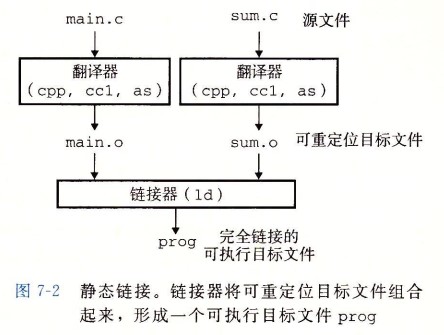

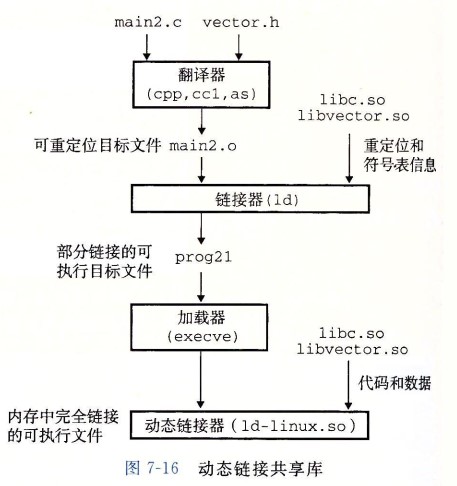

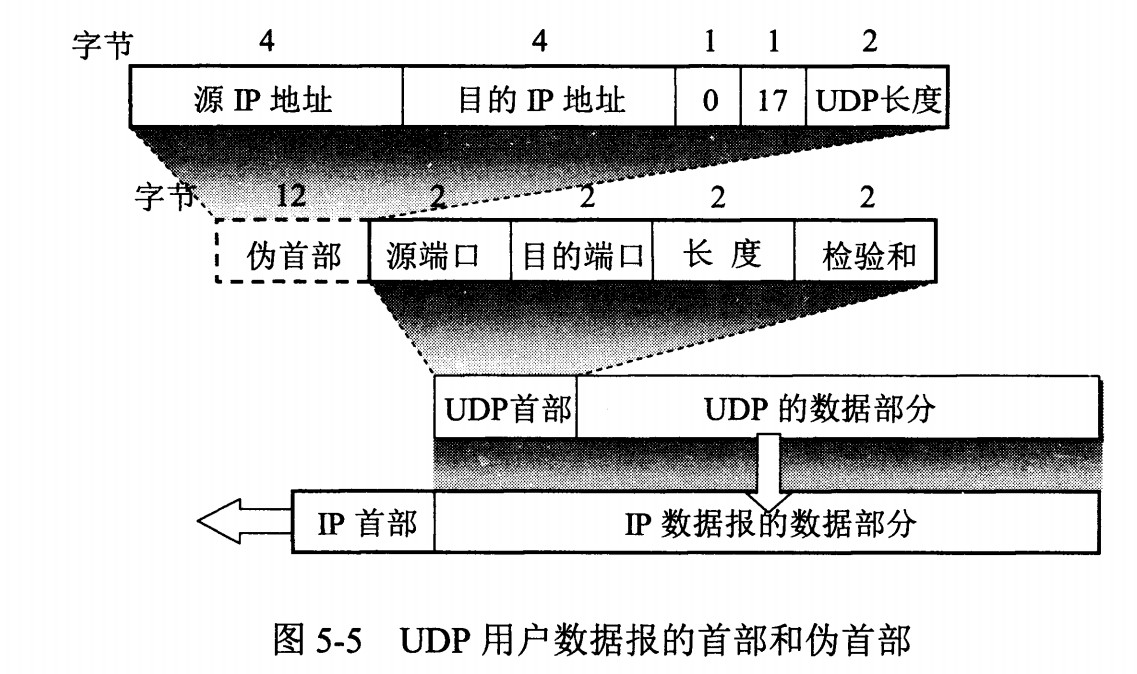

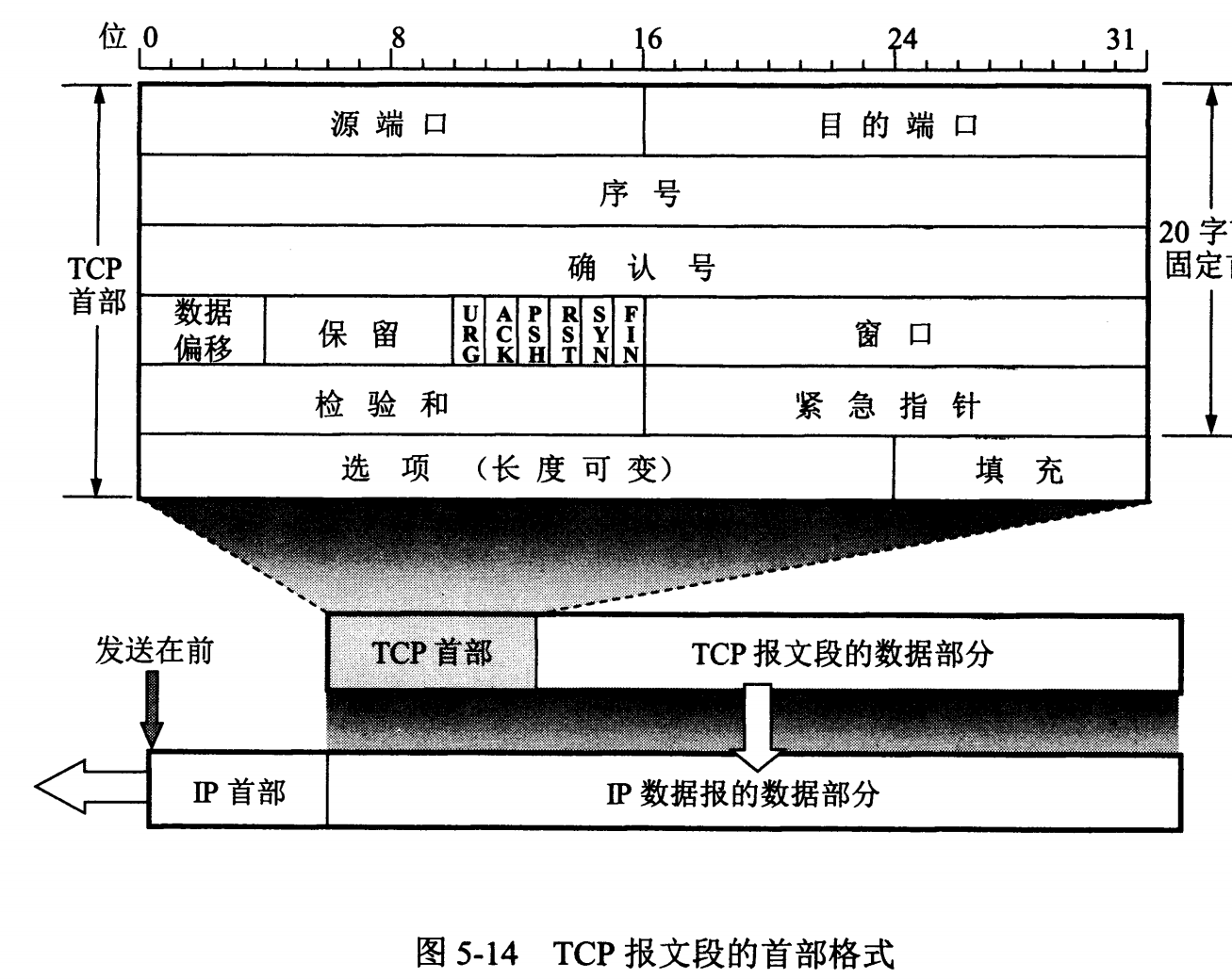

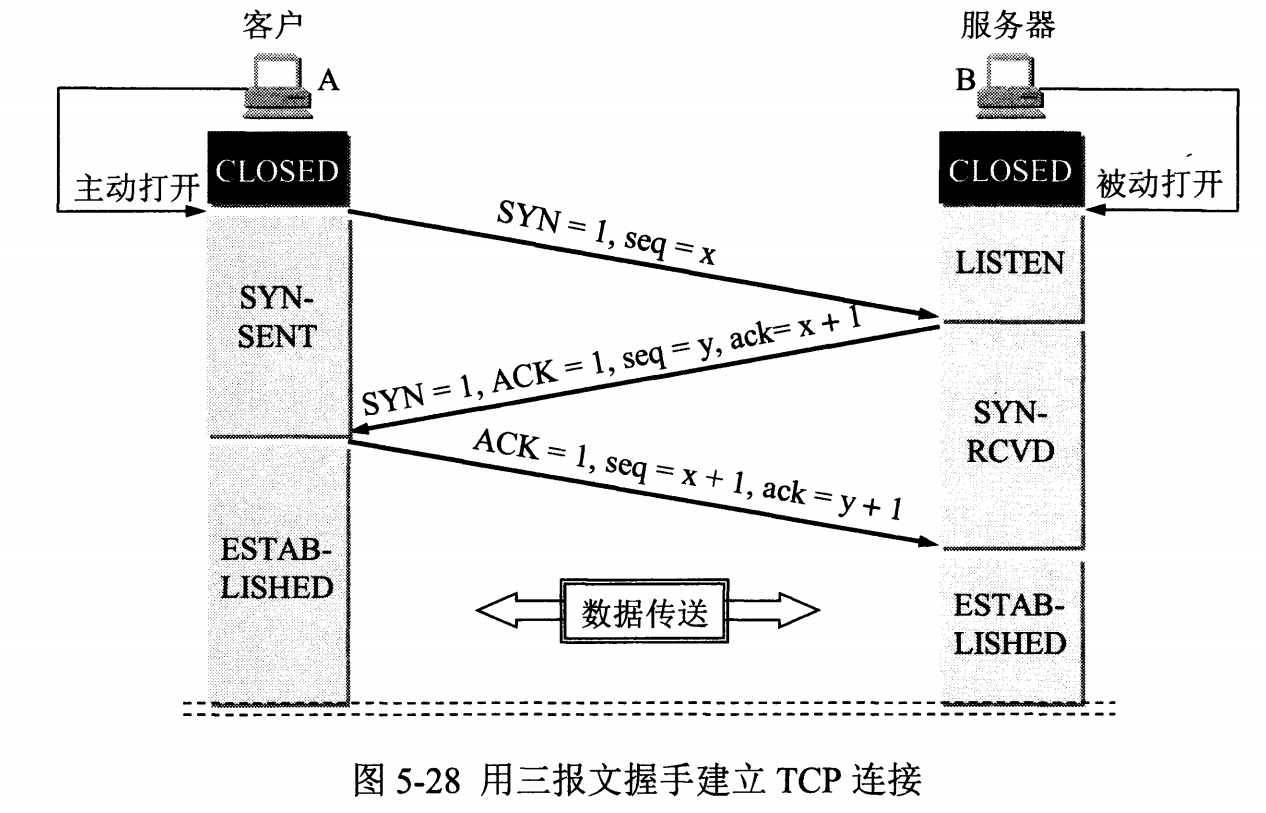

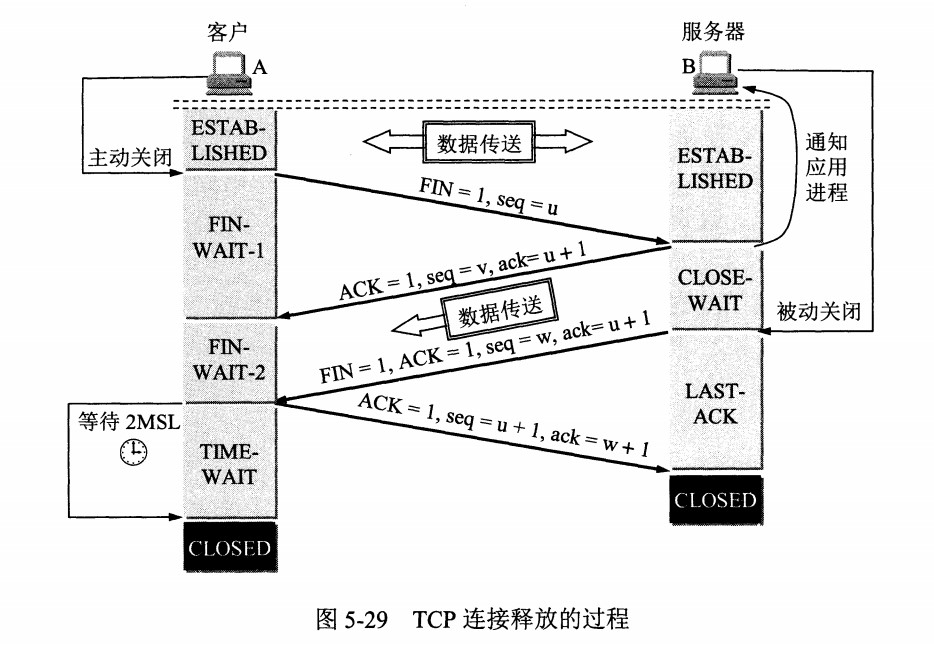

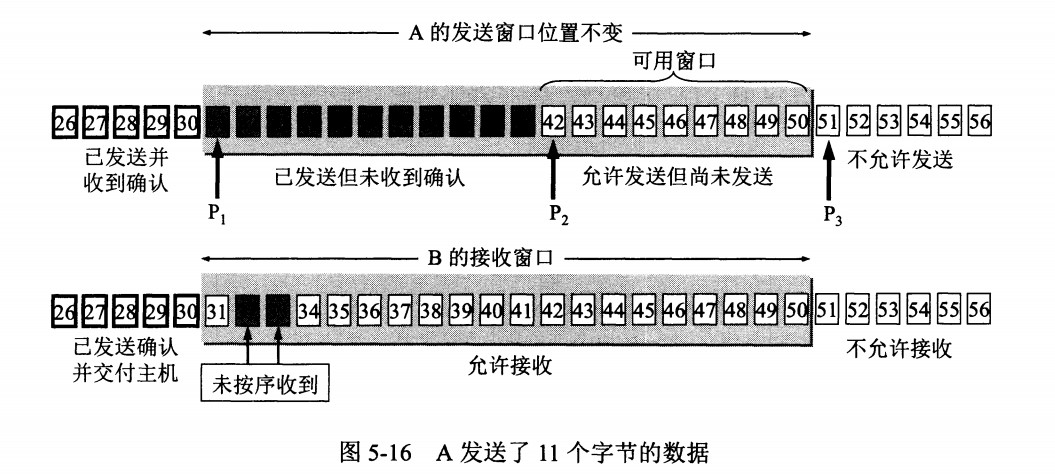

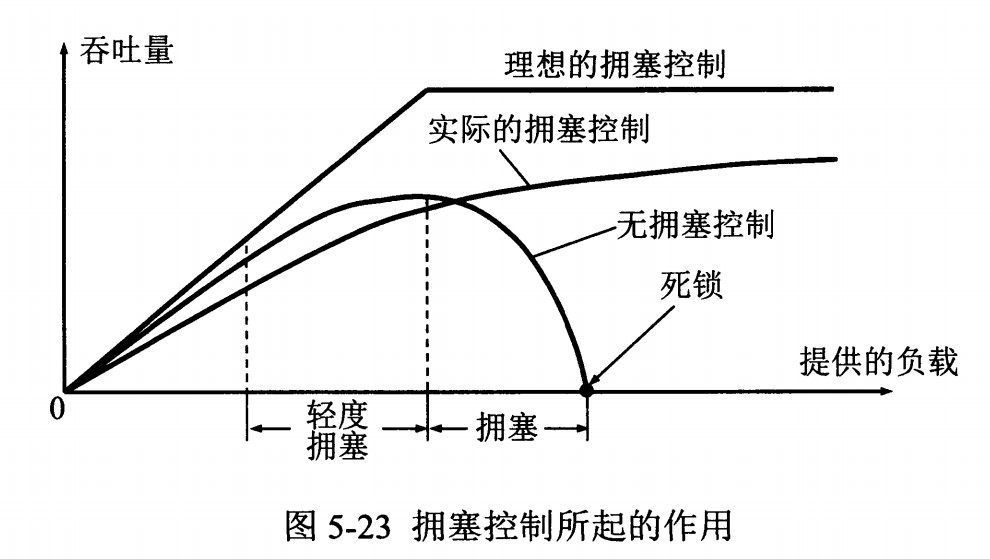

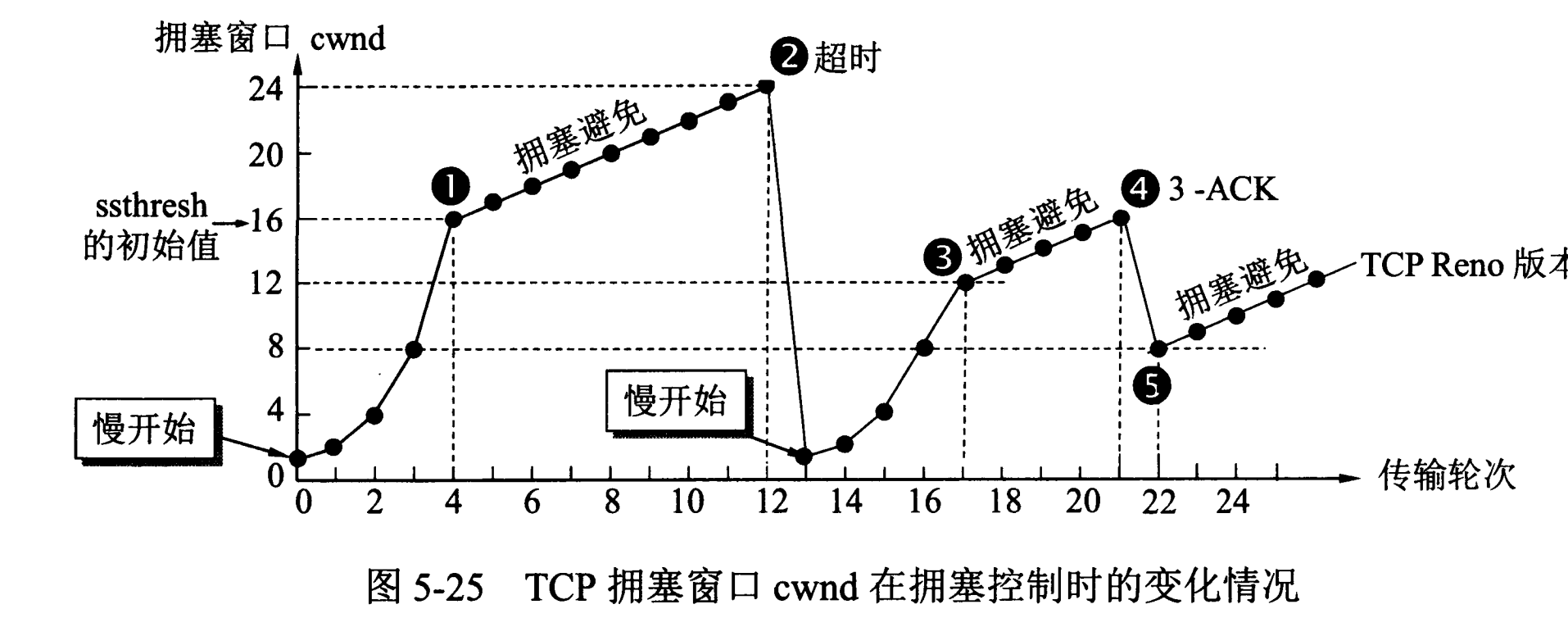

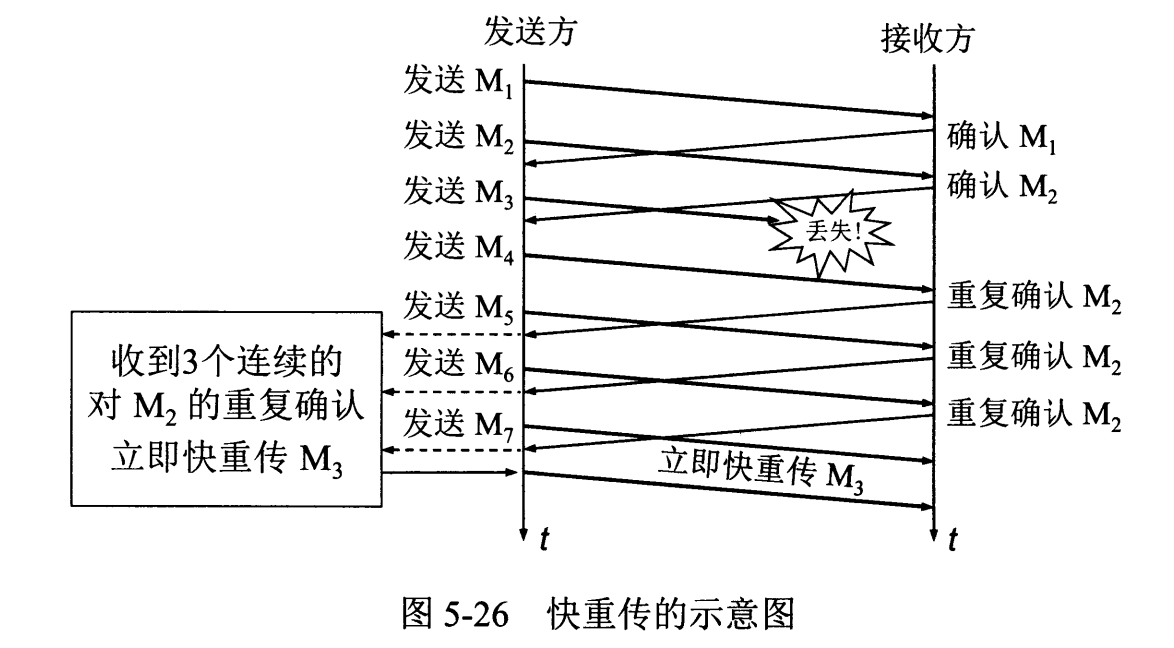

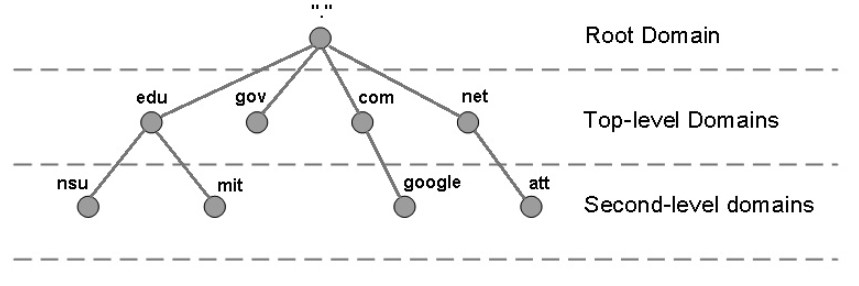

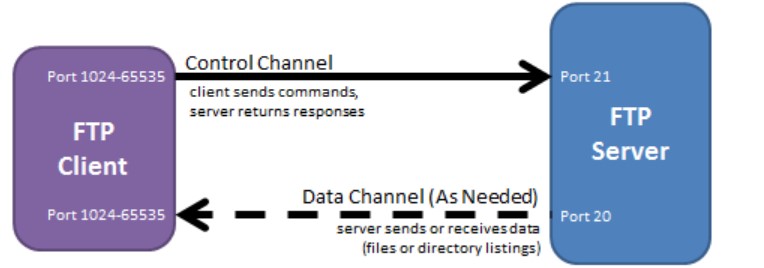

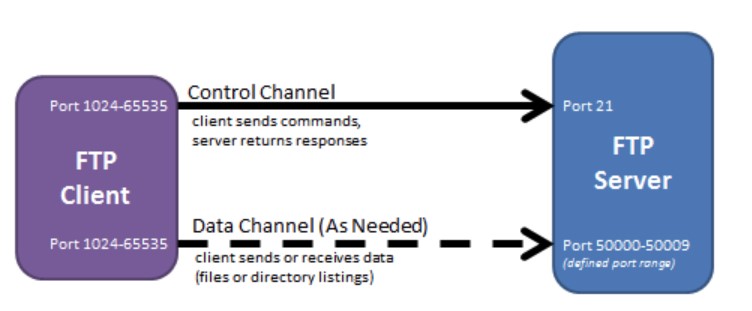

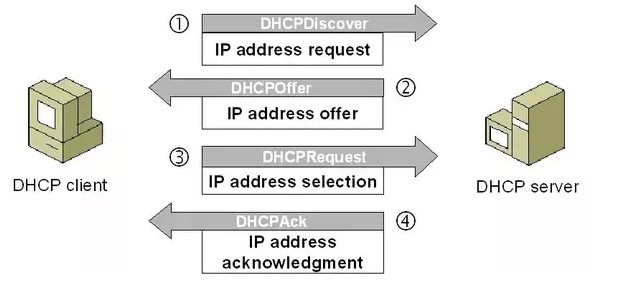

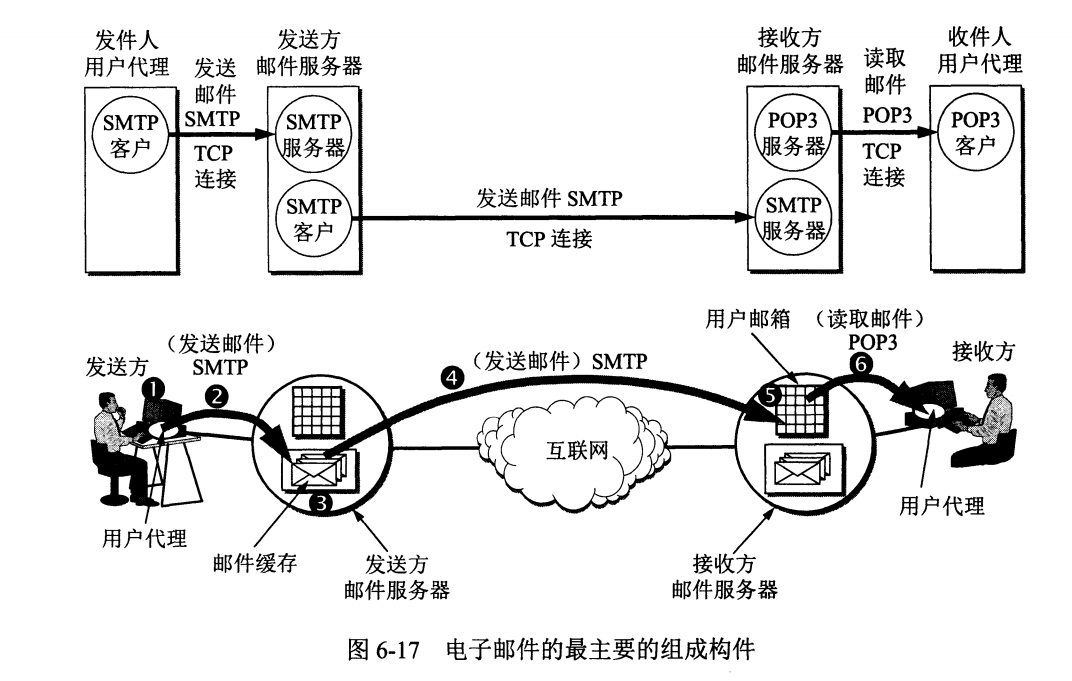

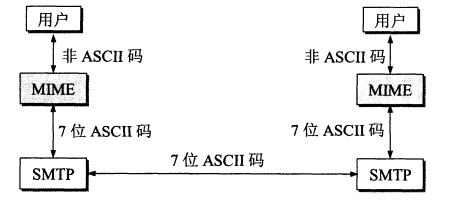

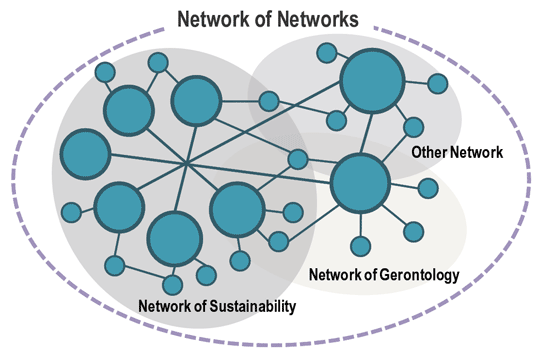

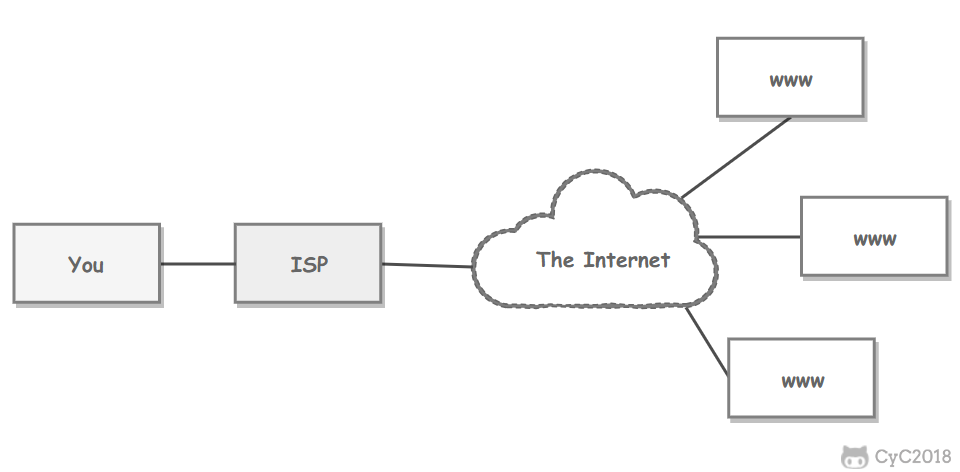

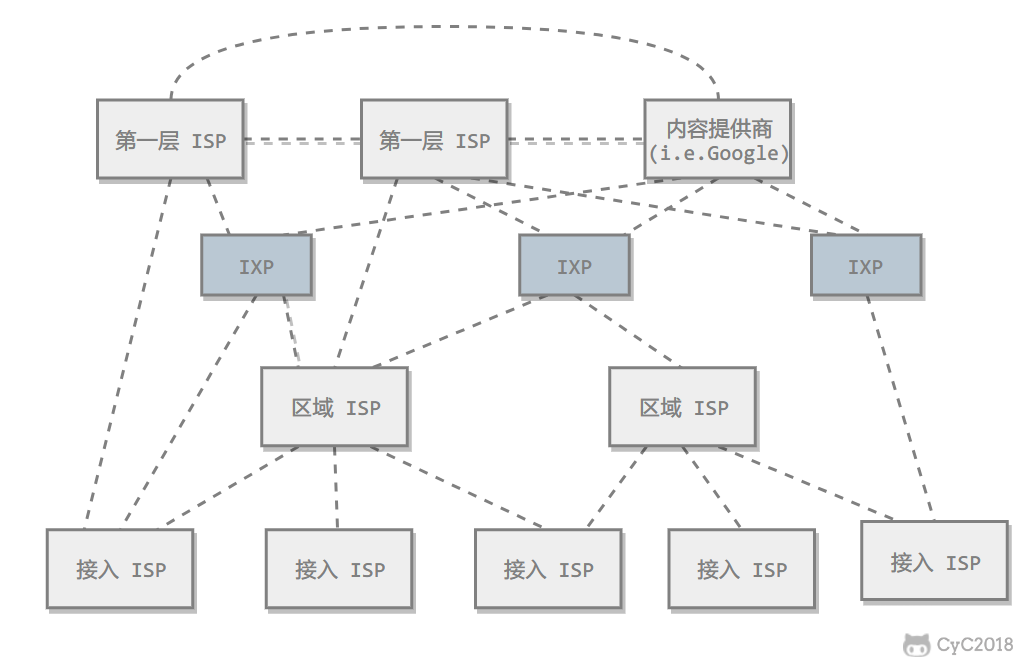

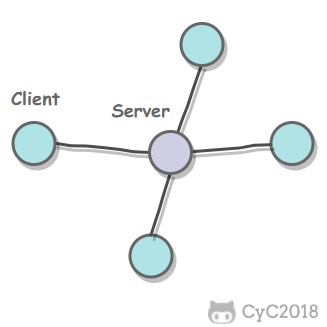


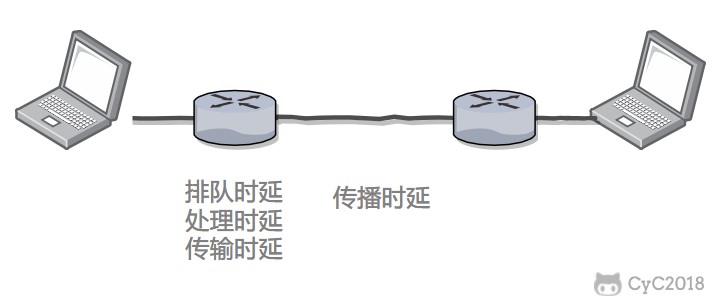

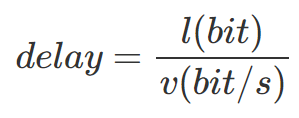

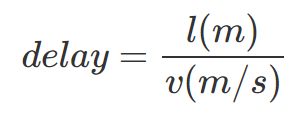

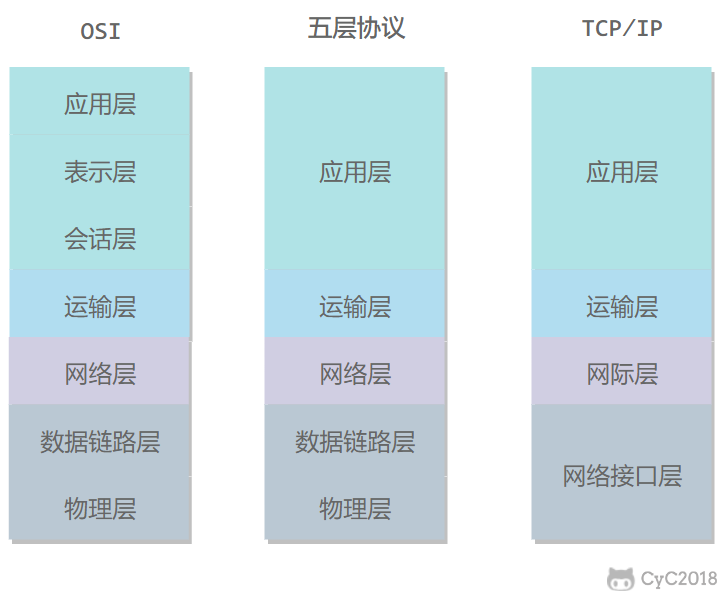



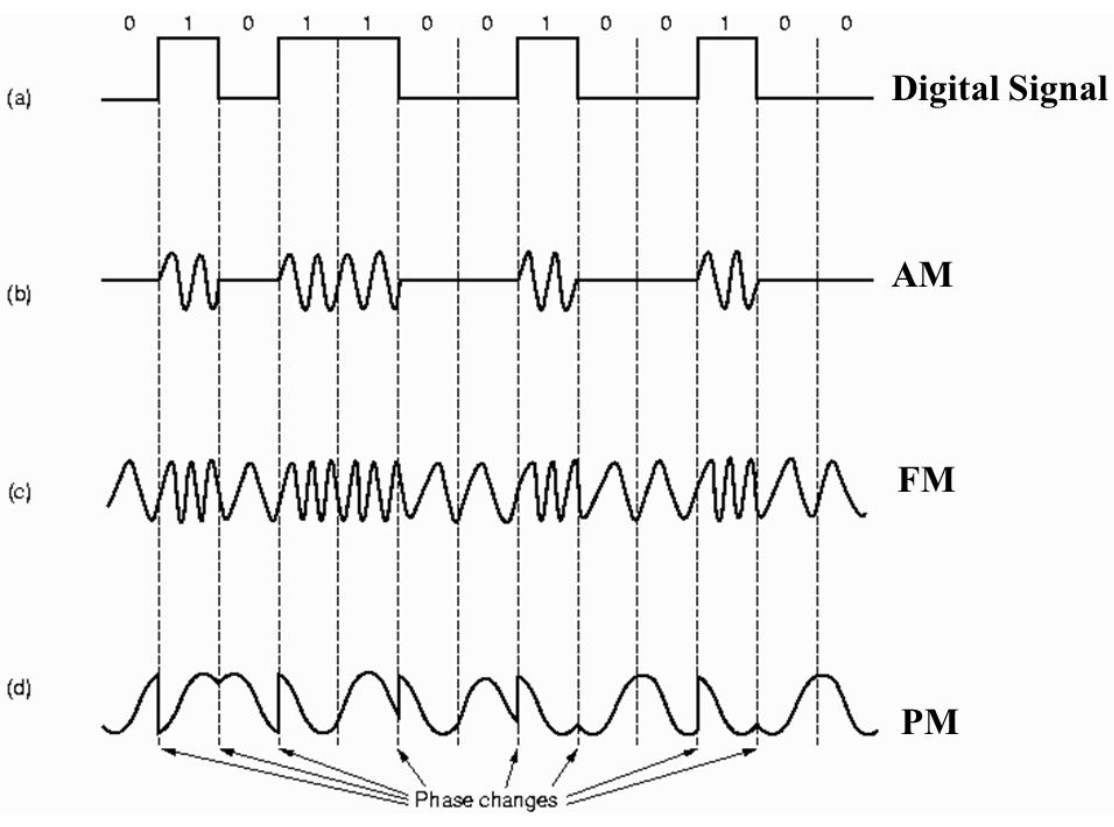


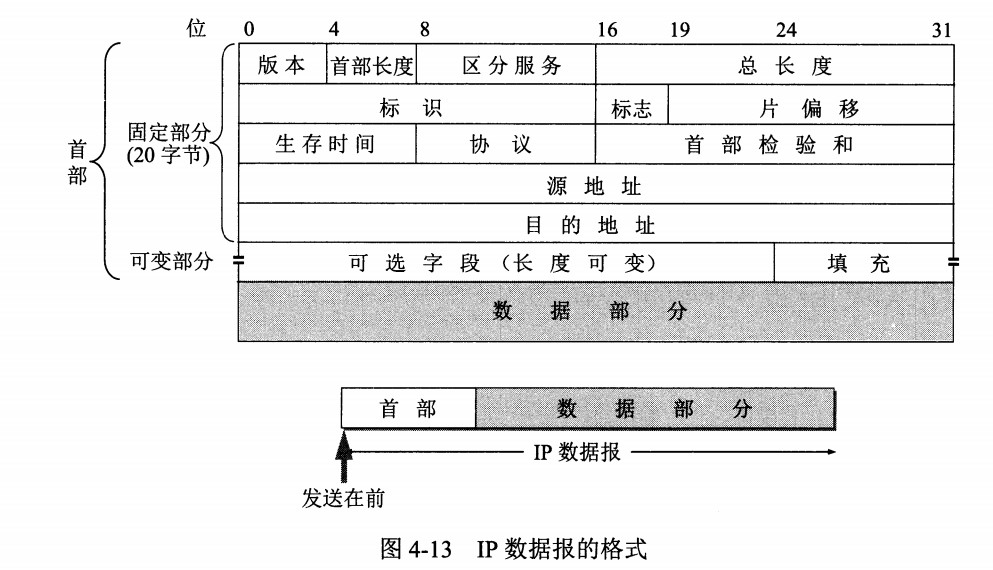

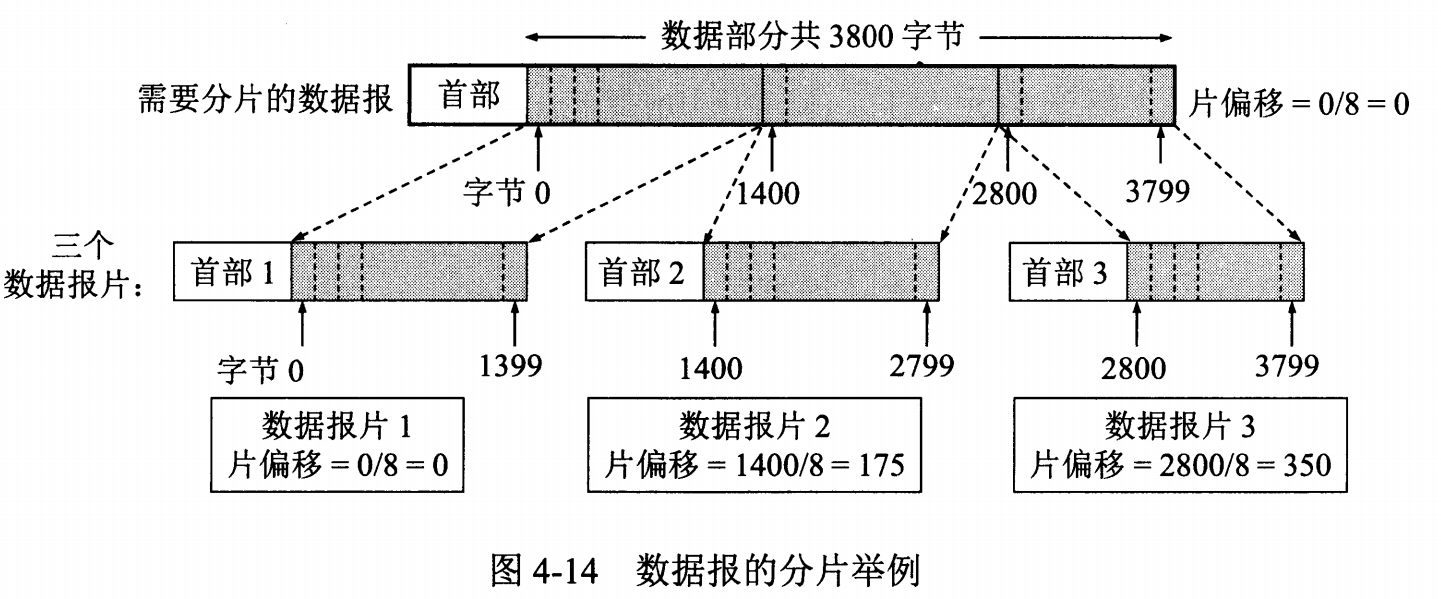

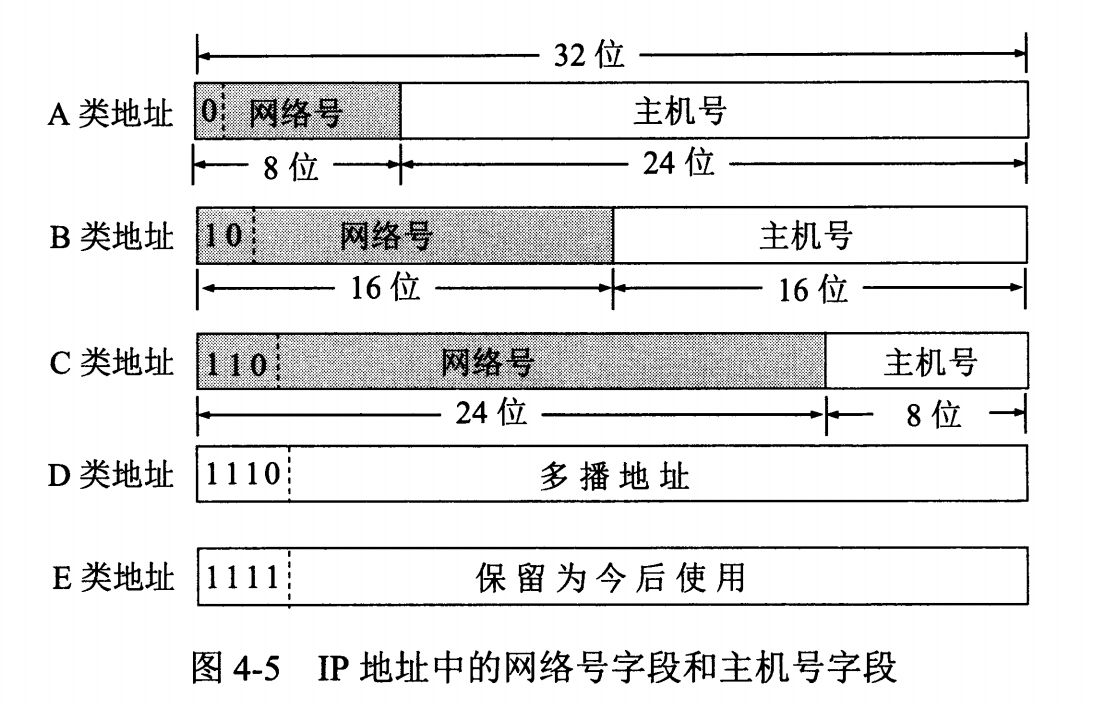

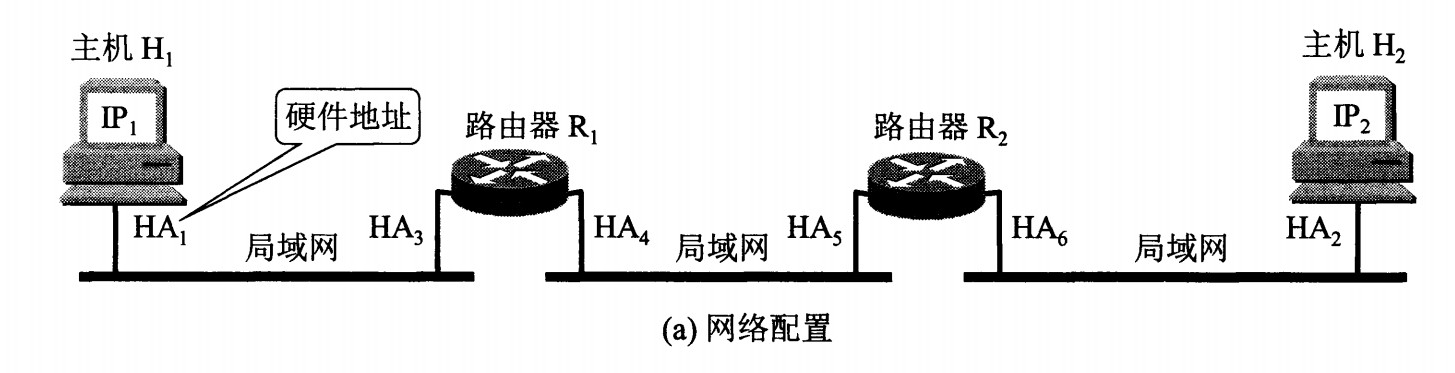

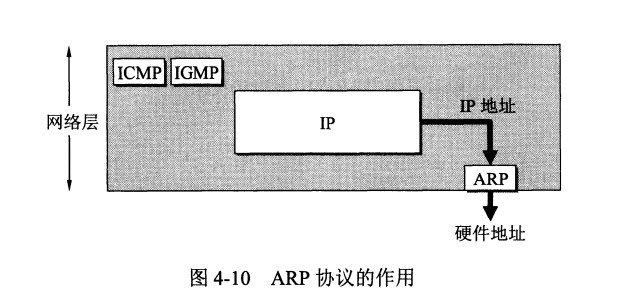



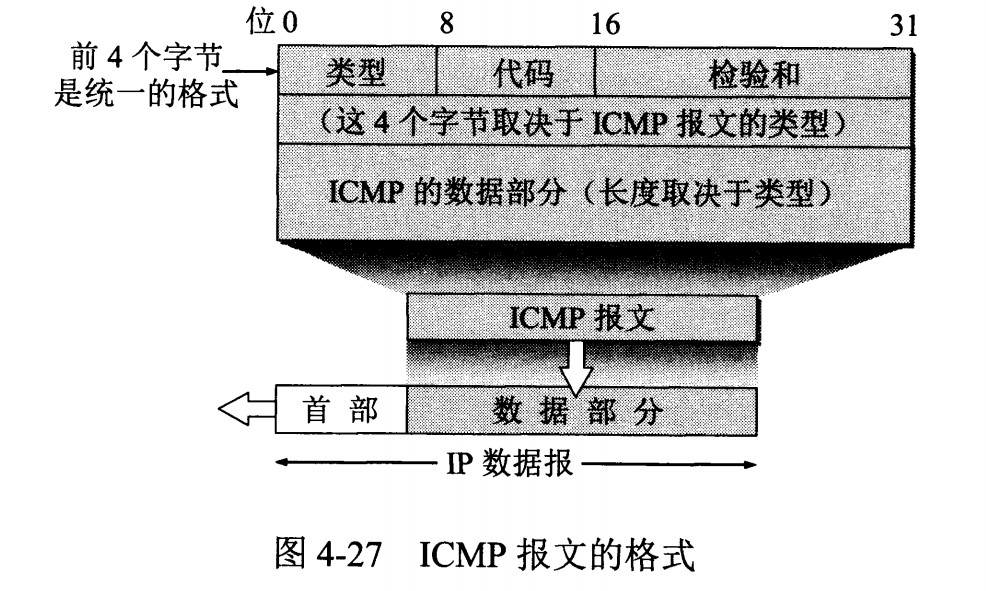

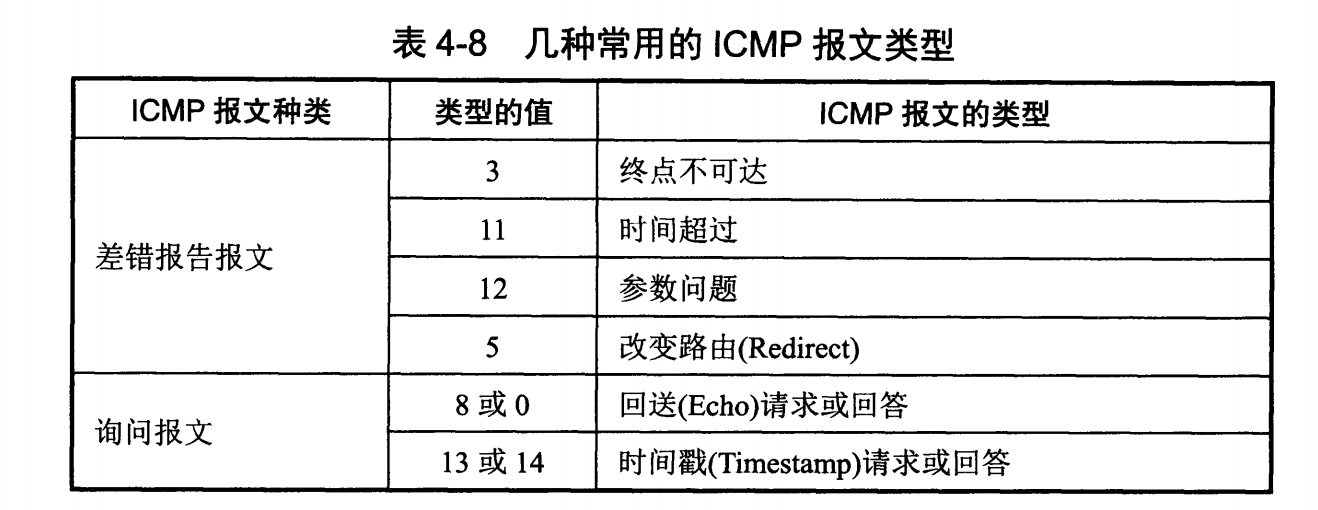





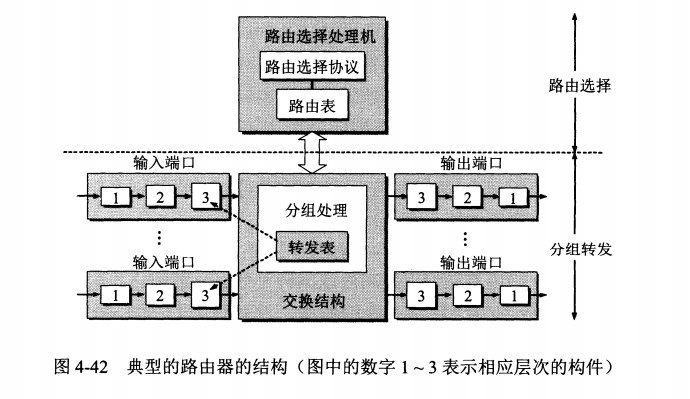

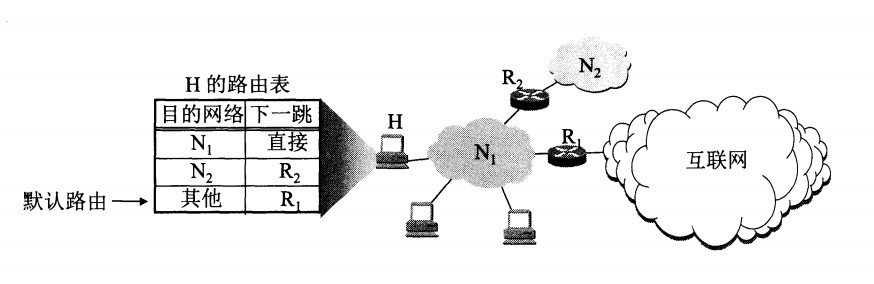

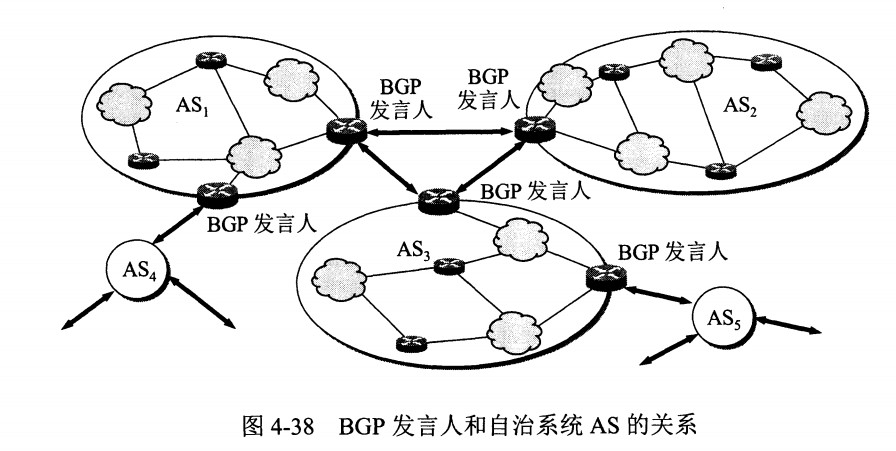



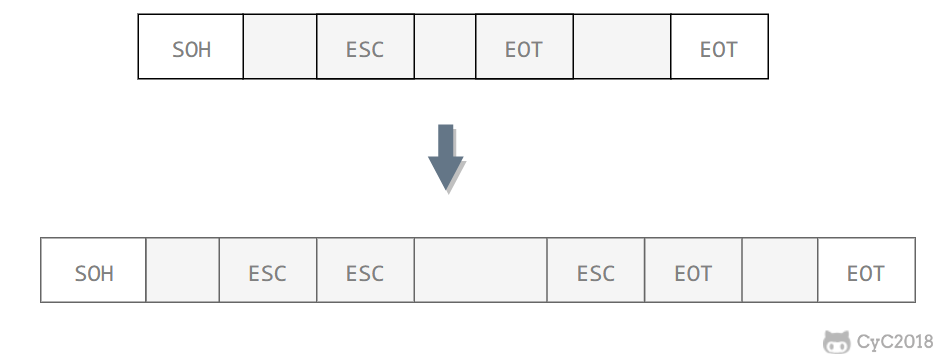


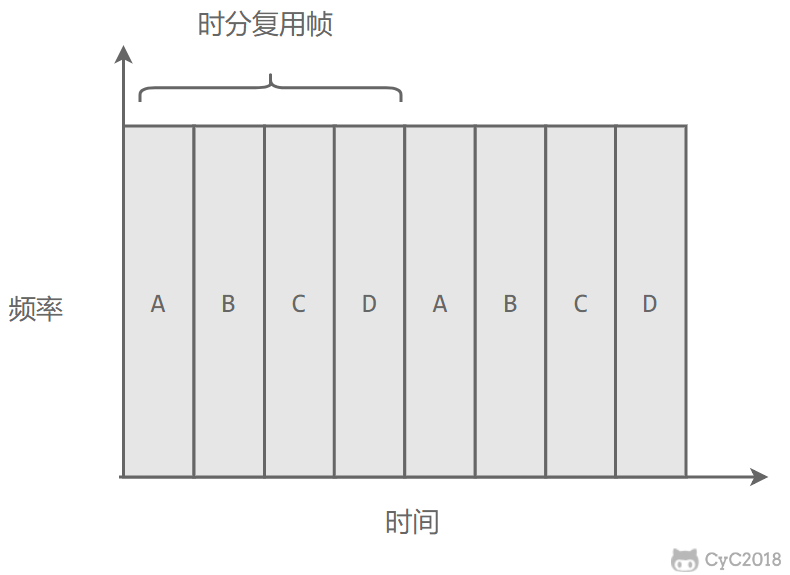



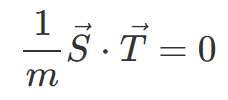

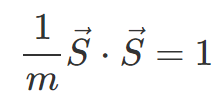

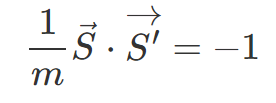


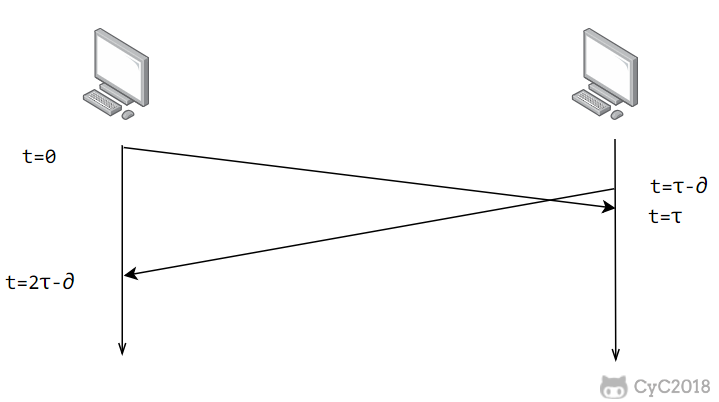





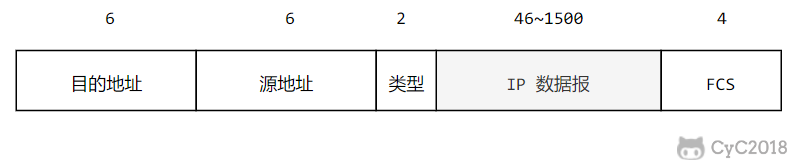

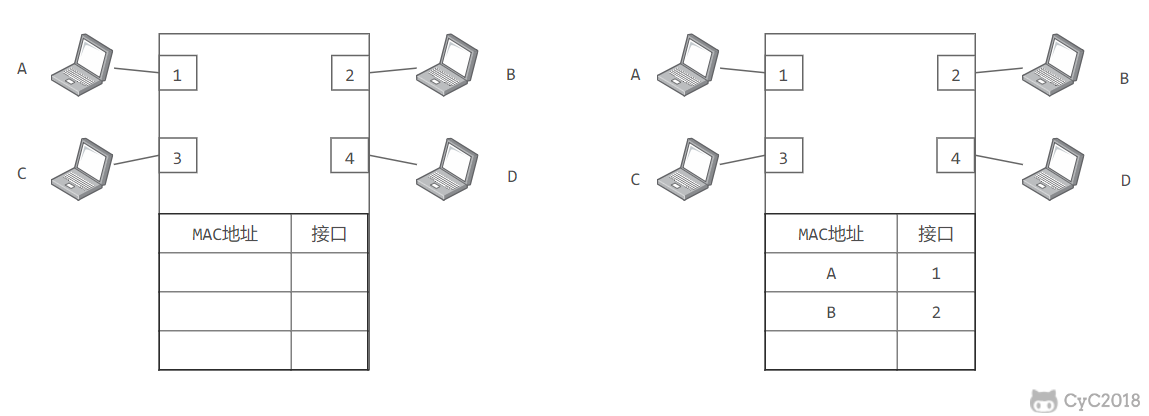

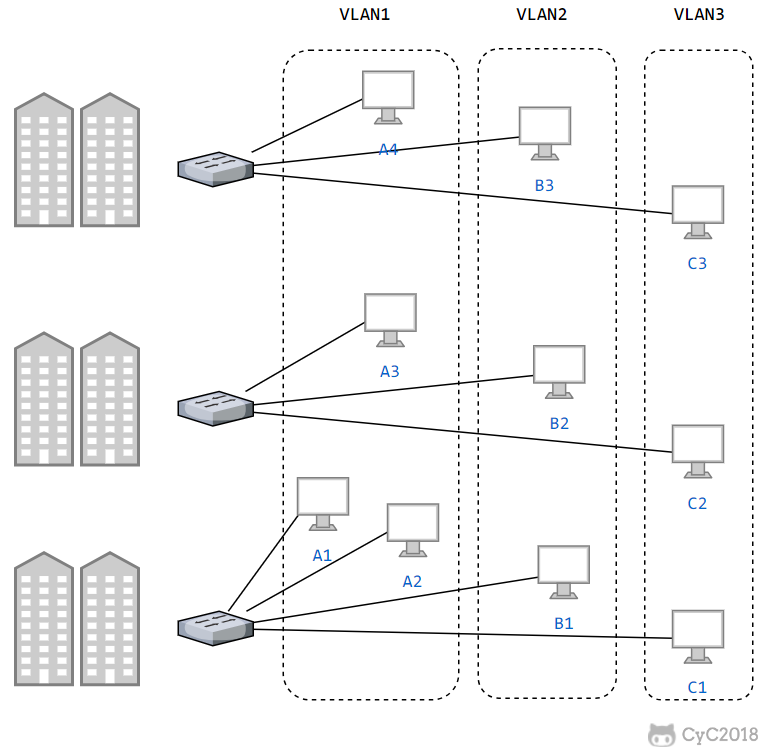

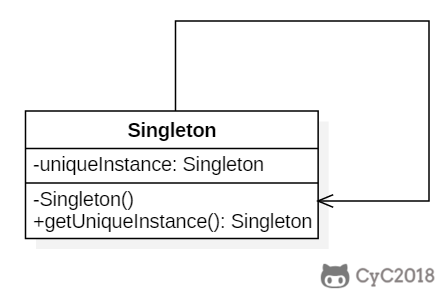

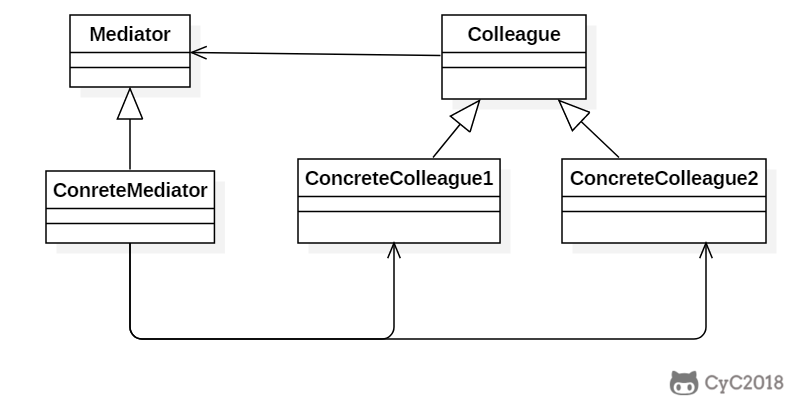







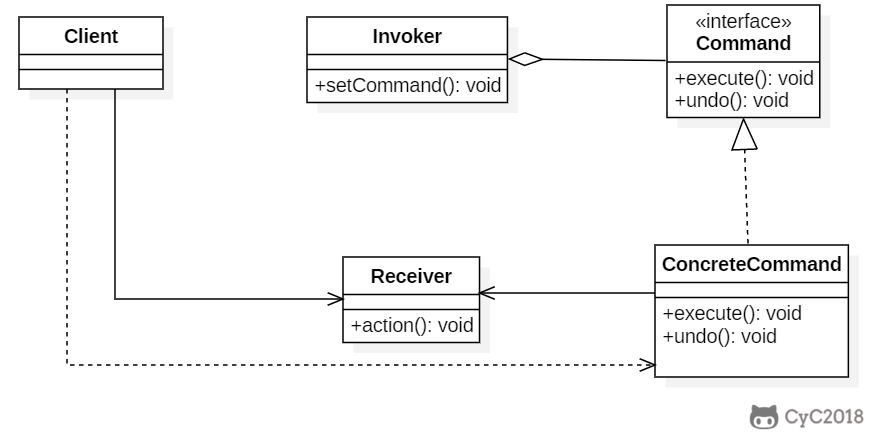

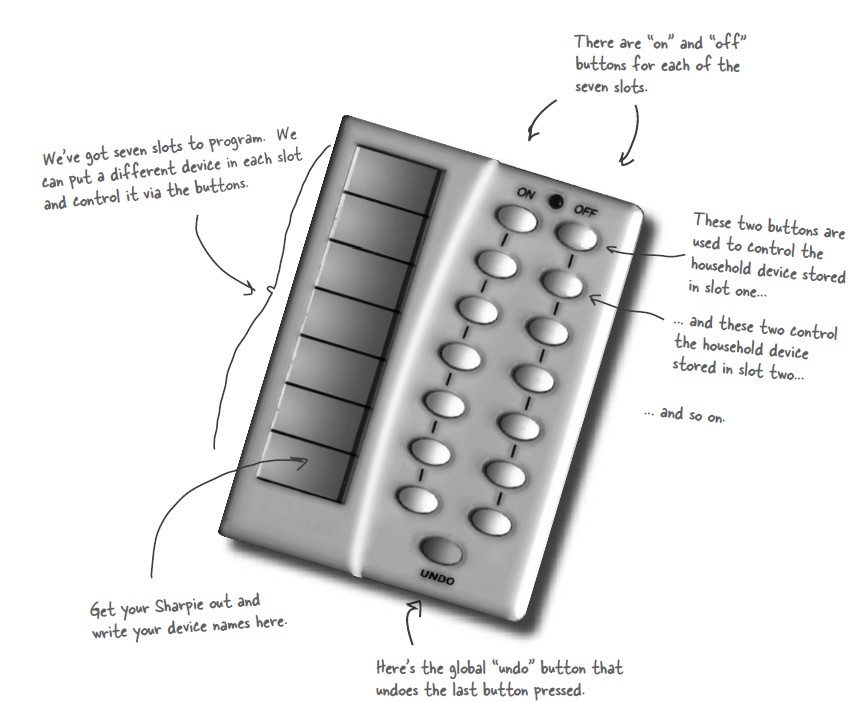

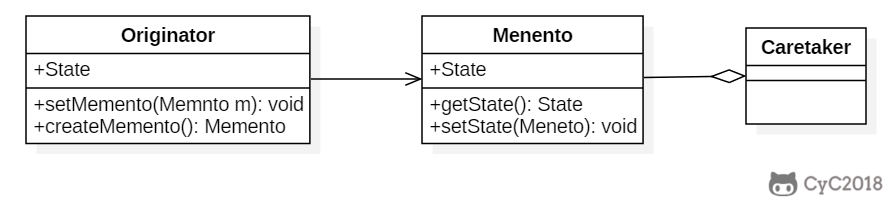

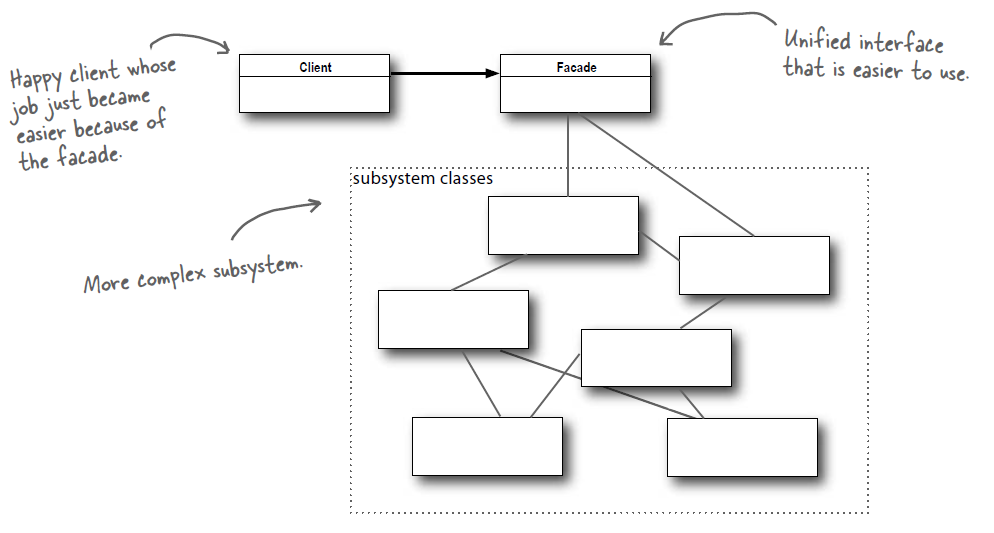

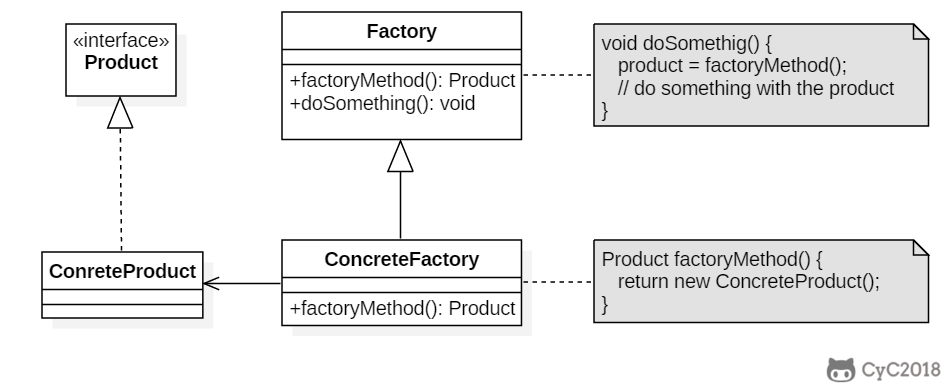

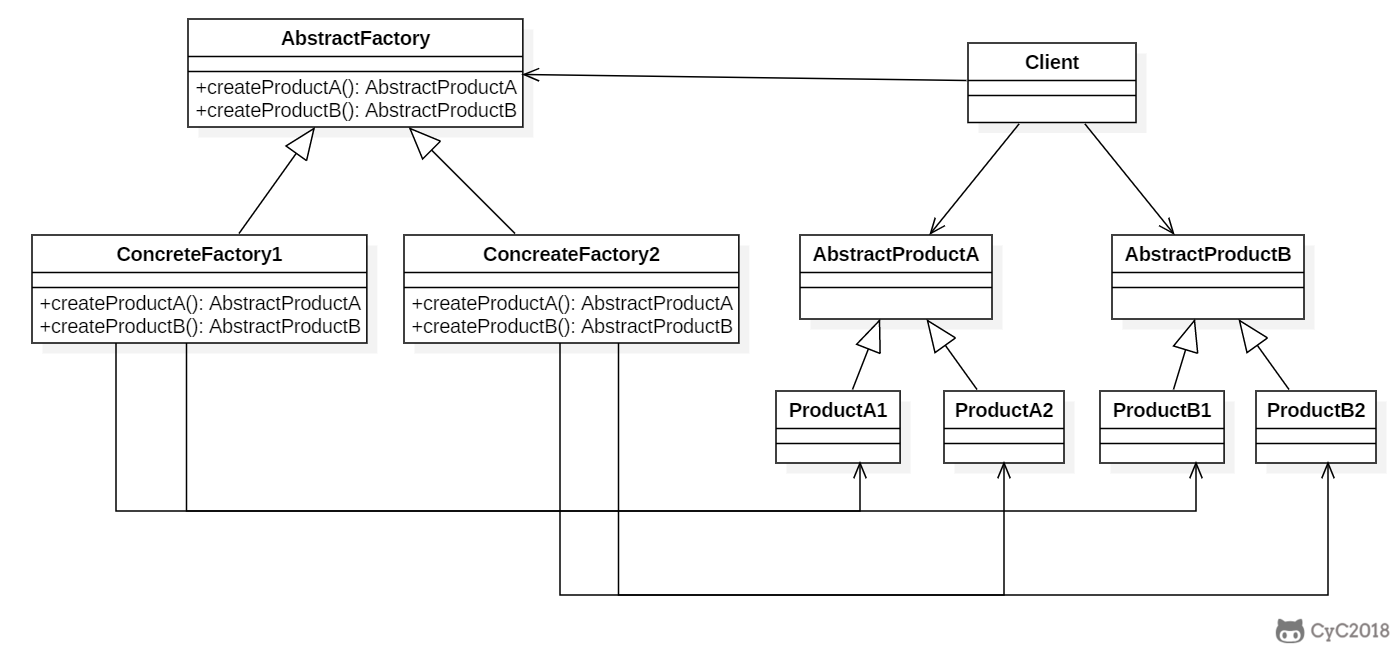

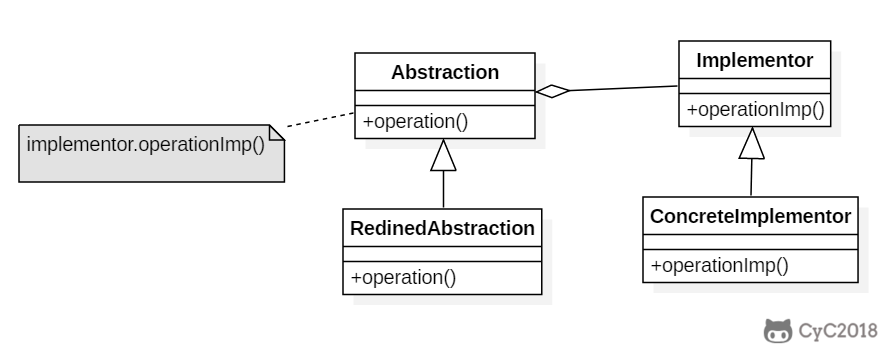

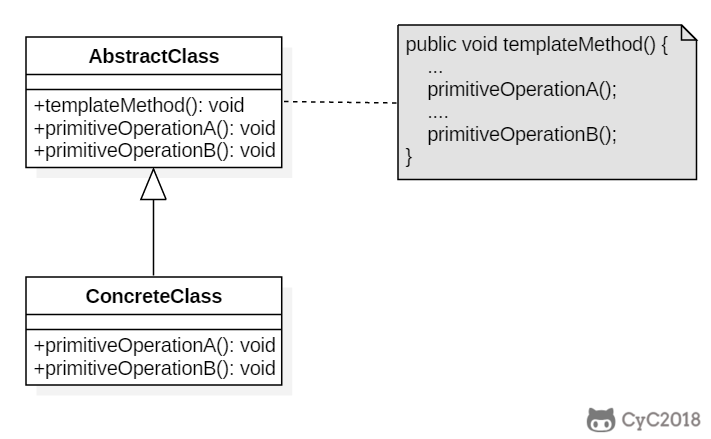

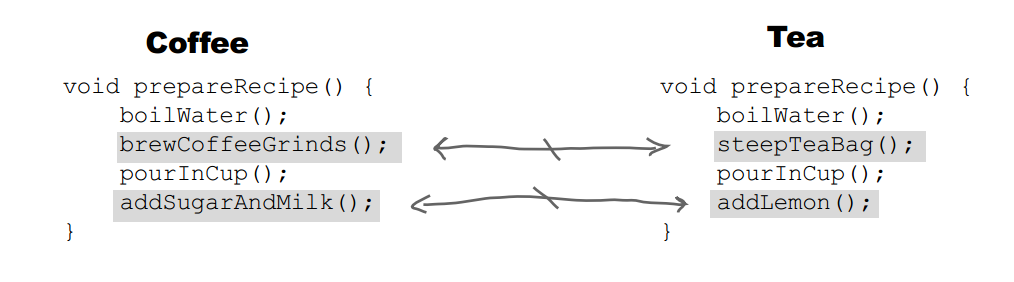

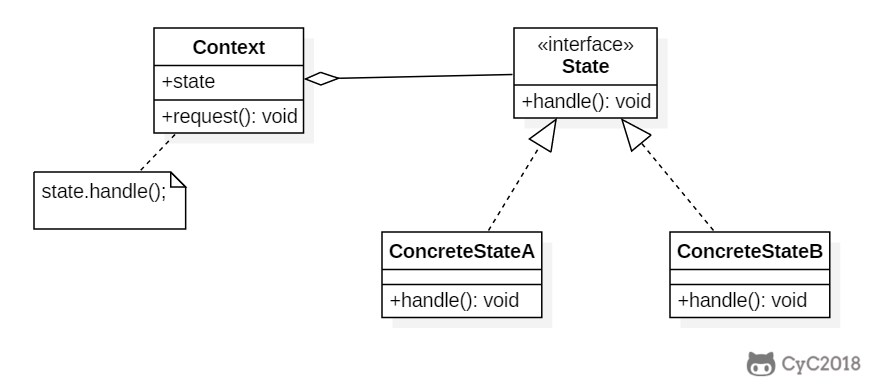



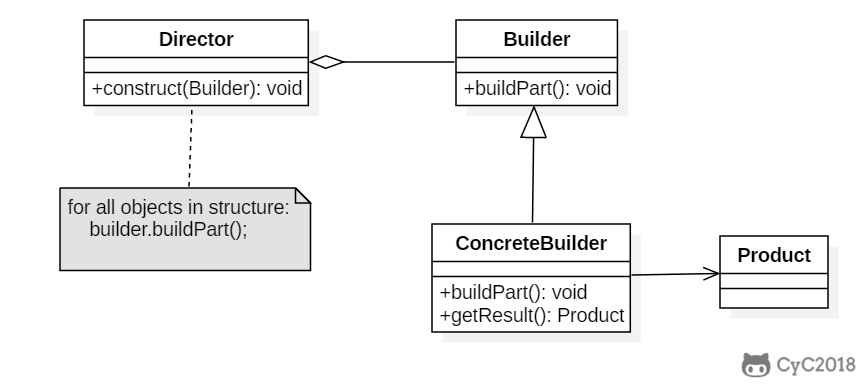

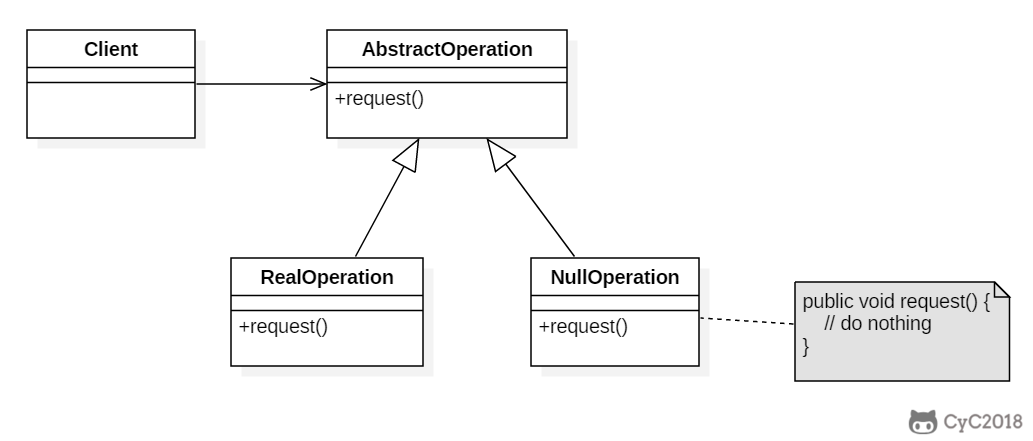

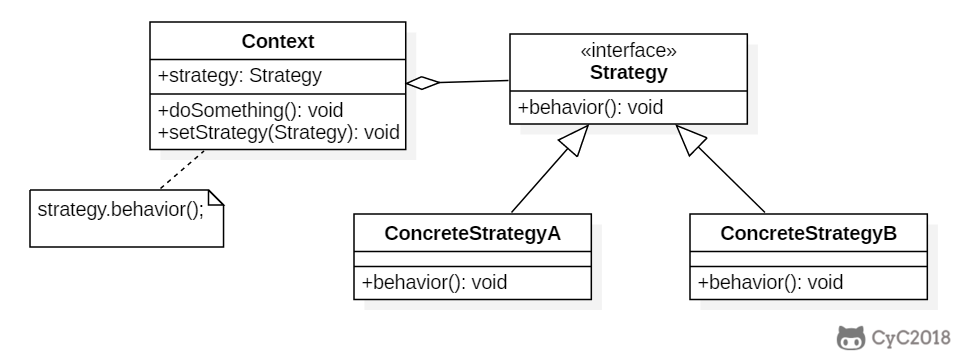

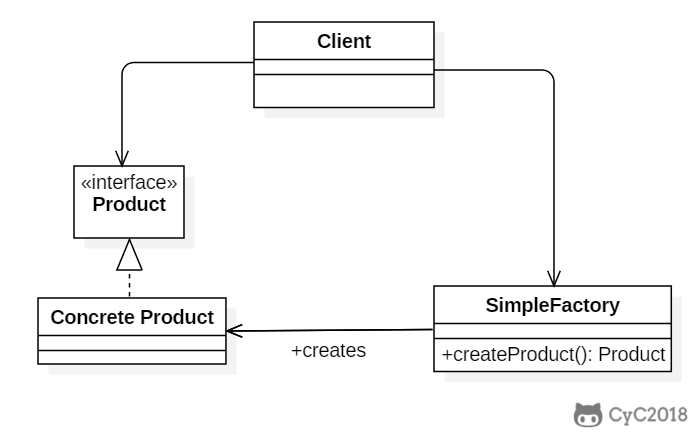

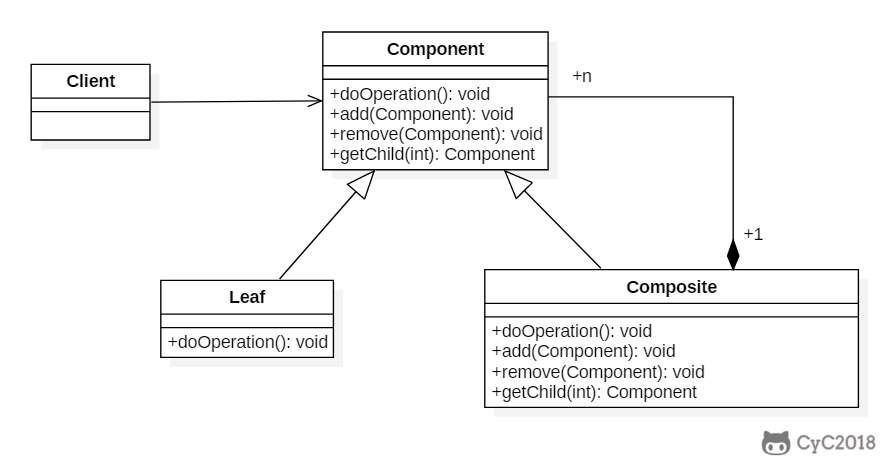

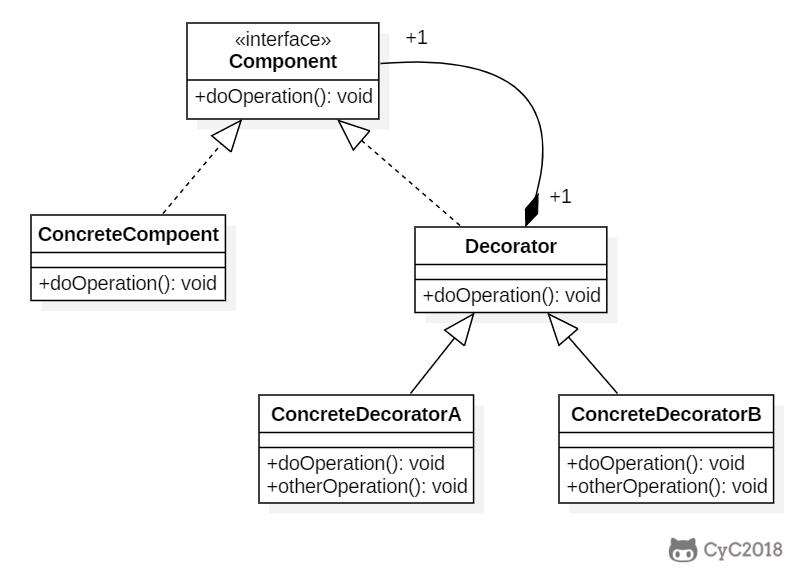

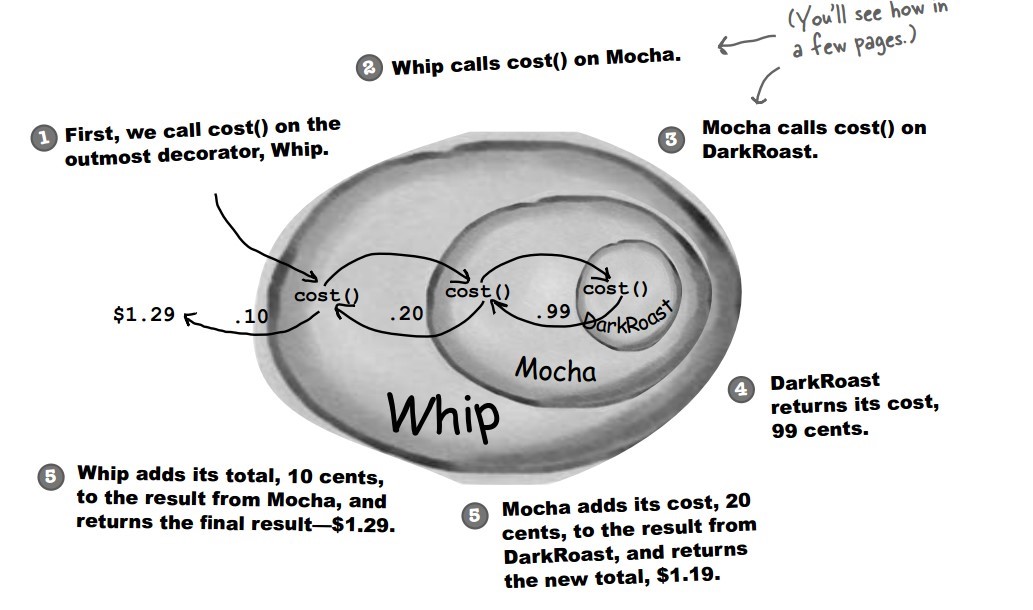

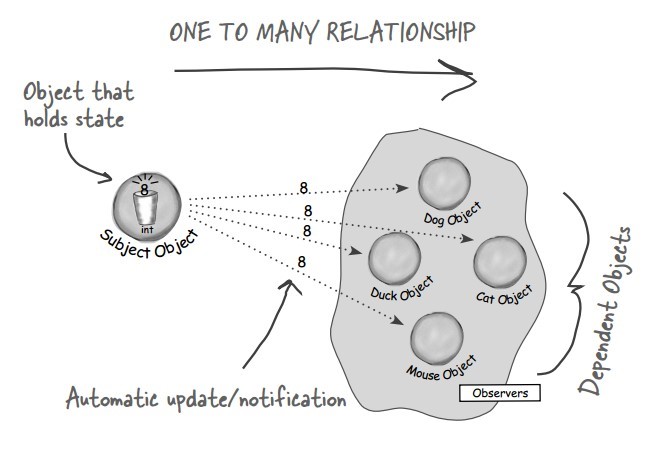

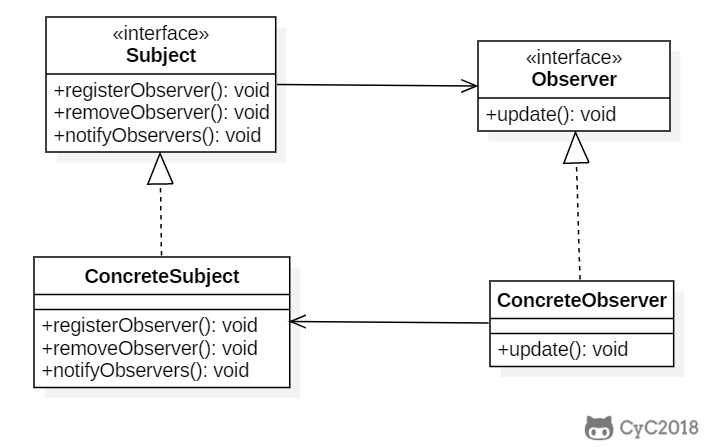

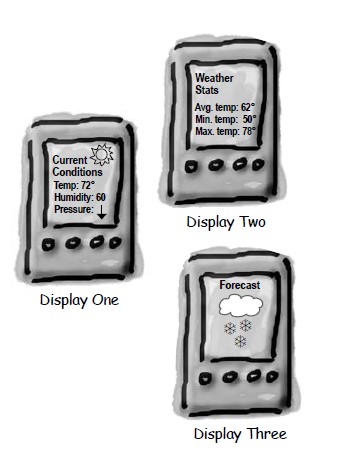

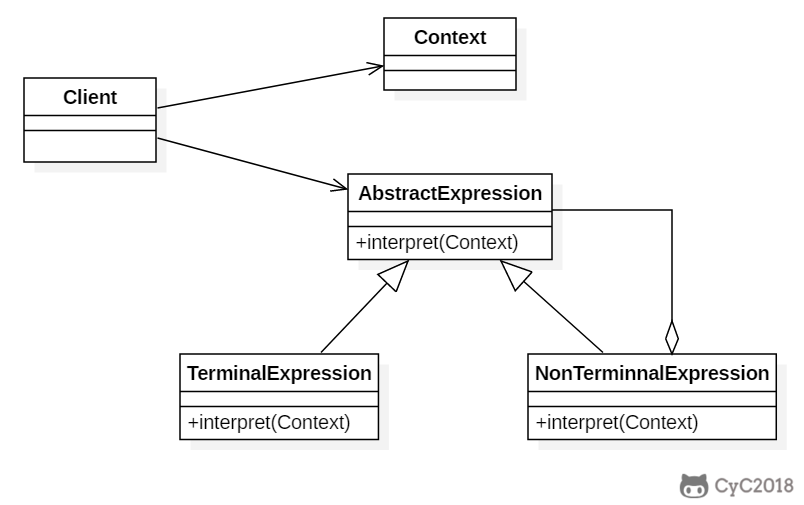

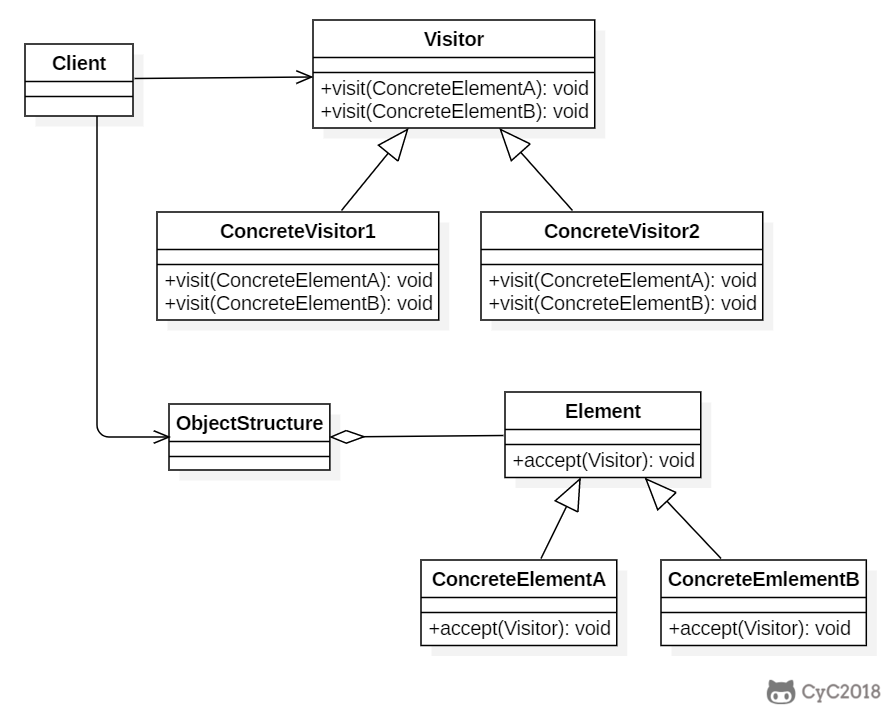

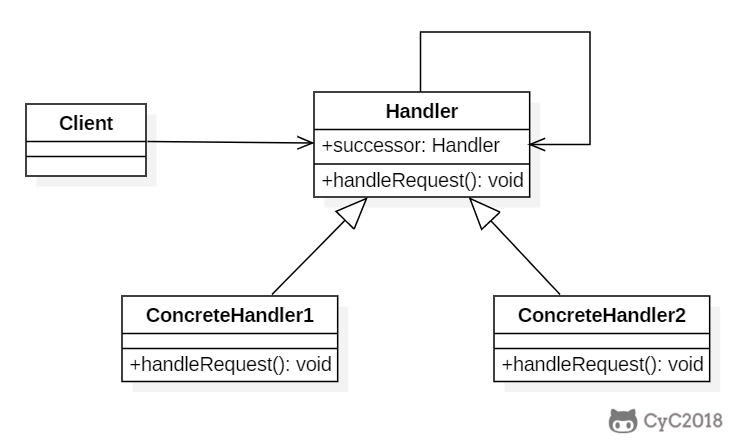

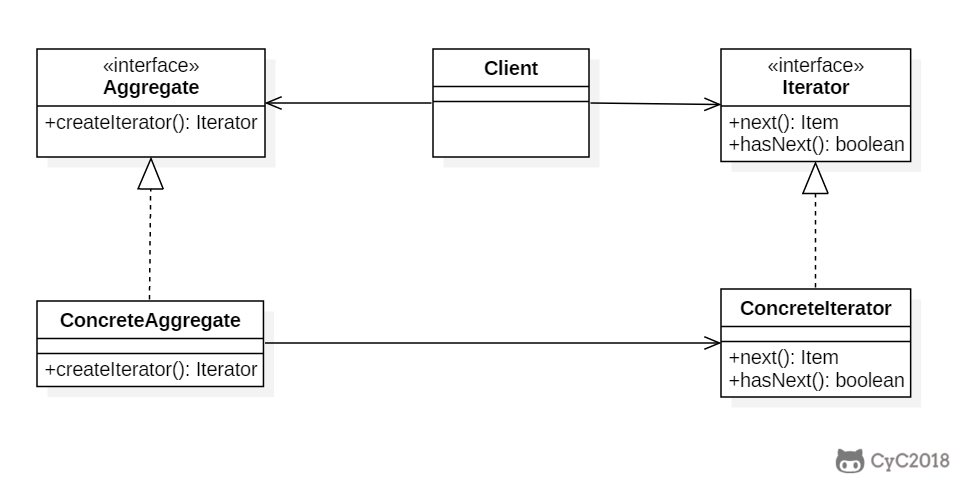

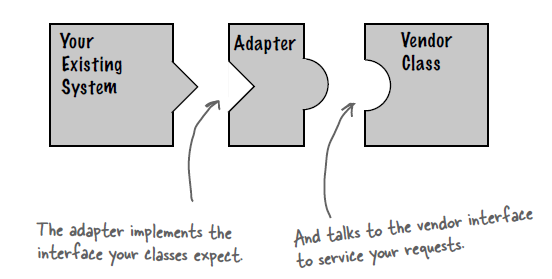



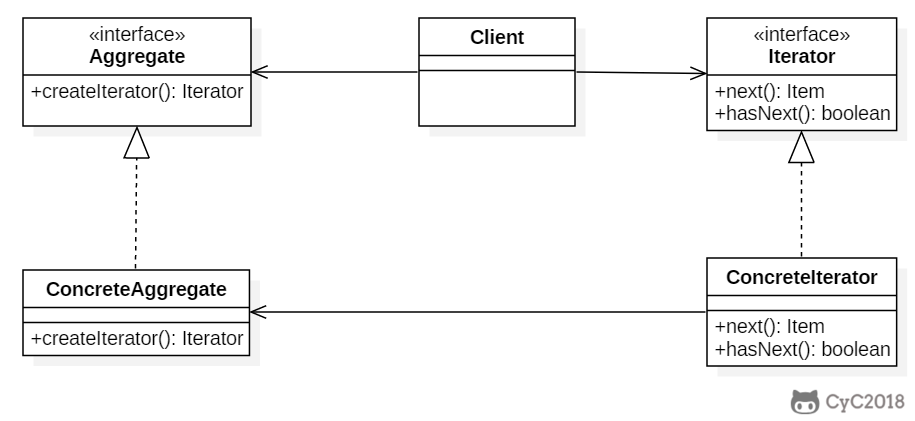



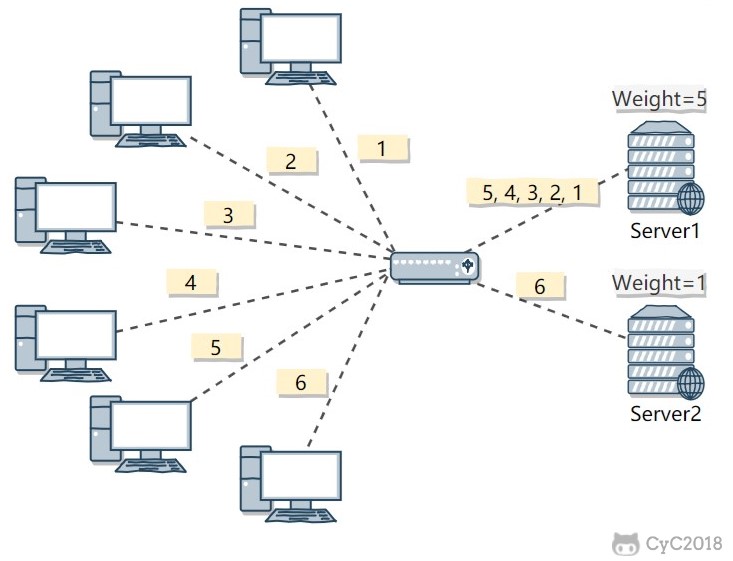



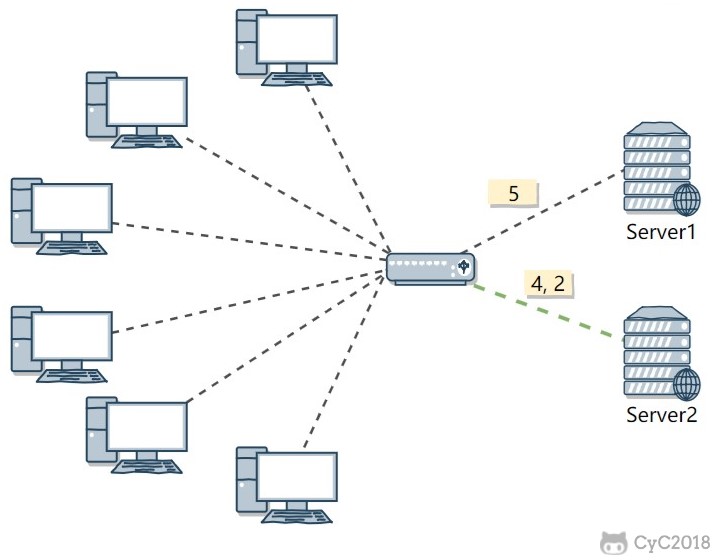

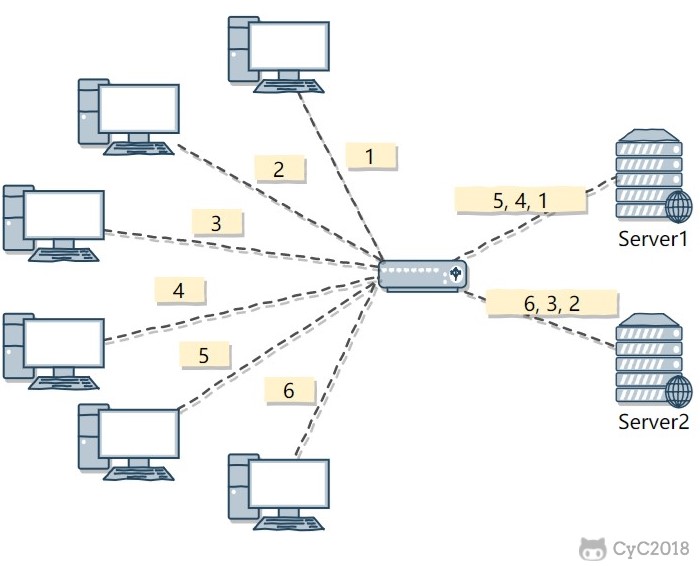

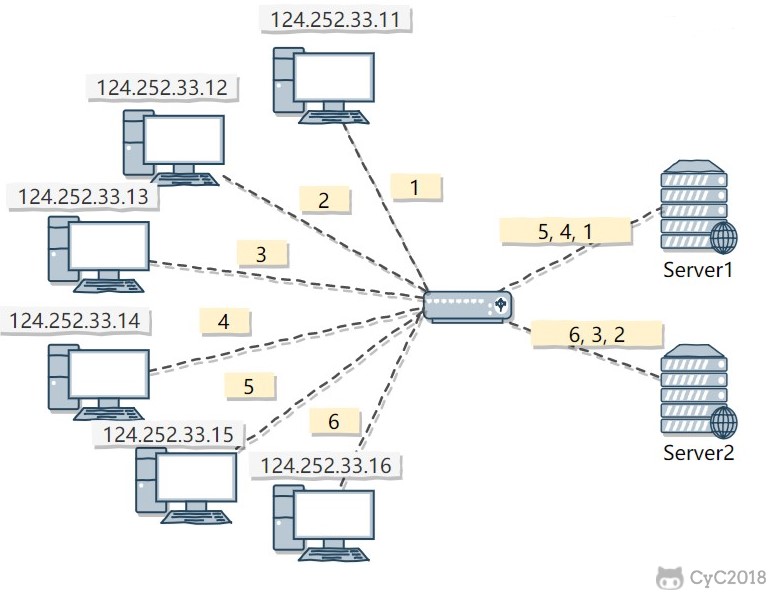

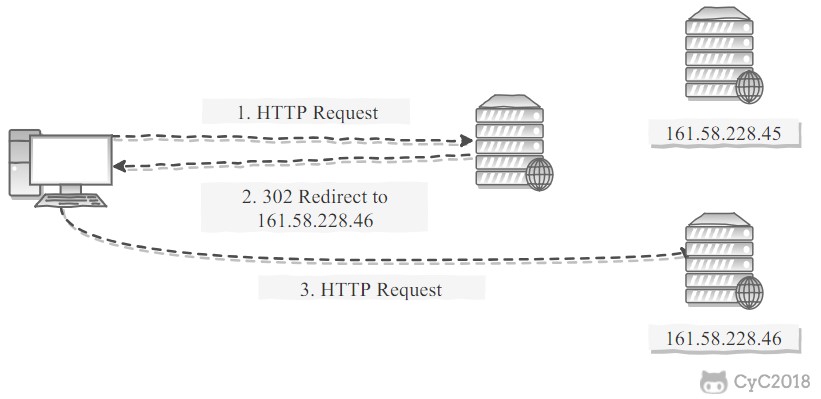



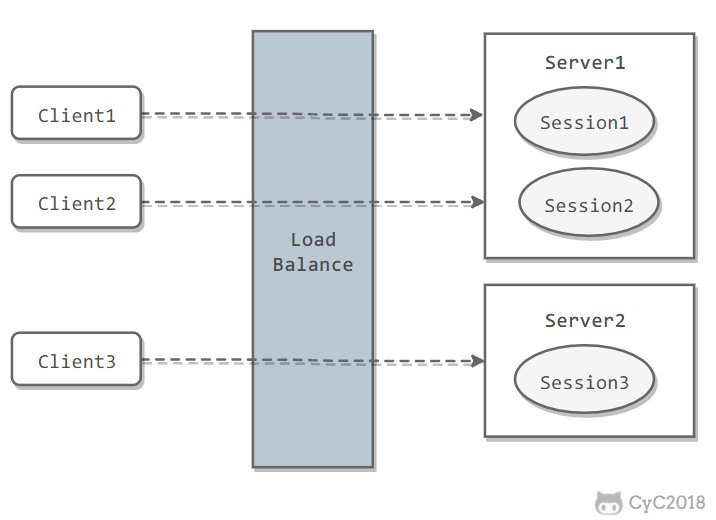

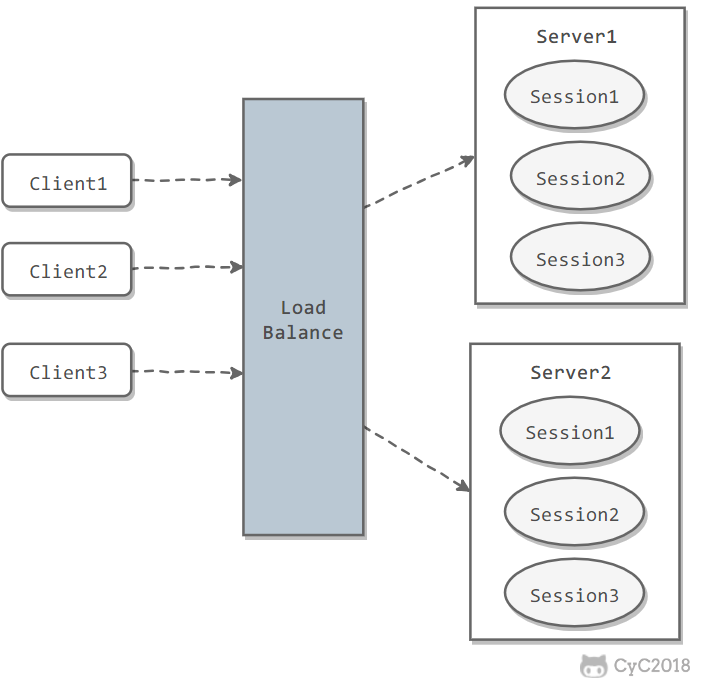

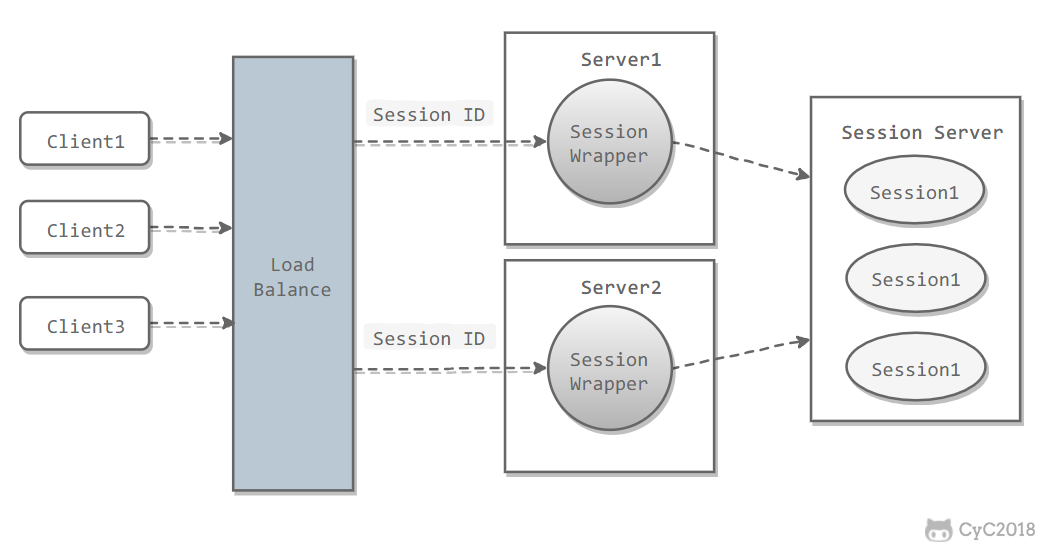

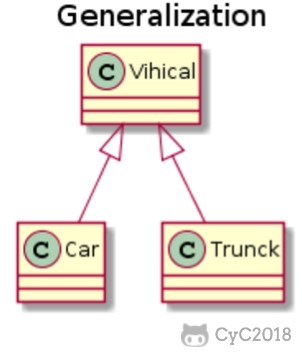

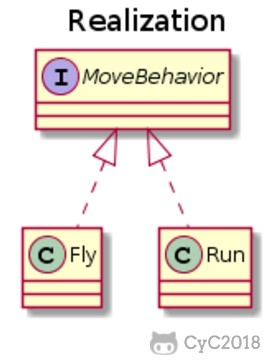

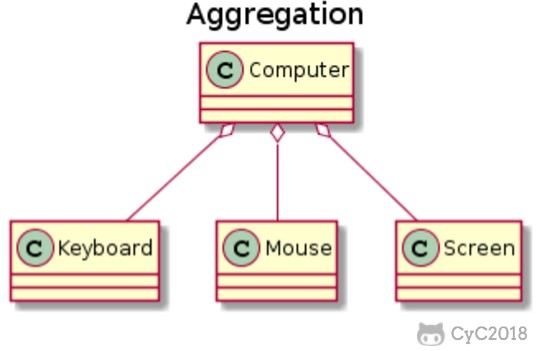





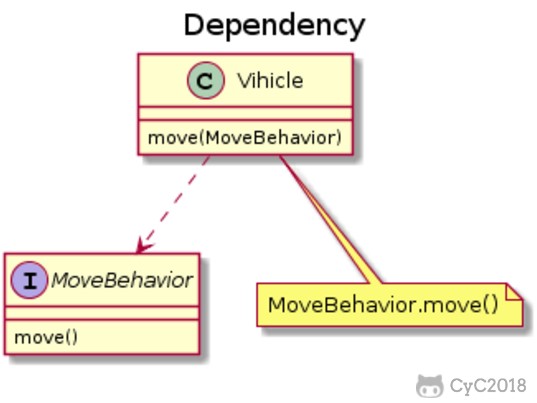

 +
+ 
{kind=link}